用Keras建立自动编码器
用Keras建立自动编码器
什么是autoencoders(自动编码器)?

“自动编码”是一种数据压缩算法,其中压缩和解压缩功能是1)数据特定的,2)有损的,3)从示例自动学习而不是由人工学习。另外,在几乎所有使用术语“自动编码器”的上下文中,压缩和解压缩功能都是用神经网络实现的。
1)自动编码器是特定于数据的,这意味着它们只能压缩类似于他们训练过的数据。这与例如MPEG-2音频层III(MP3)压缩算法不同,该算法通常仅保留关于“声音”的假设,而不关于特定类型的声音。在面部图片上训练的自动编码器在压缩树木图片方面做得相当差,因为它将学习的特征将是面部特定的。
2)自动编码器是有损耗的,这意味着与原始输入相比,解压缩的输出会降低(类似于MP3或JPEG压缩)。这与无损算术压缩不同。
3)自动编码器是从数据示例中自动学习的,这是一个有用的属性:它意味着很容易训练算法的特定实例,这些实例将在特定类型的输入上表现良好。它不需要任何新的工程,只需要适当的培训数据。
要构建自动编码器,您需要三件事:编码功能,解码功能,以及数据的压缩表示与解压缩表示之间的信息丢失量之间的距离函数(即“丢失”函数)。编码器和解码器将被选择为参数函数(通常是神经网络),并且相对于距离函数是可微分的,因此可以使用随机梯度下降来优化编码/解码函数的参数以最小化重建损失。 。这很简单!而且你甚至不需要理解任何这些词来开始在实践中使用自动编码器。
- Are they good at data compression?
通常,不是真的。 例如,在图像压缩中,训练一个比JPEG等基本算法更好的自动编码器是非常困难的,并且通常可以实现的唯一方法是将自己限制在一种非常特殊的图像类型(例如 哪个JPEG做得不好)。 自动编码器是特定于数据的这一事实使得它们对于实际数据压缩问题通常是不切实际的:您只能将它们用于与其训练相似的数据,并使它们更加通用,因此需要大量的训练数据。 但是,谁知道,未来的进步可能会改变这一点 - What are autoencoders good for?
它们很少用于实际应用中。 2012年,他们简要地发现了一种用于深度卷积神经网络的贪婪分层预训练的应用[1],但随着我们开始意识到更好的随机权重初始化方案足以从头开始训练深度网络,这很快就会过时。 2014年,批量标准化[2]开始允许更深层次的网络,从2015年底开始,我们可以使用剩余学习从头开始训练任意深度的网络[3]。
今天,自动编码器的两个有趣的实际应用是数据去噪(我们将在本文后面介绍),以及数据可视化的降维。通过适当的维度和稀疏性约束,自动编码器可以学习比PCA或其他基本技术更有趣的数据投影。
特别是对于2D可视化,t-SNE(发音为“tee-snee”)可能是最好的算法,但它通常需要相对低维的数据。因此,在高维数据中可视化相似关系的良好策略是首先使用自动编码器将数据压缩到低维空间(例如32维),然后使用t-SNE将压缩数据映射到2D平面。请注意,Keras中t-SNE的一个很好的参数化实现是由Kyle McDonald开发的,可以在Github上获得。其实scikit-learn也有一个简单实用的实现。
- 那么自动编码器有什么重要意义呢?
他们的主要声誉来自于在线提供的许多入门机器学习课程。因此,很多新手都非常喜欢自动编码器并且无法获得足够的自动编码器。这就是本教程存在的原因!
否则,他们吸引了如此多的研究和关注的一个原因是因为他们长期以来被认为是解决无监督学习问题的潜在途径,即在不需要标签的情况下学习有用的表示。然后,自动编码器不是真正的无监督学习技术(这意味着完全不同的学习过程),它们是自我监督技术,是监督学习的特定实例,其中目标是从输入数据生成的。为了获得自我监督的模型来学习有趣的特征,你必须提出一个有趣的合成目标和损失函数,这就是出现问题的地方:仅仅学习以细微的方式重建你的输入可能不是这里的正确选择。在这一点上,有明显的证据表明,专注于在像素级重建图像,并不能有助于学习标签 - 超级化学习所引发的那种有趣的抽象特征(其中目标是相当抽象的概念“发明的” “通过人类如”狗“,”汽车“…)。事实上,人们可能会争辩说,这方面的最佳特征是在精确输入重建时最差的特征,同时在您感兴趣的主要任务(分类,本地化等)上实现高性能。
在应用于视觉的自我监督学习中,自动编码器式输入重建的潜在富有成效的替代方案是使用玩具任务,例如拼图解决或细节上下文匹配(能够匹配高分辨率但小的图片片段与从中提取的图片的低分辨率版本)。下面的文章研究拼图解决问题,并做了一个非常有趣的阅读:Noroozi和Favaro(2016)通过解决拼图游戏的无监督学习视觉表现。这些任务为模型提供了关于传统自动编码器中缺失的输入数据的内置假设,例如“视觉宏观结构比像素级细节更重要”。

- Let’s build the simplest possible autoencoder
我们将从简单开始,使用单个完全连接的神经层作为编码器和解码器:
from keras.layers import Input, Dense
from keras.models import Model
# this is the size of our encoded representations
encoding_dim = 32 # 32 floats -> compression of factor 24.5, assuming the input is 784 floats
# this is our input placeholder
input_img = Input(shape=(784,))
# "encoded" is the encoded representation of the input
encoded = Dense(encoding_dim, activation='relu')(input_img)
# "decoded" is the lossy reconstruction of the input
decoded = Dense(784, activation='sigmoid')(encoded)
# this model maps an input to its reconstruction
autoencoder = Model(input_img, decoded)
我们还创建一个单独的编码器模型:
# this model maps an input to its encoded representation
encoder = Model(input_img, encoded)
以及解码器模型:
# create a placeholder for an encoded (32-dimensional) input
encoded_input = Input(shape=(encoding_dim,))
# retrieve the last layer of the autoencoder model
decoder_layer = autoencoder.layers[-1]
# create the decoder model
decoder = Model(encoded_input, decoder_layer(encoded_input))
现在让我们训练我们的自动编码器重建MNIST数字。
首先,我们将配置我们的模型以使用每像素二进制交叉熵丢失和Adadelta优化器:
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
让我们准备输入数据。 我们正在使用MNIST数字,我们正在丢弃标签(因为我们只对编码/解码输入图像感兴趣)。
from keras.datasets import mnist
import numpy as np
(x_train, _), (x_test, _) = mnist.load_data()
我们将对0到1之间的所有值进行归一化,并将28x28图像展平为大小为784的向量。
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
print x_train.shape
print x_test.shape
现在让我们训练我们的自动编码器50个时期:
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
在50个时期之后,自动编码器似乎达到稳定的训练/测试损失值约0.11。 我们可以尝试可视化重建的输入和编码的表示。 我们将使用Matplotlib。
# encode and decode some digits
# note that we take them from the *test* set
encoded_imgs = encoder.predict(x_test)
decoded_imgs = decoder.predict(encoded_imgs)
# use Matplotlib (don't ask)
import matplotlib.pyplot as plt
n = 10 # how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
# display original
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstruction
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
这就是我们得到的。 顶行是原始数字,底行是重建数字。 我们正在通过这种基本方法失去一些细节。

- 在编码表示上添加稀疏性约束
在前面的示例中,表示仅受隐藏层(32)的大小约束。 在这种情况下,通常发生的是隐藏层正在学习PCA的近似(主成分分析)。 但是,将表示约束为紧凑的另一种方法是在隐藏表示的活动上添加稀疏性约束,因此在给定时间更少的单元将“触发”。 在Keras中,可以通过向我们的Dense层添加activity_regularizer来完成:
from keras import regularizers
encoding_dim = 32
input_img = Input(shape=(784,))
# add a Dense layer with a L1 activity regularizer
encoded = Dense(encoding_dim, activation='relu',
activity_regularizer=regularizers.l1(10e-5))(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(input_img, decoded)
让我们训练这个模型100个时期(增加正规化,模型不太可能过度拟合,可以训练更长)。 模型以训练损失0.11和测试损失0.10结束。 两者之间的差异主要是由于正规化术语被添加到训练期间的损失(价值约0.01)。
这是我们新结果的可视化:

它们看起来与之前的模型非常相似,唯一的显着差异是编码表示的稀疏性。 encoded_imgs.mean()产生的值为3.33(超过10,000个测试图像),而使用之前的模型,相同的数量为7.30。 因此,我们的新模型产生两次稀疏的编码表示。
- Deep autoencoder
我们不必将自己局限于单层作为编码器或解码器,我们可以改为使用一叠层,例如:
input_img = Input(shape=(784,))
encoded = Dense(128, activation='relu')(input_img)
encoded = Dense(64, activation='relu')(encoded)
encoded = Dense(32, activation='relu')(encoded)
decoded = Dense(64, activation='relu')(encoded)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(784, activation='sigmoid')(decoded)
试试这个:
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train,
epochs=100,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
经过100个时代,它到达一个训练、测试损失约为0.097,比我们以前的型号好一点。 我们重建的数字看起来也好一点:
- 卷积自动编码器
由于我们的输入是图像,因此使用卷积神经网络(convnets)作为编码器和解码器是有意义的。 在实际设置中,应用于图像的自动编码器始终是卷积自动编码器 - 它们只是表现得更好。
我们来实现一个。 编码器将包含一堆Conv2D和MaxPooling2D层(最大池用于空间下采样),而解码器将包含一堆Conv2D和UpSampling2D层。
from keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras import backend as K
input_img = Input(shape=(28, 28, 1)) # adapt this if using `channels_first` image data format
x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
# at this point the representation is (4, 4, 8) i.e. 128-dimensional
x = Conv2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
为了训练它,我们将使用具有形状的原始MNIST数字(样本,3,28,28),并且我们将标准化0到1之间的像素值。
from keras.datasets import mnist
import numpy as np
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1)) # adapt this if using `channels_first` image data format
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1)) # adapt this if using `channels_first` image data format
让我们训练这个模型50个时代。 为了演示如何在训练期间可视化模型的结果,我们将使用TensorFlow后端和TensorBoard回调。
首先,让我们打开一个终端并启动一个TensorBoard服务器,它将读取存储在/ tmp / autoencoder中的日志。
tensorboard --logdir=/tmp/autoencoder
然后让我们训练我们的模型。 在回调列表中,我们传递了TensorBoard回调的实例。 在每个纪元之后,此回调会将日志写入/ tmp / autoencoder,这可以由我们的TensorBoard服务器读取。
from keras.callbacks import TensorBoard
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=128,
shuffle=True,
validation_data=(x_test, x_test),
callbacks=[TensorBoard(log_dir='/tmp/autoencoder')])
这允许我们监控TensorBoard Web界面中的培训(通过导航到http://0.0.0.0:6006):
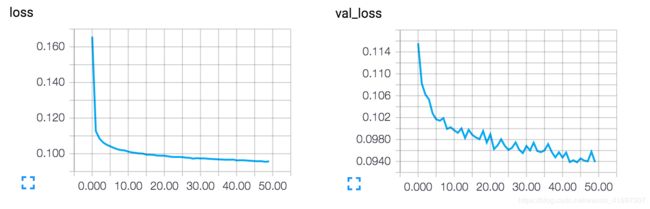
该模型收敛到0.094的损失,明显优于我们之前的模型(这在很大程度上是由于编码表示的熵容量较高,128维度与先前的32维度相比)。 我们来看看重建的数字:
decoded_imgs = autoencoder.predict(x_test)
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
# display original
ax = plt.subplot(2, n, i)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstruction
ax = plt.subplot(2, n, i + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
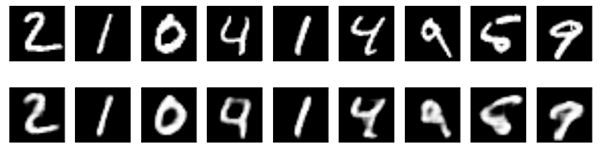
我们还可以看一下128维编码表示。 这些表示是8x4x4,因此我们将它们重新整形为4x32,以便能够将它们显示为灰度图像。
n = 10
plt.figure(figsize=(20, 8))
for i in range(n):
ax = plt.subplot(1, n, i)
plt.imshow(encoded_imgs[i].reshape(4, 4 * 8).T)
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()

- 应用于图像去噪
让我们把卷积自动编码器用于图像去噪问题。 这很简单:我们将训练自动编码器来映射噪声数字图像以清理数字图像。
以下是我们将如何生成合成噪声数字:我们只应用高斯噪声矩阵并将图像剪切在0和1之间。
from keras.datasets import mnist
import numpy as np
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1)) # adapt this if using `channels_first` image data format
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1)) # adapt this if using `channels_first` image data format
noise_factor = 0.5
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
这是嘈杂的数字的样子:
n = 10
plt.figure(figsize=(20, 2))
for i in range(n):
ax = plt.subplot(1, n, i)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()

如果你眯着眼睛,你仍然可以识别它们,但几乎没有。 我们的自动编码器能学会恢复原始数字吗? 我们来看看。
与之前的卷积自动编码器相比,为了提高重建的质量,我们将使用略有不同的模型,每层使用更多滤波器:
input_img = Input(shape=(28, 28, 1)) # adapt this if using `channels_first` image data format
x = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
# at this point the representation is (7, 7, 32)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
Let’s train it for 100 epochs:
autoencoder.fit(x_train_noisy, x_train,
epochs=100,
batch_size=128,
shuffle=True,
validation_data=(x_test_noisy, x_test),
callbacks=[TensorBoard(log_dir='/tmp/tb', histogram_freq=0, write_graph=False)])
现在让我们来看看结果。 顶部,馈送到网络的噪声数字,以及底部,数字由网络重建。
它似乎工作得很好。 如果您将此过程扩展到更大的网络,您可以开始构建文档去噪或音频去噪模型。 Kaggle有一个有趣的数据集可以帮助您入门。
- 序列到序列自动编码器
如果您输入的是序列,而不是矢量或2D图像,那么您可能希望将一种可以捕获时间结构的模型(如LSTM)用作编码器和解码器。 要构建基于LSTM的自动编码器,首先使用LSTM编码器将输入序列转换为包含整个序列信息的单个向量,然后重复此向量n次(其中n是输出序列中的时间步数), 并运行LSTM解码器将此常数序列转换为目标序列。
我们不会在任何特定数据集上证明这一点。 我们将在此处提供一个代码示例供读者参考!
from keras.layers import Input, LSTM, RepeatVector
from keras.models import Model
inputs = Input(shape=(timesteps, input_dim))
encoded = LSTM(latent_dim)(inputs)
decoded = RepeatVector(timesteps)(encoded)
decoded = LSTM(input_dim, return_sequences=True)(decoded)
sequence_autoencoder = Model(inputs, decoded)
encoder = Model(inputs, encoded)
- Variational autoencoder (VAE)
变分自动编码器是一种稍微更现代和有趣的自动编码方式。
你问什么是变分自动编码器? 它是一种自动编码器,对正在学习的编码表示添加了约束。 更准确地说,它是一个自动编码器,可以为其输入数据学习潜变量模型。 因此,您不是让神经网络学习任意函数,而是学习建模数据的概率分布参数。 如果从此分布中采样点,则可以生成新的输入数据样本:VAE是“生成模型”。
变分自动编码器如何工作?
首先,编码器网络将输入样本x转换为潜在空间中的两个参数,我们将注意到z_mean和z_log_sigma。然后,我们通过z = z_mean + exp(z_log_sigma)* epsilon从假定生成数据的潜在正态分布中随机地采样相似点z,其中epsilon是随机正态张量。最后,解码器网络将这些潜在空间点映射回原始输入数据。
通过两个损失函数训练模型的参数:重建损失迫使解码的样本与初始输入匹配(就像我们之前的自动编码器一样),以及学习的潜在分布和先前分布之间的KL差异,充当正规化术语。实际上你可以完全摆脱后一个术语,尽管它确实有助于学习格式良好的潜在空间并减少对训练数据的过度拟合。
由于VAE是一个更复杂的示例,因此我们将Github上的代码作为独立脚本提供。在这里,我们将逐步回顾如何创建模型。
首先,这是我们的编码器网络,将输入映射到我们的潜在分配参数:
x = Input(batch_shape=(batch_size, original_dim))
h = Dense(intermediate_dim, activation='relu')(x)
z_mean = Dense(latent_dim)(h)
z_log_sigma = Dense(latent_dim)(h)
我们可以使用这些参数从潜在空间中采样新的相似点:
def sampling(args):
z_mean, z_log_sigma = args
epsilon = K.random_normal(shape=(batch_size, latent_dim),
mean=0., std=epsilon_std)
return z_mean + K.exp(z_log_sigma) * epsilon
# note that "output_shape" isn't necessary with the TensorFlow backend
# so you could write `Lambda(sampling)([z_mean, z_log_sigma])`
z = Lambda(sampling, output_shape=(latent_dim,))([z_mean, z_log_sigma])
最后,我们可以将这些采样的潜点映射回重建的输入:
decoder_h = Dense(intermediate_dim, activation='relu')
decoder_mean = Dense(original_dim, activation='sigmoid')
h_decoded = decoder_h(z)
x_decoded_mean = decoder_mean(h_decoded)
到目前为止我们所做的工作允许我们实例化3个模型:
端到端自动编码器将输入映射到重建
编码器将输入映射到潜在空间
一个生成器,可以在潜在空间上取点,并输出相应的重建样本。
# end-to-end autoencoder
vae = Model(x, x_decoded_mean)
# encoder, from inputs to latent space
encoder = Model(x, z_mean)
# generator, from latent space to reconstructed inputs
decoder_input = Input(shape=(latent_dim,))
_h_decoded = decoder_h(decoder_input)
_x_decoded_mean = decoder_mean(_h_decoded)
generator = Model(decoder_input, _x_decoded_mean)
我们使用端到端模型训练模型,具有自定义损失函数:重建项的总和,以及KL散度正则化项。
def vae_loss(x, x_decoded_mean):
xent_loss = objectives.binary_crossentropy(x, x_decoded_mean)
kl_loss = - 0.5 * K.mean(1 + z_log_sigma - K.square(z_mean) - K.exp(z_log_sigma), axis=-1)
return xent_loss + kl_loss
vae.compile(optimizer='rmsprop', loss=vae_loss)
We train our VAE on MNIST digits:
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
vae.fit(x_train, x_train,
shuffle=True,
epochs=epochs,
batch_size=batch_size,
validation_data=(x_test, x_test))
因为我们的潜在空间是二维的,所以在这一点上可以做一些很酷的可视化。 一个是查看潜在2D平面上不同类别的邻域:
x_test_encoded = encoder.predict(x_test, batch_size=batch_size)
plt.figure(figsize=(6, 6))
plt.scatter(x_test_encoded[:, 0], x_test_encoded[:, 1], c=y_test)
plt.colorbar()
plt.show()

这些彩色簇中的每一个都是一种数字。 关闭簇是结构相似的数字(即在潜在空间中共享信息的数字)。
因为VAE是一个生成模型,我们也可以用它来生成新的数字! 在这里,我们将扫描潜在的平面,定期对潜在点进行采样,并为每个点生成相应的数字。 这为我们提供了“生成”MNIST数字的潜在流形的可视化。
# display a 2D manifold of the digits
n = 15 # figure with 15x15 digits
digit_size = 28
figure = np.zeros((digit_size * n, digit_size * n))
# we will sample n points within [-15, 15] standard deviations
grid_x = np.linspace(-15, 15, n)
grid_y = np.linspace(-15, 15, n)
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z_sample = np.array([[xi, yi]]) * epsilon_std
x_decoded = generator.predict(z_sample)
digit = x_decoded[0].reshape(digit_size, digit_size)
figure[i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit
plt.figure(figsize=(10, 10))
plt.imshow(figure)
plt.show()

就是这么神奇!