爬虫————Scrapy框架和scrapy - redis 架构
文章目录
- Scrapy框架
- Scrapy框架整体架构
- Scrapy 框架运行流程
- Scrapy 框架各个模块分析
- Scrapy基本工作流程
- Scrapy常用命令
- scrapy - redis 架构
- scrapy - redis 简介
- scrapy - redis 架构
- 基本运行流程
- 优缺点
- scrapy - redis 常用配置
- scrapy - redis 键名介绍
- scrapy - redis 简单实例
- 项目案例
- 项目介绍
- 项目需求
- Spider代码
- items
- Pipeline
- setting
Scrapy框架
Scrapy框架整体架构
Scrapy 框架运行流程
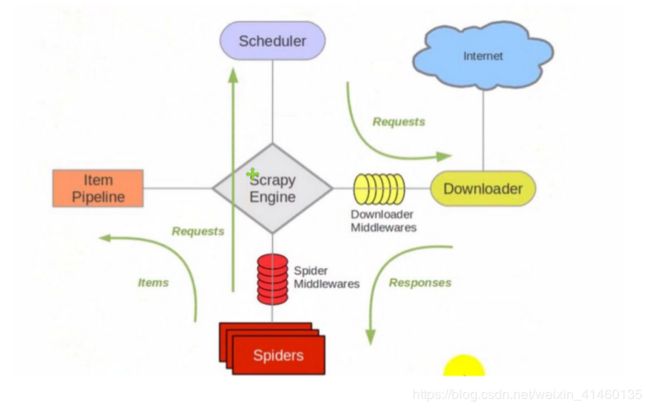
Scrapy 框架各个模块分析
-
引擎(Scrapy)
用来处理整个系统的数据流处理, 是整个框架的核心; -
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回,
即由调度器决定下一个所要爬取得网址是什么,并且去重; -
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给Spiders; -
爬虫(Spiders)
负责爬取信息, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 -
项目管道(Pipeline)
负责处理爬虫从网页中爬取的信息,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 -
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 -
爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 -
调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy基本工作流程
首先Spider将想要爬取的URL发给引擎,引擎将这些URL地址传递给Pipeline,Pipeline将URL排序,入队之后交给Downloaders。Downloaders向互联网发送请求,并接收下载响应(response),将响应经scrapyEngine,spiderMiddlewares(可选)交给spiders。
spiders处理response,提取数据并将数据经scrapyEngine交给pipline保存(可以是本地可以是数据库)。提取的url重新经scrapyEngine交给scheduler进行下一个循环,直到无url请求时程序停止结束。
Scrapy常用命令
scrapy startproject 项目名称
在当前目录中创建一个项目文件(类似于Django)
scrapy genspider [-t template]
创建爬虫应用
scrapy crawl 爬虫应用名称 (-o 文件名)
单独运行爬虫(保存至文件中)
scrapy - redis 架构
scrapy - redis 简介
scrapy-redis 是 scrapy 框架基于 redis 数据库的组件,用于 scrapy 项目的分布式开发和部署。
官方文档:https://scrapy-redis.readthedocs.io/en/stable/
源码位置:https://github.com/rmax/scrapy-redis
参考博客:https://www.cnblogs.com/kylinlin/p/5198233.html
Scrapy 即插即用组件
Scheduler 调度器 + Duplication 复制 过滤器, Item Pipeline ,基本spider。
scrapy - redis 架构

基本运行流程
首先 Slaver 端从 Master 端拿任务( Request 、 url )进行数据抓取, Slaver 抓取数据的同
时,产生新任务的 Request 便提交给 Master 处理;
Master 端只有一个 Redis 数据库,负责将未处理的 Request 去重和任务分配,将处理后的
Request 加入待爬队列,并且存储爬取的数据。
Scrapy-Redis 默认使用的就是这种策略,实现简单,因为任务调度等工作 Scrapy-Redis 都已经帮我
们做好了,我们只需要继承 RedisSpider 、指定 redis_key 就行了。
优缺点
-
优势:
分布式爬取
可以启动多个 spider 工程,相互之间共享单个 redis 的 requests 队列。最适合广泛的多个域名网站的内容爬取。分布式数据处理
爬取到的 scrapy 的 item 数据可以推入到 redis 队列中,这意味着你可以根据需求启动尽能多的处理程序来共享item的队列,进行item数据持久化处理 -
缺点:
Scrapy-Redis 调度的任务是 Request 对象,里面信息量比较大(不仅包含 url ,还有
callback 函数、 headers 等信息)降低爬虫速度
占用 Redis 大量的存储空间
需要一定硬件水平
scrapy - redis 常用配置
# 使用了scrapy_redis的去重组件,在redis数据库里做去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用了scrapy_redis的调度器,在redis里分配请求
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#
在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis
queues
SCHEDULER_PERSIST = True
# 通过配置RedisPipeline将item写入key为 spider.name : items 的redis的list中,供后面的分
布式处理item 这个已经由 scrapy-redis 实现,不需要我们写代码,直接使用即可
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 100 ,
}
# 指定redis数据库的连接参数
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
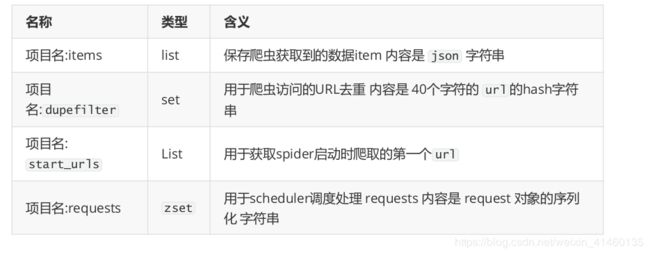
scrapy - redis 键名介绍
scrapy-redis 中都是用key-value形式存储数据,其中有几个常见的key-value形式
scrapy - redis 简单实例
在原来非分布式爬虫的基础上,使用 scrapy-redis 简单搭建一个分布式爬虫,过程只需要修改下面文件:
settings.py
spider 文件
继承类:由 scrapy.Spider 修改为 RedisSpider
start_url 已经不需要了,修改为: redis_key = “xxxxx”
在 redis 数据库中,设置一个 redis_key 的值,作为初始的 url , scrapy 就会自动在redis 中取出 redis_key 的值,作为初始 url ,实现自动爬取。
lpush xxxx:start_urls http:xxxxx.com/xxxx
项目案例
项目介绍
为了汇总、归类和整合网络上杂乱无章的职位信息,设计基于 Scrapy 的职位画像系统,该系统将招聘
网站的招聘页面进行划分.利用 Python 使用 Xpath 和正则表达式的爬取规则设计网页爬取器,获得
职位信息.利用 MySQL 数据库存储爬取的数据,并进行数据清洗及分析,使用 Flask 和 Echarts 实
现数据可视化.该系统通过图表直观展现职位画像,帮助用户了解目前各个领域职位的需求情况,为用
户提供参考,同时从各个维度搭建职位检索功能.
项目需求
数据来源: 拉钩网, Boss直聘和 51job 网站
数据提取
Spider代码
import scrapy
import requests
from ZhiWei import settings
from fake_useragent import UserAgent
class lagouSpider(scrapy.Spider):
name = 'lagou'
allowed_domains = ['lagou.com']
start_urls = ['http://lagou.com/']
def start_requests(self):
ua = UserAgent()
headers = {
'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_python',
'Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'User-Agent': ua.random
}
data = {
'first': 'false',
'pn': str(1),
'kd': 'python'
}
url_start = 'https://www.lagou.com/jobs/list_python'
url_prase = 'https://www.lagou.com/jobs/list_python/postionAjax.josn?needAddtionalResult = false'
session = requests.Session()
session.get(url_start, headers=headers, timeout=3)
cookies = session.cookies
yield scrapy.FormRequest(url_prase,
callback=self.parse,
method='POST',
formdata=data,
headers=headers,
cookies=dict(cookies))
def parse(self, response):
print(response.text)
import json
data = json.loads(response.text)
items
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
address = scrapy.Field()
salary = scrapy.Field()
create_time = scrapy.Field()
body = scrapy.Field()
company_name = scrapy.Field()
postion_id = scrapy.Field()
position_name = scrapy.Field()
work_year = scrapy.Field()
educational = scrapy.Field()
pass
class OtherItem(scrapy.Item):
name = scrapy.Field()
Pipeline
class ZhiweiPipeline(object):
def process_item(self,item,spider):
return item
setting
# -*- coding: utf-8 -*-
# Scrapy settings for ZhiWei project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'ZhiWei'
SPIDER_MODULES = ['ZhiWei.spiders']
NEWSPIDER_MODULE = 'ZhiWei.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'ZhiWei (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# 使用了scrapy_redis的去重组件,在redis数据库里做去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用了scrapy_redis的调度器,在redis里分配请求
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redisqueues
SCHEDULER_PERSIST = True
# 通过配置RedisPipeline将item写入key为 spider.name : items 的redis的list中,供后面的分布式处理item 这个已经由 scrapy-redis 实现,不需要我们写代码,直接使用即可
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 100 ,
'ZhiWei.pipelines.ZhiweiPipeline': 300,
}
# 指定redis数据库的连接参数
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'ZhiWei.middlewares.ZhiweiSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'ZhiWei.middlewares.ZhiweiDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'ZhiWei.pipelines.ZhiweiPipeline': 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'