使用DCGAN生成动漫风格的人脸并探索其潜在的特征表征
逐步实验DCGAN并可视化其结果
大家好,已经有一段时间了!今天,我想写一下我学习和试验另一种深度学习技术的结果,即生成性对抗网络(GAN)。我最近研究并了解了它。我想如果把我的实验分享给每个人都会很好。
GAN主要是关于生成某些东西。在本文中,我想分享有关生成动画角色面孔的实验。不仅生成,我还试验了图像可以通过其潜在变量(用于生成面部的矢量)的线性代数运算来操纵。我还看到生成的面部遵循统计分布,这真的很棒。
本文将重点介绍如何使用所解释的每个步骤(使用源代码)执行GAN的教程。它将针对任何对AI感兴趣的人,特别是那些想要练习深度学习的人。它还针对每个想要第一次学习如何做GAN的人。我会尽可能简单地写这篇文章来理解它。我希望读者通过阅读本文了解GAN的一般工作方式。
如果你想更好地理解阅读这篇文章,我建议你至少知道神经网络和卷积神经网络(CNN)。
如果您想了解完整的源代码,可以在本文末尾找到GitHub链接。 现在,我将在存储库中提供python笔记本和Colaboratory链接。
图像0是我们将使用模型形成的图片创建的动画角色面之一。 左边的第一张和第二张图片是用GAN生成的。 第三个是添加第一个和第二个面(你可以称它为第一个和第二个面的融合)。

Images 0 : Example of generated faces and the fusion of their face. G + D = GAN
Technology and Data
- 1 Python 3.7
- 2 Colaboratory : Free Jupyter notebook environment that requires no setup and runs entirely in the cloud. Have GPU Tesla K80 or even TPU! Sadly Tensorflow v2.0 alpha still does not support TPU at the moment of this writing. Sadly, DCGAN cannot be trained via TPU.
- 3 Keras : Python Library for doing Deep Learning.
- 4 Data is taken from here
Introduction
深度学习领域的热门话题之一是生成性对抗网络(GAN)。 由Ian Goodfellow等人引入。它可以从头开始生成无人监督的东西。 在计算机视觉。 有许多研究人员正在研究和改进它。 例如,NVIDIA使用GAN创建真实面部生成器。 还有一些关于音乐领域的研究关于使用GAN。 我之前关于生成音乐的文章也可以通过使用GAN来完成。

研究人员开发了许多不同类型的GAN。最新的(当我写这篇文章时)之一是HoloGAN,可以从自然图像生成3D表示。如果你看看它是如何做的,它实际上是惊人的。实际上,这些先进的GAN遵循GAN如何工作的基本原理。每个GAN都有两个代理作为学习者,鉴别者和生成器(我们稍后会深入研究这些术语)。要了解有关高级GAN技术的更多信息,必须了解基本GAN的工作原理。
本文将重点介绍深层卷积GAN(DCGAN),这是A Radford等提出的GAN变体之一。基本上,它是一个具有许多卷积层的GAN。它是流行的GAN神经网络之一。我们将在他们的论文中构建一个与所提出的架构不同的架构。虽然不同,但仍然会产生一些好的结果。
关于GAN的一个有趣的事情是它将构建其潜在变量(任意长度的一维向量),它可以是线性代数运算。 Image 0上的示例是其中一个示例。第一个面部的矢量(从左侧)被添加到第二个面部的矢量。然后,它产生第三张脸。
它还产生一些有趣的数据分布。分布中的每个点都有不同的面。例如,以-0.7为中心的数据将具有黄色头发的面部。
我们将从了解GAN的简要描述开始。
Brief Description About GAN
So, What is GAN?
为了简化它,它是用于从头开始生成一些新数据的深度学习技术之一。它以无人监督的方式运行,这意味着它可以在没有人类标记的情况下运行。它将根据其学习的模式生成数据。
GAN有一些特征方面是生成模型,它是:
- 学习联合概率P(x,y),其中x是输入,y是输出。它将基于P(x | y)进行推理,给定输出y,它将推断出x。你可以说y是GAN中的真实数据。
- 当模型给出训练实际数据y时,它将学习实际数据的特征。它将通过识别真实数据潜在特征表示变量来学习。为了使其更简单,它学习了真实数据中图像的基本构造函数特征。例如,模型可以学习由眼睛和头发的颜色构成的面部。这两个将是用于生成面部的基础之一。通过调整其变量,它还可以改变生成的面。例如,通过提高眼睛的变量,眼睛会变黑。降低它会产生相反的反面。
- 它可以建立一个概率分布,如正态分布,可用于避免异常值。由于异常值通常在分布中非常罕见,因此生成它非常罕见。因此,GAN在具有异常值的实际数据上运行良好。
So, How it works?
GAN组成两个神经网络,Discriminator和Generator。 GAN将使这两个网络在零和游戏框架(Game Theory)上互相争斗。 这是这些代理(网络)之间的游戏。 GAN中的对抗名称来自这个概念。
Image 2 : Illustration of Discriminator vs Generator .
Generator将生成一些伪数据,Discriminator将识别一些数据,这些数据包含Generator生成的伪数据和从实际数据中采样的数据。 Generator的目标主要是生成一些与真实数据类似的虚假数据,并欺骗Discriminator识别哪些数据是真实的和假的。鉴别器的目标是使识别真假数据变得更加智能。每个代理人将交替移动。通过决定这些代理商,我们希望这些代理商能够变得更强大,尤其是发电机。
你可以说他们是对手的命运对手。主角是发电机,他们通过从竞争对手的斗争中学习,更好,更好地实现我们的目标。
好的,换句话说,Generator将通过对所学习的分布进行采样并模拟与实际数据相同的分布来模拟真实数据。它将训练其可以生成它的神经网络。然而,鉴别器将在监督技术中训练其神经网络以检测伪造和真实数据。每个网络将交替训练其网络。
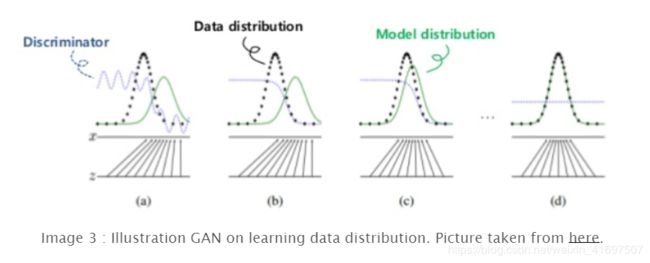
Here is the rough steps on how GAN works:
-
1以正态分布等概率分布生成随机噪声。
-
2将其作为我们的Generator神经网络的输入。它将输出生成的假数据。这些步骤还意味着我们从发生器学到的分布中采样一些数据。我们将噪声标记为z_n,将生成的数据标记为G(z_n)。 G(z_n)表示由发电机G处理的噪声的结果。
-
3我们将生成的假数据与从数据集中采样的数据(实际数据)相结合。让它们成为我们的鉴别者的输入。我们将其标记为D. Discriminator将尝试通过预测数据是否是假的来学习。通过前向传递训练神经网络,然后进行反向传播。更新D权重。
-
4然后,我们需要训练发电机。我们需要将G(z_n)或随机噪声产生的伪数据作为D的输入。注意,此步骤仅将伪数据输入到鉴别器中。正向传递D中的G(z_n)。通过使用鉴别器神经网络,在进行正向传递时,预测伪数据是否是假的(D(G(z_n)))。然后进行反向传播,我们只更新G权重。
-
5重复这些步骤,直到我们看到生成器提供了良好的假数据或已达到最大迭代次数。
图示如下:
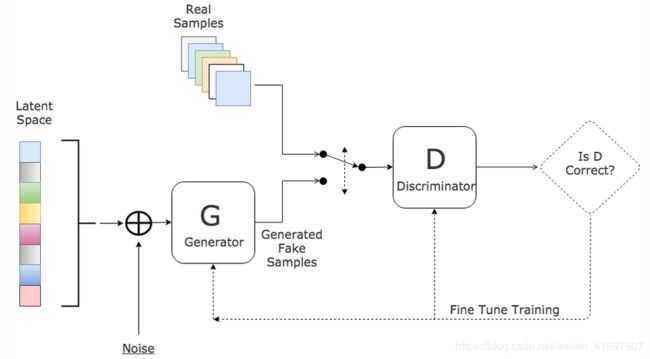
Image 4 : How GAN Works.
通过更新Generator的分布以匹配Discriminator。这与最小化JS Divergence相同。有关详细信息,请参阅此文章。
为了让我们的代理人学习,请确保使鉴别器和发生器相互支配。尽可能使它们保持平衡,同时使鉴别器和发生器学习。当鉴别器过于强大(可以区分假冒和真实100%)时,Generator变得无法学习任何东西。如果在培训过程中我们达到了这一点,那么最好结束它。相反也会产生发电机强于鉴别器的效果。它导致模式崩溃,我们的模型将始终预测任何随机噪声的相同结果。这是GAN的一个难点和困难的部分之一,可以让人感到沮丧。
如果你想了解更多,我建议你先看看这篇很棒的文章。
Implementation
那么,鉴别器和发生器的架构是什么样的呢?
这取决于我们将要开发的GAN的变体。 由于我们将使用DCGAN,我们将使用连续的一对CNN层。
我们将使用与原始论文不同的自定义架构。 我遵循FrançoisChollet深度学习Python一书中使用的架构,并进行了一些更改。
我们用于构建DCGAN的配置如下:
latent_dim = 64
height = 64
width = 64
channels = 3
这意味着我们将有64维潜在变量。 我们的图像的高度和宽度是64.每个图像有3个通道(R,G,B)
这是导入的库以及如何准备数据:
from google.colab import drive
from shutil import copyfile
import os
from keras.preprocessing.image import load_img ,img_to_array
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
# Do it in colaboratory
download = drive.CreateFile({'id': '1jdJXkQIWVGOeb0XJIXE3YuZQeiEPd8rM'})
download.GetContentFile('data.zip')
! unzip data.zip
Here is the architecture :
Generator
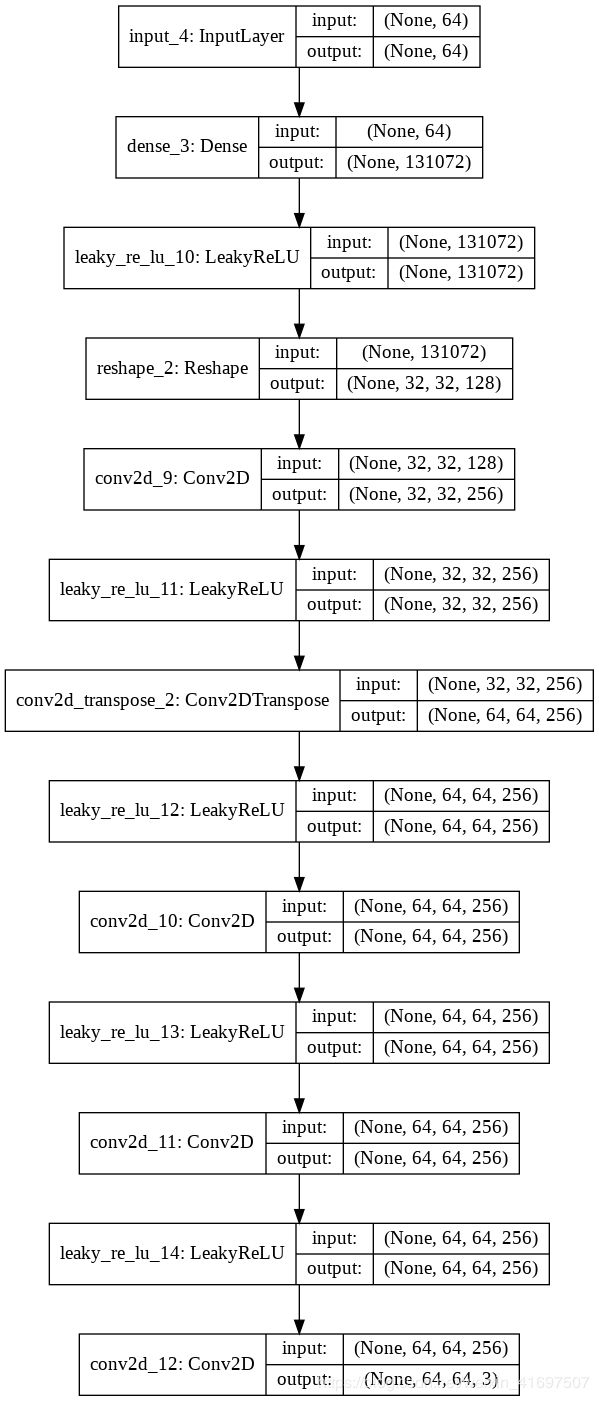
它由卷积层组成,其中一个是卷积转置层。 要对图像的大小进行上采样(32 - > 62),我们将在卷积层中使用strides参数。 这样做是为了避免GAN的不稳定训练。
Code
generator_input = keras.Input(shape = (latent_dim,))
x = layers.Dense(128 * 32 * 32)(generator_input)
x = layers.LeakyReLU()(x)
x = layers.Reshape((32,32,128))(x)
x = layers.Conv2D(256, 5, padding='same')(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2DTranspose(256, 4, strides = 2, padding = 'same')(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(256, 5, padding='same')(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(256, 5, padding='same')(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(channels, 7, activation = 'tanh', padding = 'same')(x)
generator = keras.models.Model(generator_input, x)
generator.summary()
Discriminator
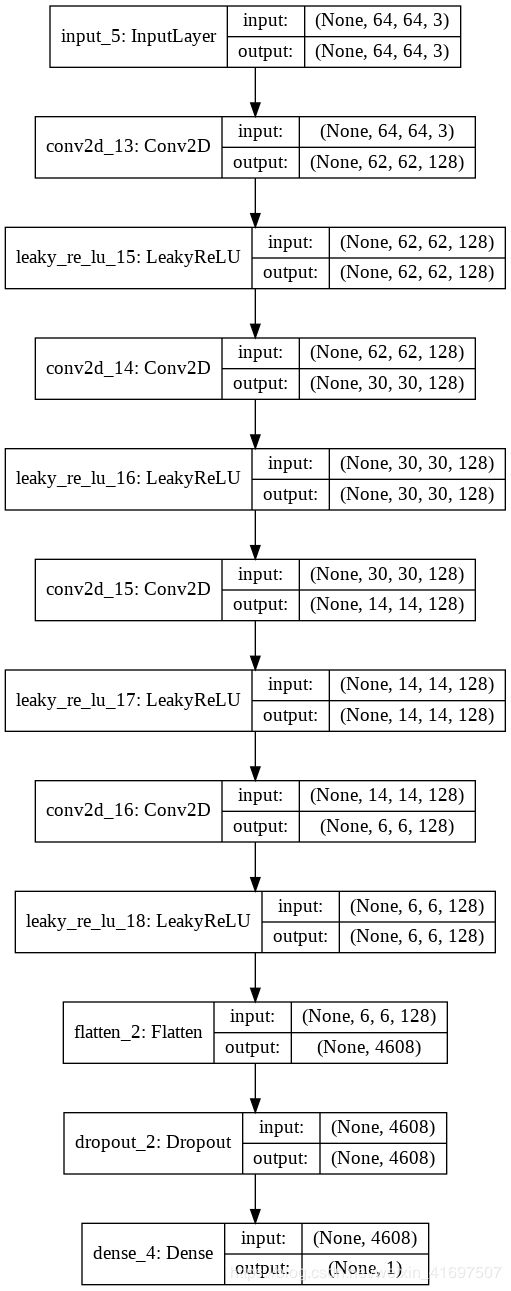
It also consists of Convolution Layers where we use strides to do downsampling.
Code
discriminator_input = layers.Input(shape = (height, width, channels))
x = layers.Conv2D(128, 3)(discriminator_input)
x = layers.LeakyReLU(0.2)(x)
x = layers.Conv2D(128, 4, strides = 2)(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Conv2D(128, 4, strides = 2)(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(128, 4, strides = 2)(x)
x = layers.LeakyReLU()(x)
x = layers.Flatten()(x)
x = layers.Dropout(0.4)(x)
x = layers.Dense(1, activation = 'sigmoid')(x)
discriminator = keras.models.Model(discriminator_input, x)
discriminator.summary()
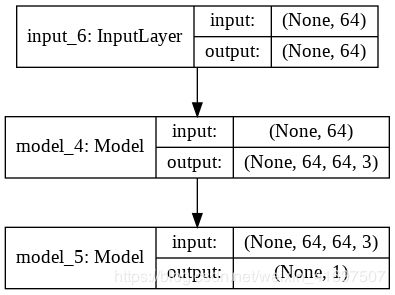
GAN
为了使发生器能够进行反向传播,我们在Keras中创建了新的网络,它是Generator,然后是Discriminator。 在此网络中,我们冻结所有权重,以使其权重不会发生变化。
This is the network :
from keras.optimizers import Adam, RMSprop
discriminator.trainable = False
gan_input = keras.Input(shape=(latent_dim,))
gan_output = discriminator(generator(gan_input))
gan = keras.models.Model(gan_input, gan_output)
gan_optimizer = keras.optimizers.RMSprop(lr = 0.0004, clipvalue = 1.0, decay = 1e-8)
gan.compile(optimizer = gan_optimizer, loss = 'binary_crossentropy')
discriminator_optimizer = keras.optimizers.RMSprop(
lr = 0.0008,
clipvalue = 1.0,
decay = 1e-8
)
discriminator.compile(optimizer = discriminator_optimizer,
loss='binary_crossentropy')
Training
The config of the training is as follow:
iterations = 15000
batch_size = 32
配置意味着我们将进行15000次迭代。 每次迭代我们处理32批真实数据和假数据(总共64个用于训练鉴别器)。
按照我上面解释的粗略步骤,以下是我们如何逐步训练DCGAN:
1 迭代直到最大迭代以下步骤
for step in tqdm_notebook(range(iterations)):
2. 在诸如正态分布的概率分布中生成随机噪声。
random_latent_vectors = np.random.normal(size = (batch_size, latent_dim))
generated_images = generator.predict(random_latent_vectors)
3. 将生成的虚假数据与从数据集中采样的数据相结合。
stop = start + batch_size
real_images = x_train[start: stop]
combined_images = np.concatenate([generated_images, real_images])
labels = np.concatenate([np.ones((batch_size,1)),
np.zeros((batch_size, 1))])
Note that we use sequential sampler where each data will be sampled sequentially until the end of the data. The number that will be sampled is equal to the batch size.
4. 将噪声添加到输入的标签
labels += 0.05 * np.random.random(labels.shape)
This is an important trick on training GAN.
5. 训练Discriminator
d_loss = discriminator.train_on_batch(combined_images, labels)
6. 训练Generator
random_latent_vectors = np.random.normal(size=(batch_size,
latent_dim))
misleading_targets = np.zeros((batch_size, 1))
a_loss = gan.train_on_batch(random_latent_vectors,
misleading_targets)
请注意,我们创建了一个新的潜在向量。 不要忘记我们需要交换标签。 请记住,我们希望最大限度地减少鉴别器在未能预测假货时造成的损失。 misleading_targets的标签应为1。
7. 更新真实数据集的起始索引
start += batch_size
if start > len(x_train) - batch_size:
start = 0
That’s it, here is the complete code on training the DCGAN:
import matplotlib.pyplot as plt
x_train = data_train_gan
iterations = 15000
batch_size = 32
save_dir = '.'
start = 0
for step in tqdm_notebook(range(iterations)):
random_latent_vectors = np.random.normal(size = (batch_size, latent_dim))
generated_images = generator.predict(random_latent_vectors)
stop = start + batch_size
real_images = x_train[start: stop]
combined_images = np.concatenate([generated_images, real_images])
labels = np.concatenate([np.ones((batch_size,1)),
np.zeros((batch_size, 1))])
labels += 0.05 * np.random.random(labels.shape)
d_loss = discriminator.train_on_batch(combined_images, labels)
random_latent_vectors = np.random.normal(size=(batch_size,
latent_dim))
misleading_targets = np.zeros((batch_size, 1))
a_loss = gan.train_on_batch(random_latent_vectors,
misleading_targets)
start += batch_size
if start > len(x_train) - batch_size:
start = 0
# Print the loss and also plot the faces generated by generator
if step % 50 == 0:
print('discriminator loss:', d_loss)
print('advesarial loss:', a_loss)
fig, axes = plt.subplots(2, 2)
fig.set_size_inches(2,2)
count = 0
for i in range(2):
for j in range(2):
axes[i, j].imshow(resize(generated_images[count], (64,64)))
axes[i, j].axis('off')
count += 1
plt.show()
# We save every 100 steps
if step % 100 == 0:
gan.save_weights('dcgan.h5')
print('discriminator loss:', d_loss)
print('advesarial loss:', a_loss)
Results
好的,让我们愉快的开始吧! 我们将开始在不同的平均点上可视化生成的图像。 在我们这样做之前,让我告诉你,这是上述模型的结果,他训练了20000步(迭代)并训练了30000步。 该模型训练约7小时(每小时约4300步)。 我会将较少的步骤模型命名为Model-A,将另一个命名为Model-B。
开始了!
How to read
N~(x,y):通过遵循具有平均值x和标准偏差y的正态分布随机生成的潜在向量
模型A上N~(0,0.4)的潜在载体结果:

Image 5 : Generated Face Model-A N ~ (0, 0.4)
不错吧,虽然有一些图像有不对称的脸。
模型A上N~(0,1)上潜在载体的结果:
Image 6 : Generated Face Model-A N ~ (0, 1)
看看它…模型产生了一些憎恶的面孔。 事实证明,该模型并未真正掌握实际数据的分布。 当标准偏差较低时,它可以做得更好。 我训练的DCGAN还没有掌握如何表示不太接近平均点的数据点。 我认为,它需要更多的培训或更强大的架构。
让我们将架构更改为Model-B
模型-B上N~(0,0.4)的潜在载体结果:

Image 7 : Generated Face Model-B N ~ (0, 0.4)
没关系,但脸色变暗了。 我想知道发电机发生了什么事。
模型-B上N~(0,1)的潜在载体结果:
Image 8 : Generated Face Model-A N ~ (0, 1)
嗯,好吧…他们中的大多数仍然包含着憎恶的面孔。 他们中的一些人制作了好脸色。 质量仍然与Model-A几乎相同。 好的…对于下一批图像,让我们将标准差改变为接近平均值。 0.4将是最好的。
让我们检查我们的潜在向量是否使用相同的标准偏差生成中心均值为-0.3和0.3。
模型A上N~(-0.3,0.4)的潜在载体结果:

图9:生成的面部模型-A N~(0.3,0.4)
模型A上N~(0.3,0.4)的潜在载体结果:

图10:生成的人脸模型-A N~(-0.3,0.4)
模型-B上N~(-0.3,0.4)的潜在载体结果:

图11:生成的面部模型-B N~(-0.3,0.4)
模型-B上N~(0.3,0.4)的潜在载体结果:

Image 12: Generated Face Model-B N ~ (0.3, 0.4)
See the differences?
是的,看看他们的头发。 在平均0.3时,头发大部分是黑色的(其中一些是棕色的)。 相反,在平均值-0.3时,毛发大部分是黄色的。 是的,我们的模型可以将面部放在相应的点上。 此外,Model-B生成比A更暗的面。
根据我们上面所做的,我们可以直观了解模型的数据分布。
让我们绘制它:
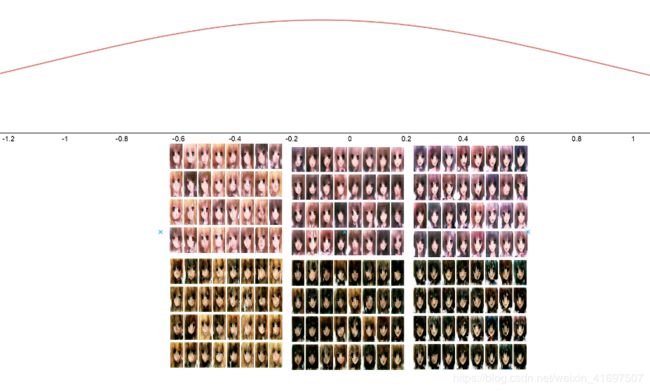
图13:生成器的数据分布
从上面显示的结果来看,我认为潜在的矢量意味着越少,它会使脸部有更亮的头发,潜在的矢量越多,脸部就会有紫色的头发。
为了确保,让我们看看每个平均点的面部平均值:
我们绘制这些潜在的向量,其平均值为:
[-1, -0.8, -0.6, -0.4, -0.2, 0, 0.2 0.4, 0.6, 0.8 ]
means = -1
count = 0
fig, axes = plt.subplots(1, 10, gridspec_kw = {'wspace':0.1, 'hspace':0.1}, figsize=(16,16))
while means < 1 :
random_latent_vectors = np.random.normal(size = (16, latent_dim), loc=means,
scale=0.0)
random_latent_vectors = random_latent_vectors.mean(axis=0)
generated_images = generator.predict(np.array([random_latent_vectors]))
axes[count].set_xticklabels([])
axes[count].set_yticklabels([])
axes[count].imshow(generated_images[0])
axes[count].axis('off')
means += 0.2
count+= 1
plt.show()
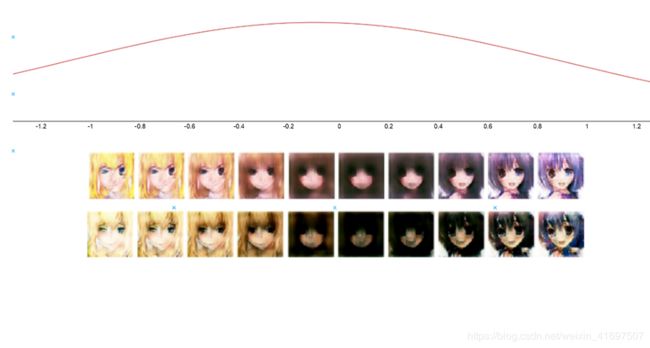
图14:来自不同平均点的平均面部
第一行是MODEL-A,第二行是MODEL-B。 通过操纵潜在向量的平均值,我们可以看到它在该点生成的面。 我们可以看到:
- 矢量点越低,头发越黄。
- 中间有较暗的脸。 这意味着数据集中的平均面具有这些样式。
- 矢量点的正值是,头发更蓝。 积极的潜在载体在微笑时也有更多的张开嘴。
Basic Linear Algebra Operation
Amazing isn’t it?
还没有,我们可以对潜在向量进行线性代数运算。 也可以生成等式的结果并且具有有趣的结果。 在介绍部分之前从我们的第一张面孔中获取结果:
G + D

Images 15 : G + D = GAN
GAN面是G加D的结果。你可以看到头发变得有点棕色。 头发按照右边的D样式和左边的G.
以下是其他操作的结果:
G — D (Absolute)

Images 16 : G-D
Component-Wise multiplied (G, D)

Images 17 : Component-Wise multiplied (G, D)
Manipulate Latent Vectors
如果我们操纵潜在向量中的维度,我们将看到生成的图像是如何生成的。 正如我之前所说,该模型将学习潜在的特征表示。 因此,潜在向量中的每个元素都有生成图像的目的。
要进行可视化,我们将冻结向量中的所有元素并更改要检查的所选维度。

图18:我们在本节中所做的插图
例如,我们想要检查潜在向量中的第一个元素,我们更改该维度并保持其他维度相同。
我们将生成一些在这些点上具有均值的面:
[-0.6, -0.3, 0.1, 0.3, 0.6]
对于每个平均点,我们将生成面,其潜在向量中的维度迭代地使用这些值更改:
[-1.08031934, -0.69714143, -0.39691713, -0.12927146, 0.12927146, 0.39691713, 0.69714143, 1.08031934]
让我们对所选维度进行可视化:(此部分仅使用MODEL-A)
28th dimension:
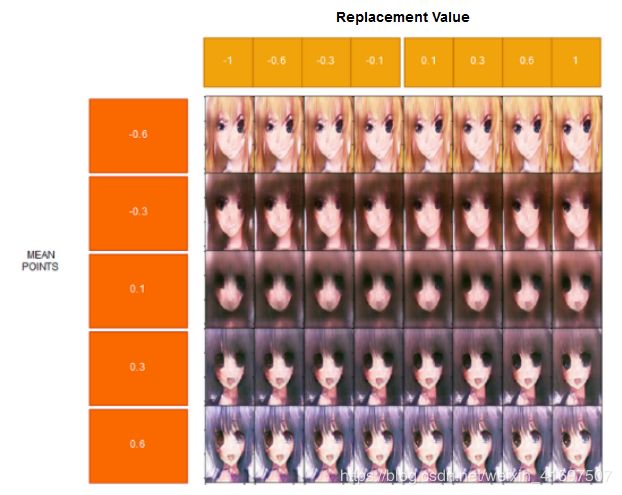
图19:在不同的平均点上改变第28个潜在变量的结果。
第28个潜在变量的目的是什么?
我认为,它会使头发变得更亮,改变左眼的形状,也会改变右眼的微小变化。 由于它将特征压缩为64个长度的潜在向量,因此一个维度可以有多个目的。
让我们看看另一个!
5th dimension
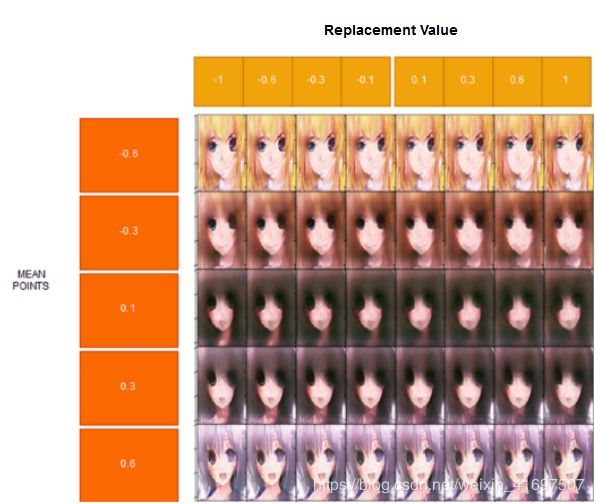
图20:以不同方式改变第5个潜在变量的结果
这个潜在的变量目的是什么?
我认为它与左眼有关,即使对于每个平均点左眼的处理方式也不同。 它也会使头发变得更暗。 你怎么看?
11th dimension
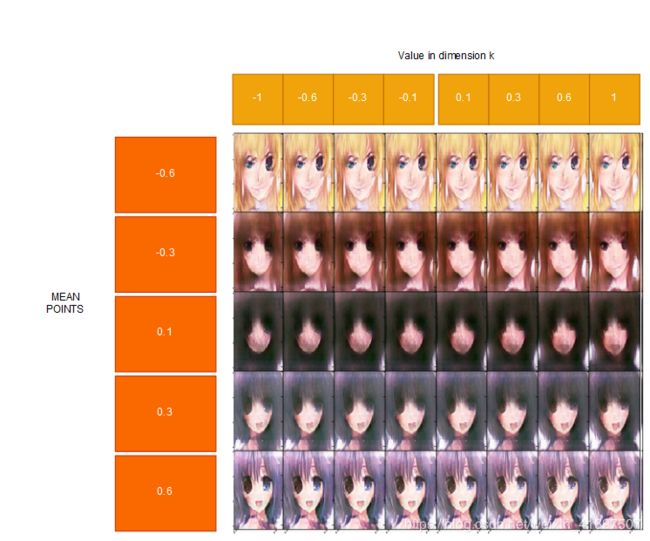
图21:以不同方式改变第11个潜在变量的结果
我认为,这个维度关心的是嘴巴和右眼。
通过仅调整潜在变量从平均点生成的面上的另一个示例:
图22:通过改变潜在变量在面部上得到结果
而已。 我们可以绘制潜在向量中的任何维度,看看它的用途是什么。 虽然有时候很难看出什么是潜在变量的目的。
Compare to Real Data
让我们从数据集中抽取8个真实面:

图22:来自数据集的真面目
对于模型A和B,来自发生器N~(0,1)的样本8:


图23:生成器产生的假面
那么,如果我们充当判别者,我们能否区分真假面孔?
毫无疑问,我们仍然可以区分假面具和真假面。 该模型需要更多的培训或强大的架构才能实现。 即便如此,我们的模型仍然可以生成动漫风格的脸形,这很棒。
Lesson Learned
以下是我在研究DCGAN后学到的课程:
训练GAN很难。 如果没有看到经验丰富的提示和技巧,那么制作一个稳定的架构很难。 特别是在平衡鉴别器和发生器的功率上。 使GAN不会崩溃也是一个挑战。

Photo by Pablo Merchán Montes on Unsplash
实际上,这些模型仍然不擅长生成假图像。尽管如此,它可以建立一些好的面孔,虽然不如真正的面孔。我们仍然可以区分假图像和真实图像。这是因为该模型尚未掌握实际数据的数据分布。
该模型使其质量降低约26000步。在我的实验中,发电机变弱了。这是GAN的不稳定性。我需要搜索更好的架构才能做到这一点。我们可以看到模型B上的结果变得更暗。
因此,我开发了另一种具有批量标准化甚至是Dropout Layer的架构。你猜怎么着?调整架构有两个结果。模型崩溃和判别主导。我想开发GAN架构并不容易。
然而,有很多关于开发我尚未实现的优秀GAN的提示和技巧。可能通过遵循这些提示可以减少模型的不稳定性。
有许多更稳定的GAN变体,例如WGAN-DC和DRAGAN,以及SAGAN。我需要使用可能比DCGAN做得更好的不同架构。
Conclusion
本文告诉我们GAN正在做什么,并逐步告诉我们如何做到这一点。 之后,它告诉我们潜在向量的一个有趣特征,它显示了生成器学习的数据分布。 它告诉我们它可以形成数据分布。
潜在向量可以是线性代数操作。 它可以向我们展示一些有趣的东西,例如添加两个潜在的向量将组合这些面的每个特征。 还可以操纵它以基于潜在向量中的改变的元素来改变面部。
即便如此,我们的模型仍然不能让我们想到那张脸是否是假的。 它仍然可以形成动漫风格的面孔。
Afterwords
Photo by Lemuel Butler on Unsplash
就是这样,我第一次做GAN的经历。我更好地掌握GAN正在做的事情。我也想探讨我对GAN学到的东西的好奇心。他们在那里,实际上真的很棒。生成器可以将由正常随机噪声生成的随机向量映射到数据分布中。它将面聚类到指定的数据点。
在做GAN时,我实际上运行了几个我手工制作的模型。好吧,他们惨遭失败。有一次我认为模型可以成功,但它进入模式崩溃(无论潜在向量如何,预测的面都是相同的)。我找到了关于DCGAN的fchollet存储库并遵循其架构。
由于这是我第一次设计GAN,我期待大家对此有很多反馈。只要指出我已经做过的错误,因为这是我第一次这样做。如果结果不那么好,请原谅我。我只想分享我对做GAN的兴奋。并分享如何做到这一点。
即便如此,它真的很有趣,我想尝试另一种GAN变体,如WGAN-GP,DRAGAN或SAGAN。我只是略微浏览了一下他们想要的东西,并想尝试一下。期待一篇文章做这些实验?。
这个模因实际上描绘了这个实验?。