第六章:使用QueryDSL的聚合函数
在企业级项目开发过程中,往往会经常用到数据库内的聚合函数,一般ORM框架应对这种逻辑问题时都会采用编写原生的SQL来处理,而QueryDSL完美的解决了这个问题,它内置了SQL所有的聚合函数下面我们简单介绍我们常用的几个聚合函数。
本章目标
基于SpringBoot平台整合QueryDSL完成常用聚合函数使用。
构建项目
我们使用idea来创建一个SpringBoot项目,pom.xml配置文件依赖如下所示:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.yuqiyu.querydsl.samplegroupId>
<artifactId>chapter6artifactId>
<version>0.0.1-SNAPSHOTversion>
<packaging>warpackaging>
<name>chapter6name>
<description>Demo project for Spring Bootdescription>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>1.5.4.RELEASEversion>
<relativePath/>
parent>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8project.reporting.outputEncoding>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jpaartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<scope>runtimescope>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.0.26version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.15version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-tomcatartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>com.querydslgroupId>
<artifactId>querydsl-jpaartifactId>
<version>${querydsl.version}version>
dependency>
<dependency>
<groupId>com.querydslgroupId>
<artifactId>querydsl-aptartifactId>
<version>${querydsl.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.16.16version>
dependency>
<dependency>
<groupId>javax.injectgroupId>
<artifactId>javax.injectartifactId>
<version>1version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
<plugin>
<groupId>com.mysema.mavengroupId>
<artifactId>apt-maven-pluginartifactId>
<version>1.1.3version>
<executions>
<execution>
<goals>
<goal>processgoal>
goals>
<configuration>
<outputDirectory>target/generated-sources/javaoutputDirectory>
<processor>com.querydsl.apt.jpa.JPAAnnotationProcessorprocessor>
configuration>
execution>
executions>
plugin>
plugins>
build>
project>上面内的QueryDSL这里就不多做讲解了,如有疑问请查看第一章:Maven环境下如何配置QueryDSL环境。
创建数据表
下面我们来创建一个张数据表来讲解本章的内容,表结构如下所示:
/*
Navicat MariaDB Data Transfer
Source Server : local
Source Server Version : 100108
Source Host : localhost:3306
Source Database : test
Target Server Type : MariaDB
Target Server Version : 100108
File Encoding : 65001
Date: 2017-07-13 15:57:37
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for users
-- ----------------------------
DROP TABLE IF EXISTS `users`;
CREATE TABLE `users` (
`u_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键编号',
`u_username` varchar(50) CHARACTER SET utf8 DEFAULT NULL COMMENT '用户名',
`u_age` int(10) DEFAULT NULL COMMENT '年龄',
`u_score` double(8,2) DEFAULT NULL COMMENT '积分',
PRIMARY KEY (`u_id`)
) ENGINE=MyISAM AUTO_INCREMENT=5 DEFAULT CHARSET=latin1;
-- ----------------------------
-- Records of users
-- ----------------------------
INSERT INTO `users` VALUES ('1', 'admin', '12', '45.70');
INSERT INTO `users` VALUES ('2', 'hengyu', '23', '56.40');
INSERT INTO `users` VALUES ('3', 'test', '22', '67.80');
INSERT INTO `users` VALUES ('4', 'jocker', '25', '99.00');
我们简单创建了一张用户信息表,表内的年龄、积分是我们本章主要使用到的字段,下面我们就开始来讲解本章的内容。
创建实体
我们对应数据库内的表结构创建我们需要的实体并添加JPA的映射,实体代码如下所示:
package com.yuqiyu.querydsl.sample.chapter6.bean;
import lombok.Data;
import javax.persistence.*;
/**
* ========================
* Created with IntelliJ IDEA.
* User:恒宇少年
* Date:2017/7/12
* Time:10:58
* 码云:http://git.oschina.net/jnyqy
* ========================
*/
@Entity
@Table(name = "users")
@Data
public class UserBean
{
@Id
@GeneratedValue
@Column(name = "u_id")
private Long id;
@Column(name = "u_username")
private String name;
@Column(name = "u_age")
private int age;
@Column(name = "u_score")
private double socre;
}如果对@Data注解有疑问,大家可以去GitHub查一下lombok开源项目。
我们的实体已经创建完成,下面我们开始使用maven compile命令完成QueryDSL查询实体的创建,我们找到Maven Projects窗口,展开Lifecyle组,双击compile命令即可,如下图1所示:
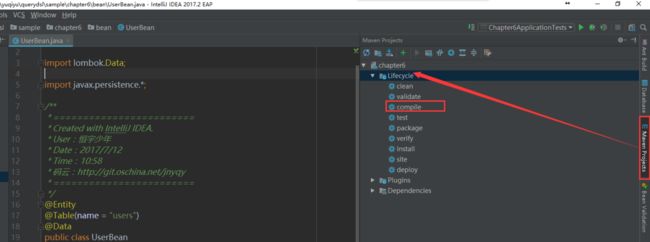
查看控制台输出Build Success表示项目构建完成,我们就可以在target/generated-sources/java目录下看到自动生成的查询实体源码。
创建控制器
本章创建控制器的方法与前几章一致,采用@PostConstruct来初始化JPAQueryFactory实体对象,控制器代码如下所示:
package com.yuqiyu.querydsl.sample.chapter6.controller;
import com.querydsl.jpa.impl.JPAQueryFactory;
import com.yuqiyu.querydsl.sample.chapter6.bean.UserBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.PostConstruct;
import javax.persistence.EntityManager;
import java.util.List;
/**
* ========================
* Created with IntelliJ IDEA.
* User:恒宇少年
* Date:2017/7/12
* Time:10:59
* 码云:http://git.oschina.net/jnyqy
* ========================
*/
@RestController
public class UserController
{
//实体管理对象
@Autowired
private EntityManager entityManager;
//queryDSL,JPA查询工厂
private JPAQueryFactory queryFactory;
//实例化查询工厂
@PostConstruct
public void init()
{
queryFactory = new JPAQueryFactory(entityManager);
}
}下面我们开始编写聚合函数代码。
Count函数
我们现在的需求是查询用户表内的总条数,控制器方法代码如下所示:
/**
* count聚合函数
* @return
*/
@RequestMapping(value = "/countExample")
public long countExample()
{
//用户查询实体
QUserBean _Q_user = QUserBean.userBean;
return queryFactory
.select(_Q_user.id.count())//根据主键查询总条数
.from(_Q_user)
.fetchOne();//返回总条数
}可以看到我们根据id这个字段进行了count聚合,当然我们也可以根据实体内任意字段进行count聚合,我们一般会根据主键来进行聚合,因为主键默认有索引,效率会更高。
这里要注意一点,我们使用的fetchOne方法返回的类型完全是根据select方法内单个参数的类型对应的。
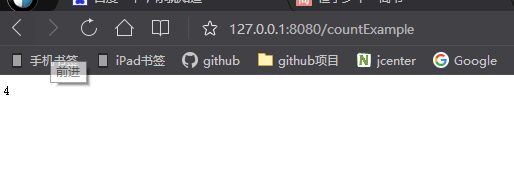
下面我们来启动项目测试下我们这个count聚合是否有效,项目启动完成后我们访问地址http://127.0.0.1:8080/countExample,界面输入内容如下图2所示:
我们再来看下控制台输出的生成SQL是否为我们预期的效果,SQL如下所示:
Hibernate:
select
count(userbean0_.u_id) as col_0_0_
from
users userbean0_可以看到QueryDSL自动生成的SQL跟我们预期的是一样的,我又被QueryDSL的方便深深的折服了。
Sum函数
接下来我们需要查询所有用户分数总和,代码如下所示:
/**
* sum聚合函数
* @return
*/
@RequestMapping(value = "/sumExample")
public double sumExample()
{
//用户查询实体
QUserBean _Q_user = QUserBean.userBean;
return queryFactory
.select(_Q_user.socre.sum())//查询积分总数
.from(_Q_user)
.fetchOne();//返回积分总数
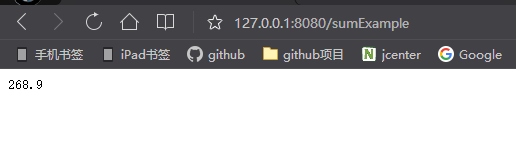
}我们重启项目测试我们的sum聚合函数是否能够查询出总分数,访问地址http://127.0.0.1:8080/sumExample界面输出内容如下图3所示:
我们再来查看下控制台输出的生成SQL,如下所示:
Hibernate:
select
sum(userbean0_.u_score) as col_0_0_
from
users userbean0_也是没问题的,很智能,可谓是指哪打哪。
Avg函数
下面我们又有新的需求了,需要查询下积分的平均值,代码如下所示:
/**
* avg聚合函数
* @return
*/
@RequestMapping(value = "/avgExample")
public double avgExample()
{
//用户查询实体
QUserBean _Q_user = QUserBean.userBean;
return queryFactory
.select(_Q_user.socre.avg())//查询积分平均值
.from(_Q_user)
.fetchOne();//返回平均值
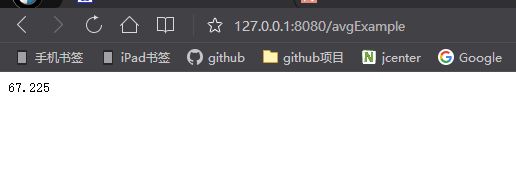
}访问映射地址界面输出内容如下图4所示:
我们再来看下控制台输出的SQL,如下所示:
Hibernate:
select
avg(userbean0_.u_score) as col_0_0_
from
users userbean0_可以看到QueryDSL自动根据积分字段进行了avg聚合实现。
Max函数
接下来我们来查询用户最大积分值,代码如下所示:
/**
* max聚合函数
* @return
*/
@RequestMapping(value = "/maxExample")
public double maxExample()
{
//用户查询实体
QUserBean _Q_user = QUserBean.userBean;
return queryFactory
.select(_Q_user.socre.max())//查询最大积分
.from(_Q_user)
.fetchOne();//返回最大积分
}我们根据积分字段调用max方法即可获取最大积分,然后调用fetchOne方法就能够返回double类型的最大积分值。我们重启下项目访问路径http://127.0.0.1:8080/maxExample界面输出内容如下图5所示:
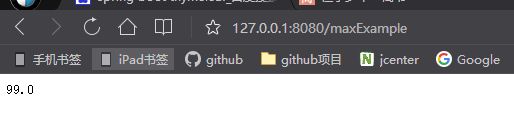
下面再来看下控制台输出的SQL,如下所示:
Hibernate:
select
max(userbean0_.u_score) as col_0_0_
from
users userbean0_到现在为止我们得出来了一个结论,如果原生SQL内聚合函数是作用在字段上,在QueryDSL内使用方法则是查询属性.xxx函数,那么接下来的聚合函数作用域就不是字段了而变成了表。
Group By函数
我们的分组函数该如何使用呢?下面我们根据积分进行分组并且仅查询年龄大于22岁的数据,控制器代码如下所示:
/**
* group by & having聚合函数
* @return
*/
@RequestMapping(value = "/groupByExample")
public List groupByExample()
{
//用户查询实体
QUserBean _Q_user = QUserBean.userBean;
return queryFactory
.select(_Q_user)
.from(_Q_user)
.groupBy(_Q_user.socre)//根据积分分组
.having(_Q_user.age.gt(22))//并且年龄大于22岁
.fetch();//返回用户列表
} 因为Group By函数作用域不是字段而是表,所以会与select、from方法同级,跟原生SQL一样使用Group By进行查询时查询条件不能使用where,而是having!在QueryDSL内也是一样,因为QueryDSL完全遵循了SQL标准。
下面我们重启下项目访问地址http://127.0.0.1:8080/groupByExample看下效果,如下图6所示:
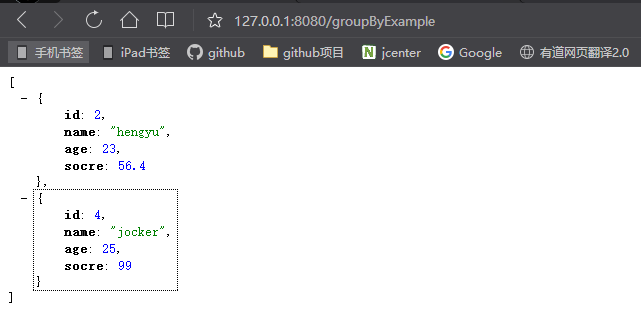
可以看到我们读取到数据是正确的,仅仅查询出了大于22岁的数据。下面我们再来看下控制台输出的SQL如下所示:
Hibernate:
select
userbean0_.u_id as u_id1_0_,
userbean0_.u_age as u_age2_0_,
userbean0_.u_username as u_userna3_0_,
userbean0_.u_score as u_score4_0_
from
users userbean0_
group by
userbean0_.u_score
having
userbean0_.u_age>?可以看到SQL是根据积分字段进行分组并且查询年龄大于22岁的列表。
总结
以上内容就是本章的全部讲解,我们不管是从上面的代码还是之前章节的代码可以得到一个QueryDSL的设计主导方向,QueryDSL完全遵循SQL标准进行设计,SQL内的作用域的关键字在QueryDSL内也是通过,不过展现形式不同罢了。
上面函数不是全部的聚合函数,项目中如果需要其他函数可按照本章的思路去写。
本章代码已经上传码云:
SpringBoot配套源码地址:https://gitee.com/hengboy/spring-boot-chapter
SpringCloud配套源码地址:https://gitee.com/hengboy/spring-cloud-chapter
SpringBoot相关系列文章请访问:目录:SpringBoot学习目录
QueryDSL相关系列文章请访问:QueryDSL通用查询框架学习目录
SpringDataJPA相关系列文章请访问:目录:SpringDataJPA学习目录
感谢阅读!
更多干货文章扫码关注微信公众号

加入知识星球,恒宇少年带你走以后的技术道路!!!
