Iris数据集可视化
- Fisher数据可视化
- 去掉Species特征中的’Iris-'字符
- Seaborn可视化
- palette调色板
- sns初始化,set()设置主题、调色板
- relplot
- hue
- 联合分布 jointplot
- displot
- boxplot
- violinplot
- pairplot
Fisher数据可视化
import pandas as pd
df_Iris = pd.read_csv('Iris1.csv')
df_Iris.Species.value_counts()

去掉Species特征中的’Iris-'字符
df_Iris['Species']= df_Iris.Species.apply(lambda x: x.split('-')[1])
df_Iris.Species.value_counts()

Seaborn可视化
palette调色板
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
current_palette = sns.color_palette()
print("current_palette")
sns.palplot(current_palette)
#其它颜色风格
#风格内容:Accent,Blues,BrBG等等
print("Accent")
sns.palplot(sns.color_palette('Accent',8))
#这里颜色风格为Accent
#颜色色块个数为8个
#风格颜色转换(不是所有颜色都可以反转):Blues/Blues_r
#分组颜色设置 -'Paried'
print("Paired")
sns.palplot(sns.color_palette('Paired', 16))
sns初始化,set()设置主题、调色板
# styles = ["white", "dark", "whitegrid", "darkgrid", "ticks"]
# palette : deep,muted, pastel, bright, dark, colorblind
sns.set(style="dark", palette="colorblind", color_codes=True)
relplot
relplot(kind=“line”|“scatter(默认)”)
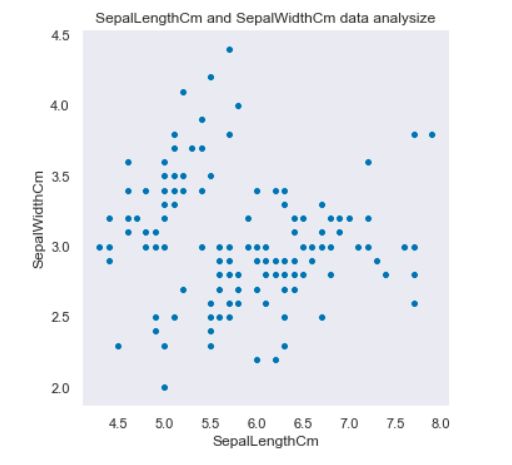
#设置散点图x轴与y轴以及data参数
sns.relplot(x='SepalLengthCm', y='SepalWidthCm', data = df_Iris)
plt.title('SepalLengthCm and SepalWidthCm data analysize')
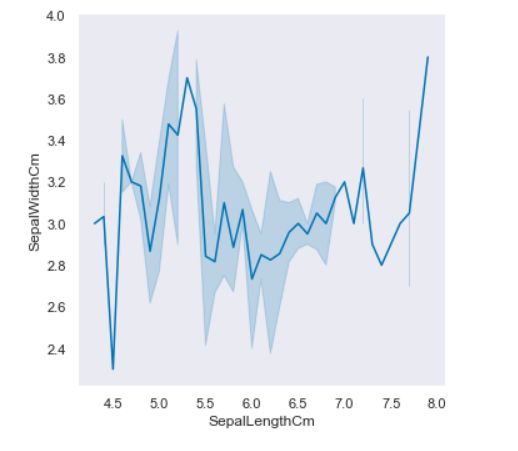
# kind='line'
sns.relplot(x='SepalLengthCm', y='SepalWidthCm', kind="line",data = df_Iris)
# 阴影部分为置信空间ci=None可控制
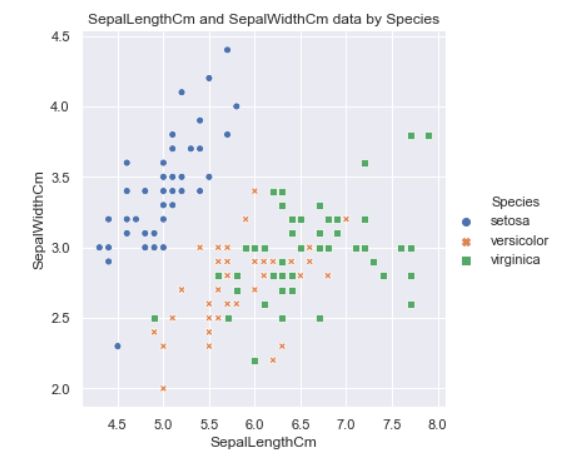
hue
在某一维度,用不同的颜色区分出来
# 表示按照Species对数据进行分类, 而style表示每个类别的标签系列格式不一致.
sns.relplot(x='SepalLengthCm', y='SepalWidthCm', hue='Species', style='Species', data=df_Iris )
plt.title('SepalLengthCm and SepalWidthCm data by Species')
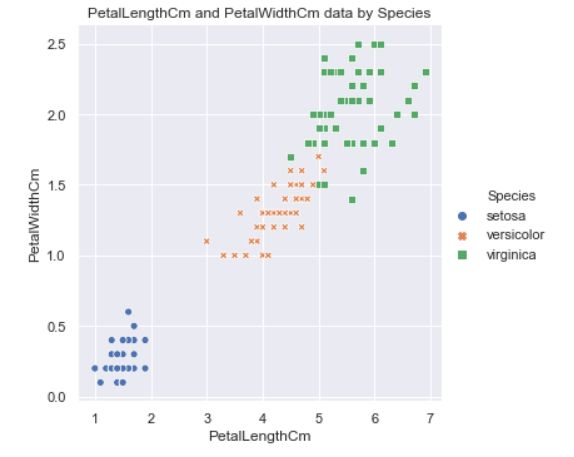
#花瓣长度与宽度分布散点图
sns.relplot(x='PetalLengthCm', y='PetalWidthCm', hue='Species', style='Species', data=df_Iris )
plt.title('PetalLengthCm and PetalWidthCm data by Species')
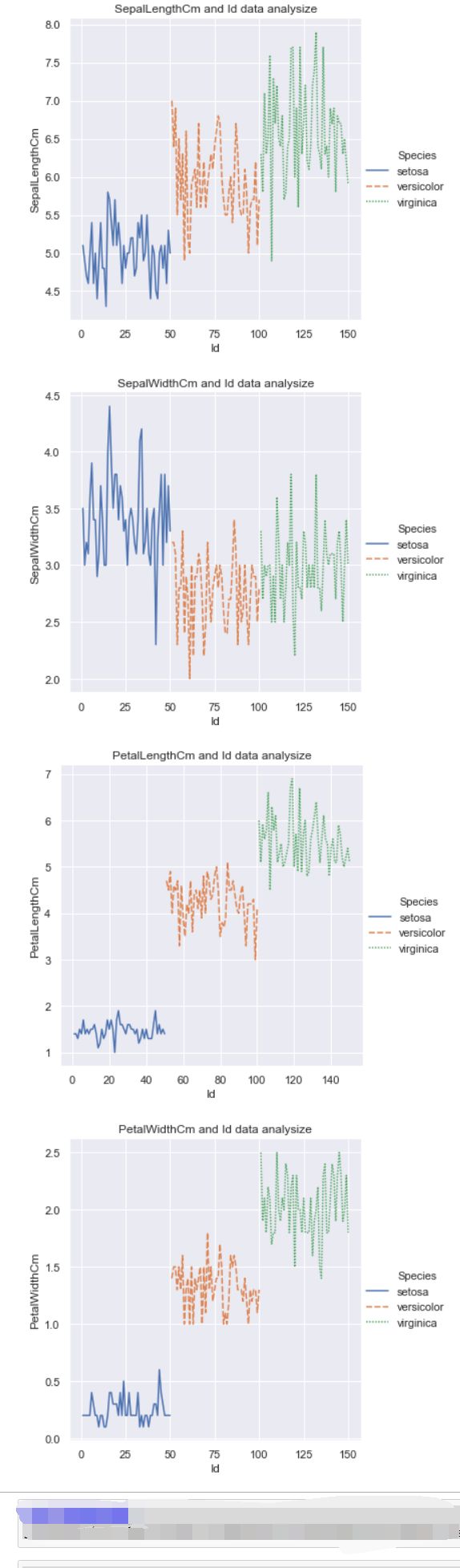
#花萼长度与Id之间关系图
sns.relplot(x="Id", y="SepalLengthCm",hue="Species", style="Species",kind="line", data=df_Iris)
plt.title('SepalLengthCm and Id data analysize')
#花萼宽度与Id之间关系图
sns.relplot(x="Id", y="SepalWidthCm",hue="Species", style="Species",kind="line", data=df_Iris)
plt.title('SepalWidthCm and Id data analysize')
#花瓣长度与Id之间关系图
sns.relplot(x="Id", y="PetalLengthCm",hue="Species", style="Species",kind="line", data=df_Iris)
plt.title('PetalLengthCm and Id data analysize')
#花瓣宽度与Id之间关系图
sns.relplot(x="Id", y="PetalWidthCm",hue="Species", style="Species",kind="line", data=df_Iris)
plt.title('PetalWidthCm and Id data analysize')
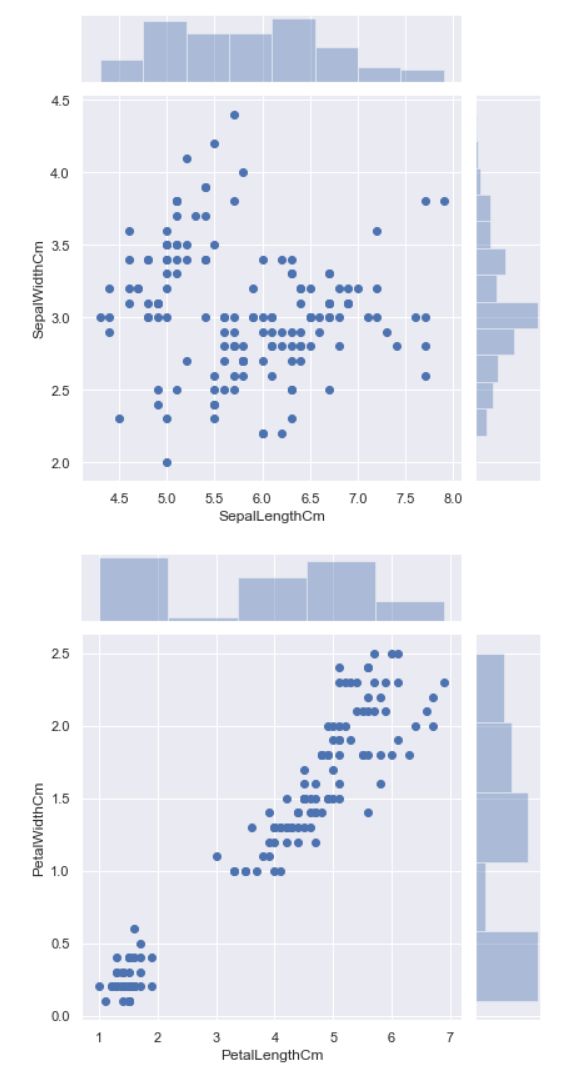
联合分布 jointplot
jointplot(x,y,data,color,s,edgecolor,linewidth,kind,space,size,ratio.marginal_kws)
sns.jointplot(x='SepalLengthCm', y='SepalWidthCm', data=df_Iris)
sns.jointplot(x='PetalLengthCm', y='PetalWidthCm', data=df_Iris)
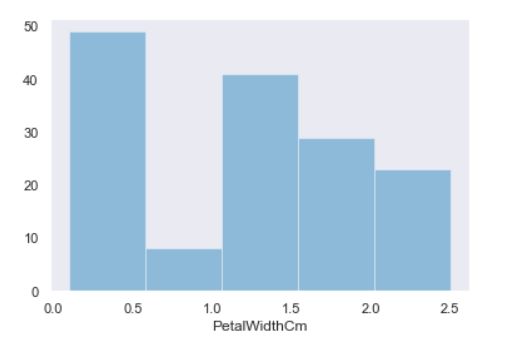
displot
displot()集合了matplotlib的hist()与核函数估计kdeplot的功能,增加了rugplot分布观测条显示与利用scipy库fit拟合参数分布的新颖用途
seaborn.distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None, hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None, color=None, vertical=False, norm_hist=False, axlabel=None, label=None, ax=None)
#绘制直方图, 其中kde=False表示不显示核函数估计图,这里为了更方便去查看频数而设置它为False.
# bins划分直方图区间
sns.distplot(df_Iris.SepalLengthCm,bins=8, hist=True, kde=False)
sns.distplot(df_Iris.SepalWidthCm,bins=13, hist=True, kde=False)
sns.distplot(df_Iris.PetalLengthCm, bins=5, hist=True, kde=False)
sns.distplot(df_Iris.PetalWidthCm, bins=5, hist=True, kde=False)
boxplot
箱形图(Box-plot)又称为盒须图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图。它能显示出一组数据的最大值、最小值、中位数及上下四分位数。因形状如箱子而得名。
seaborn.boxplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, width=0.8, dodge=True, fliersize=5, linewidth=None, whis=1.5, notch=False, ax=None, **kwargs)
#比如数据中的SepalLengthCm属性
sns.boxplot(x='SepalLengthCm', data=df_Iris)
#比如数据中的SepalWidthCm属性
sns.boxplot(x='SepalWidthCm', data=df_Iris)
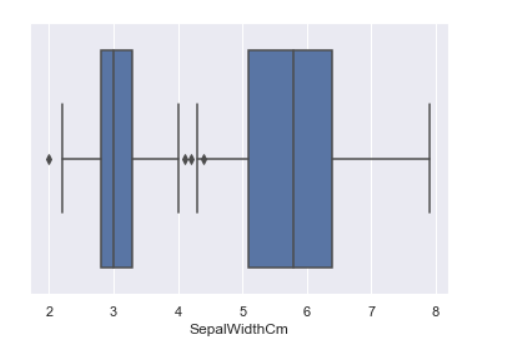
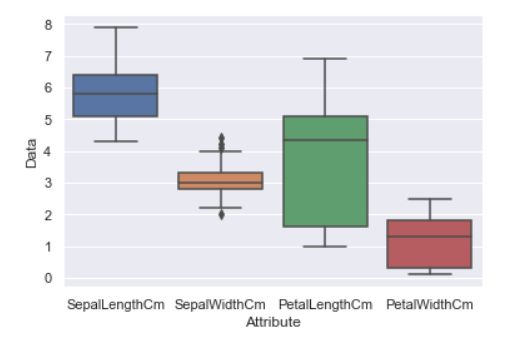
#对于每个属性的data创建一个新的DataFrame
Iris1 = pd.DataFrame({"Id": np.arange(1,151), 'Attribute': 'SepalLengthCm', 'Data':df_Iris.SepalLengthCm, 'Species':df_Iris.Species})
Iris2 = pd.DataFrame({"Id": np.arange(151,301), 'Attribute': 'SepalWidthCm', 'Data':df_Iris.SepalWidthCm, 'Species':df_Iris.Species})
Iris3 = pd.DataFrame({"Id": np.arange(301,451), 'Attribute': 'PetalLengthCm', 'Data':df_Iris.PetalLengthCm, 'Species':df_Iris.Species})
Iris4 = pd.DataFrame({"Id": np.arange(451,601), 'Attribute': 'PetalWidthCm', 'Data':df_Iris.PetalWidthCm, 'Species':df_Iris.Species})
#将四个DataFrame合并为一个.
Iris = pd.concat([Iris1, Iris2, Iris3, Iris4])
#绘制箱线图
sns.boxplot(x='Attribute', y='Data', data=Iris)
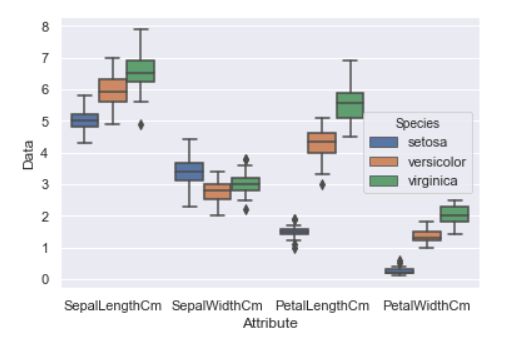
sns.boxplot(x='Attribute', y='Data',hue='Species', data=Iris)
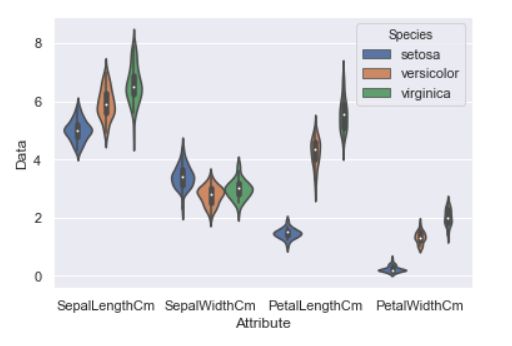
violinplot
violinplot与boxplot扮演类似的角色,它显示了定量数据在一个(或多个)分类变量的多个层次上的分布,这些分布可以进行比较。不像箱形图中所有绘图组件都对应于实际数据点,小提琴绘图以基础分布的核密度估计为特征。
seaborn.violinplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, bw=‘scott’, cut=2, scale=‘area’, scale_hue=True, gridsize=100, width=0.8, inner=‘box’, split=False, dodge=True, orient=None, linewidth=None, color=None, palette=None, saturation=0.75, ax=None, **kwargs)
sns.violinplot(x='Attribute', y='Data', hue='Species', data=Iris )
#花萼长度
sns.boxplot(x='Species', y='SepalLengthCm', data=df_Iris)
sns.violinplot(x='Species', y='SepalLengthCm', data=df_Iris)
plt.title('SepalLengthCm data by Species')
#花萼宽度
sns.boxplot(x='Species', y='SepalWidthCm', data=df_Iris)
sns.violinplot(x='Species', y='SepalWidthCm', data=df_Iris)
plt.title('SepalWidthCm data by Species')
#花瓣长度
sns.boxplot(x='Species', y='PetalLengthCm', data=df_Iris)
sns.violinplot(x='Species', y='PetalLengthCm', data=df_Iris)
plt.title('PetalLengthCm data by Species')
#花瓣宽度
sns.boxplot(x='Species', y='PetalWidthCm', data=df_Iris)
sns.violinplot(x='Species', y='PetalWidthCm', data=df_Iris)
plt.title('PetalWidthCm data by Species')
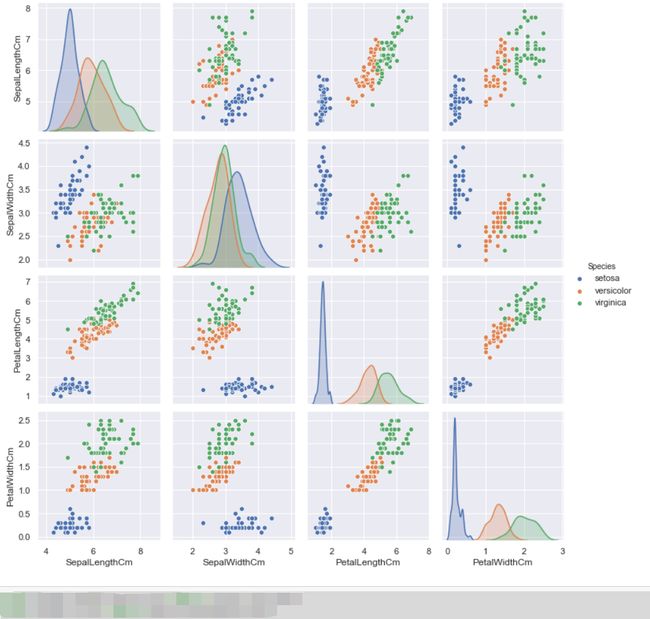
pairplot
pairplot中pair是成对的意思,pairplot主要展现的是变量两两之间的关系(线性或非线性,有无较为明显的相关关系),照例来总览一下pairplot的API。
seaborm.pairplot(data,hue=None,hue_order=None,palette=None,vars=None,x_vars=None,
y_vars=None,kind=‘scattr’,diag_kind=‘hist’,markers=None,size=2.5,aspect=1,dropna=True,plot_ kws=None, diag. kws=None, grid. kws=None)
# 删除Id特征, 绘制分布图
sns.pairplot(df_Iris.drop('Id', axis=1), hue='Species')
# 保存图片, 由于在jupyter notebook中太大, 不能一次截图
plt.savefig('pairplot.png')
plt.show()
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
X=df_Iris[['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm']]
y = df_Iris['Species']
## 将数据按照8:2的比例随机分为训练集, 测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
#初始化决策树模型
dt = DecisionTreeClassifier()
#训练模型
dt.fit(X_train, y_train)
#用测试集评估模型的好坏
dt.score(X_test, y_test)

参考文献
https://www.kaggle.com/uciml/iris#Iris.csv
https://www.cnblogs.com/star-zhao/p/9847082.html
https://blog.csdn.net/u013317445/article/details/88175366
https://blog.csdn.net/qq_42554007/article/details/82624418
http://seaborn.pydata.org/api.html