Algorithms for Hyper-Parameter Optimization译文
仅供参考
论文地址:Algorithms for Hyper-Parameter Optimization
摘要
图像分类基准的最新进展来自于现有技术的更好配置,而不是新的特征学习方法。传统上,超参数优化一直是人类的工作,因为在只有少量试验的情况下,人类的工作会非常有效。目前,计算机集群和GPU处理器可以运行更多的试验,我们表明算法方法可以找到更好的结果。我们也给出了训练神经网络和深信念网络(DBN)任务的超参数优化的结果。我们使用随机搜索和基于预期改进标准的两种新的贪婪顺序方法来优化超参数。随机搜索已被证明对于学习几个数据集的神经网络是足够有效的,但是我们证明它对训练DBN是不可靠的。参考[1]中的顺序算法被应用于最困难的DBN学习问题,并且出现了比之前报道的都要好的结果。 这篇文章提供了用于创建模型 P ( y ∣ x ) P(y | x) P(y∣x)的新技术,且在该模型中,假设许多超参数分配的元素 ( x ) (x) (x)在给定其他元素特定值的情况下是不相关的。
1 介绍
诸如深度置信网络(DBNs)[2],堆叠去噪自动编码器[3],卷积网络[4]以及基于复杂特征提取技术的分类器等模型一般会有10个到大约50个超参数,具体取决于实验者如何对模型进行参数化,以及在合理的默认值下选择多少超参数。调整这些模型时的困难使得发表的结果也难以复制和扩展,甚至使这些方法的原始研究更像是一门艺术而不是一门科学。
[5]、[6]和[7]等最新结果表明,在大型和多层模型中进行超参数优化的困难是科学进步的直接障碍。而这些工作通过在简单算法中使用更协调的超参数优化,使得在图像分类问题上具有更先进的展现性能,而不是通过对建模或机器学习策略的创新。从[5]这样的结果得出特征学习无用的结论同样是错误的。相反,超参数优化应该被视为学习过程中的一个正式的外部循环。作为一个从数据到分类器的学习算法(以分类问题为例),应该包括预算选择多少CPU周期用于超参数探索,以及多少CPU周期用于评估每个超参数选择(即通过调整正则参数)。 [5]和[7]的结果表明,对于诸如大型计算机集群和GPU的当代硬件而言,CPU周期的最佳分配应该包括比在机器学习文献中推荐的还要多的超参数探索。
超参数优化是在图结构配置空间上优化损失函数的问题。在这项工作中,我们将限制在树状结构的配置空间中。配置空间是树结构的,因为一些叶子变量(例如DBN第二层中隐藏单元的数量)只有在节点变量(例如,使用多少层的离散选择)有具体值时才能很好地定义值。超参数优化算法不仅必须优化离散,有序和连续的变量,而且必须同时选择要优化的变量。
在这项工作中,我们定义了一个配置空间的生成过程,以提取有效的样本。随机搜索是从这个过程中提取超参数并对其求值的算法。优化算法的工作原理是识别可以提取的超参数,并根据其他点的损失函数值来确定这些超参数值。本文做的贡献有两点:1)随机搜索与[1]中DBNs的人工优化相比具有竞争力;2)自动顺序优化优于人工和随机搜索。
第2节介绍了基于顺序模型的优化和预计的改进标准。第3节介绍了一种基于高斯过程的超参数优化算法。第4节介绍了基于自适应Parzen窗口的第二种方法。第5节描述了DBN超参数优化的问题,并展示了随机搜索的效率。第6节显示了根据随机搜索对两个最难的数据集进行顺序优化的效率。本文最后在第7节和第8节对研究结果和结论进行了讨论。
2 时序模型的全局优化
时序模型的全局优化(SMBO)算法中广泛使用在适应度函数计算代价高昂的应用中[8,9]。在真实适应度函数 f : X → R f:X→\mathbb{R} f:X→R评估成本高的应用中,可以使用更廉价的基于模型的算法来近似代理 f f f。通常,SMBO算法中的内环是该代理的数值优化,或代理的某些变换。使代理函数(或其变换)最大化的点 x ∗ x^* x∗成为求函数 f f f值的地方。图1总结了这个类似主动学习的算法模板。SMBO算法的不同之处在于它们在给定 f f f的模型(或替代)的情况下优化以获得 x x x的标准,并且在它们通过观察历史 H H H模型 f f f中。
图1:泛型顺序模型优化的伪代码。

本文算法对期望改进准则(EI)[10]进行了优化。也有其他的标准被提出,例如概率改进和期望改进[10],最小化最小化器的条件熵[11],以及[12]中描述的基于强盗的标准。我们选择在我们的工作中使用EI标准,因为它很直观,并且已经在各种环境中显示出良好的效果。我们打算在未来的工作中进行改进标准的系统探索。期望改进是在 f : X → R N f:X→\R^N f:X→RN的某个模型M下的输出 f ( x ) f(x) f(x)将超过(负)某个阈值 y ∗ y^* y∗:
![取自[Algorithms for Hyper-Parameter Optimization]](http://img.e-com-net.com/image/info8/fa14a2a3187c47e897e3ea1e3c7a282f.jpg)
这项工作的贡献是提出了两种通过建模 H H H近似 f f f的新策略:一种是分层高斯过程,另一种是树形结构的Parzen估计。
3 高斯过程法(GP)
在基于模型的优化文献中,高斯过程一直被认为是一种很好的损失函数建模方法。高斯过程(GPs,[14])是在采样时关闭函数的先验,这意味着如果 f f f的先验分布被认为是具有均值0和核k的GP,则可以知道 f f f的条件分布样本 H = ( x i , f ( x i ) ) i = 0 n H =(x_i,f(x_i))^n_{i=0} H=(xi,f(xi))i=0n的值也是GP,其均值和协方差函数可以通过分析推导出来。原则上可以使用具有一般均值函数的GPs,但是对于我们的目的而言,仅考虑零均值过程会更简单和充分。我们通过将函数值集中在所考虑的数据集中来实现它。建模时,例如GP平均值的线性趋势会导致SMBO期间未开发区域外推。
上述的封闭性,加上GPs针对数据稀缺性的影响提供了预测不确定性的评估,使得GP成为寻找候选 x ∗ x^* x∗(图1,步骤3)和拟合模型 M t M_t Mt(图1,步骤6)的理想候选。GP方法每次迭代的运行时间都以 ∣ H ∣ |H| ∣H∣为单位进行三次伸缩,并以优化变量的数量为单位进行线性伸缩,但是函数求值 f ( x ∗ ) f(x^*) f(x∗)的开销通常甚至会主导这个三次开销。
3.1 在GP中优化EI
我们用GP对 f f f进行建模,并将 y ∗ y^* y∗设置为观察到 H H H后得到的最佳值: y ∗ = m i n { f ( x i ) , 1 ≤ i ≤ n } y^* = min \{f(x_i),1≤i≤n\} y∗=min{f(xi),1≤i≤n}。然后,(1)中的模型 p M p_M pM是知道 H H H的后验GP。(1)中的EI函数封装了均值函数接近或优于 y ∗ y^* y∗的区域和不确定度高的未开发区域之间的折衷。
EI函数通常通过在输入空间上进行穷举网格搜索或在更高维度上进行拉丁超立方体搜索来优化。然而,关于EI标准的一些信息可以从简单的计算中得到[16]:1)它总是非负的,在 D D D中的某些训练点上为零,2)它继承了核 k k k的平滑性,即在实践中至少有一次是可微分的,3)EI标准可能是高度多模态的,特别是当训练点数增加时。[16]的作者使用前面关于EI性质的言论设计了一种混合搜索的进化算法,专门用于优化EI,结果表明,在EI评估中,对于给定的预算,该算法的搜索性能优于穷举搜索。我们借用了他们的方法,并作更进一步的研究。我们在输入空间的离散部分(确定的离散超参数)上保持分布估计(EDA,[17])方法,其中我们根据二项分布对候选点进行采样,同时我们使用协方差矩阵自适应 - 进化 战略(CMA-ES,[18])用于我们输入空间的剩余部分(连续超参数)。CMA-ES是一种用于连续域优化的最先进的无梯度进化算法,已被证明优于高斯搜索EDA。请注意,这种无梯度的方法允许GP回归使用不可微分的内核。我们没有使用[16]中的混合搜索,而是多次从有希望的地方重新启动本地搜索。[16]建议使用的镶嵌方法在这里是禁止的,因为我们的任务通常意味着10个维度以上的工作,因此我们在单纯的质心开始每个局部搜索,在训练点中随机选取顶点。
最后,我们注意到所有超参数都与每个点无关。例如,仅具有一个隐藏层的DBN没有与第二层或第三层相关联的参数。因此,在超参数的整个空间上放置一个GP是不够的。我们选择以树状的方式将常用的超参数分组,并在每个组上放置不同的独立GPs。例如,对于DBN,这意味着将一个GP放在常见的超参数上,包括指示要考虑的条件组的分类参数,与三个层中的每一个对应的参数上的三个GP,以及几个一维GP 单个条件超参数,如ZCA能量(DBN参数见表1)。
4 树形结构Parzen估计方法(TPE)
考虑到我们的超参数优化任务将意味着高维和小的适应度评估预算,我们现在转向SMBO算法的另一种建模策略和EI优化方案。基于高斯过程的方法直接建模 p ( y ∣ x ) p(y|x) p(y∣x),而这种策略建模 p ( x ∣ y ) p(x|y) p(x∣y)和 p ( y ) p(y) p(y)。
回想一下在介绍中,配置空间 X X X是由图形结构生成过程描述的(例如,首先选择若干DBN层,然后为每个DBN层选择参数)。树状结构的Parzen估计量(TPE)通过转换生成过程,用非参数密度代替构型先验的分布,为 p ( x ∣ y ) p(x|y) p(x∣y)建模。在实验部分,我们将看到配置空间是使用均匀的、对数均匀的、量化均匀的、分类的变量来描述的。在这些情况下,TPE算法进行以下替换:均匀→截断高斯混合,对数均匀→取幂截断高斯混合,分类→重新加权分类。在非参数密度下使用不同的观测值 { x ( 1 ) , … , x ( k ) } \{x(1),…,x(k)\} {x(1),…,x(k)},这些替换代表了一种学习算法,可以在构型空间 X X X上产生不同的密度。TPE用以下两个密度定义了 p ( x ∣ y ) p(x|y) p(x∣y):
![取自[Algorithms for Hyper-Parameter Optimization]](http://img.e-com-net.com/image/info8/04323690f99a4f9ab2e2d962f9ad8307.jpg)
其中 l ( x ) l(x) l(x)为观测值 { x ( i ) } \{x^{(i)}\} {x(i)}所形成的密度,使得对应的损失 f ( x ( i ) ) f(x^{(i)}) f(x(i))小于 y ∗ y^* y∗, g ( x ) g(x) g(x)为剩余观测值所形成的密度。虽然基于GP的方法更倾向于表现很好的 y ∗ y^* y∗(通常小于最佳观测损失),但是TPE算法依赖于大于最佳观测 f ( x ) f(x) f(x)的 y ∗ y^* y∗,因此一些点可以用来形成 l ( x ) l(x) l(x)。TPE算法选择 y ∗ y^* y∗为观测到的 y y y值的一些分位数 γ γ γ,使得 p ( y < y ∗ ) = γ p(y <y^*)=γ p(y<y∗)=γ,但不需要 p ( y ) p(y) p(y)的特定模型。通过维护 H H H中观测变量的有序列表,TPE算法每次迭代的运行时可以在 ∣ H ∣ |H| ∣H∣中线性伸缩,并且在优化的变量个数(维数)中线性伸缩。
4.1 优化TPE算法中的EI
将TPE算法中的参数 p ( x , y ) p(x, y) p(x,y)化为 p ( y ) p ( x ∣ y ) p(y)p(x|y) p(y)p(x∣y),便于EI的优化。
![]()
通过构造, γ = p ( y < y ∗ ) γ=p(y<y^*) γ=p(y<y∗) 并且 p ( x ) = ∫ R p ( x ∣ y ) p ( y ) d y = γ ( x ) + ( 1 − γ ) g ( x ) p(x)=\int_R p(x|y)p(y)dy=γ(x)+(1−γ)g(x) p(x)=∫Rp(x∣y)p(y)dy=γ(x)+(1−γ)g(x)。从而, ∫ − ∞ y ∗ ( y ∗ − y ) p ( x ∣ y ) p ( y ) d y = l ( x ) ∫ − ∞ y ∗ ( y ∗ − y ) p ( y ) d y = γ y ∗ l ( x ) − l ( x ) ∫ − ∞ y ∗ p ( y ) d y \int_{-\infty }^{y^*} (y^*−y)p(x|y)p(y)dy=l(x)\int_{-\infty}^{y^*}(y^*−y)p(y)dy=γy^*l(x)−l(x)\int_{-\infty}^{y^*}p(y)dy ∫−∞y∗(y∗−y)p(x∣y)p(y)dy=l(x)∫−∞y∗(y∗−y)p(y)dy=γy∗l(x)−l(x)∫−∞y∗p(y)dy,最后得到 E I y ∗ ( x ) = γ y ∗ l ( x ) − l ( x ) ∫ − ∞ y ∗ p ( y ) d y γ ( x ) + ( 1 − γ ) g ( x ) ∝ ( γ + g ( x ) l ( x ) ( 1 − γ ) ) − 1 EI_{y^*}(x)=\dfrac {γy^*l(x)−l(x)\int_{-\infty}^{y^*}p(y)dy}{γ(x)+(1−γ)g(x)} \propto (γ+\dfrac{g(x)}{l(x)}(1-γ))^{-1} EIy∗(x)=γ(x)+(1−γ)g(x)γy∗l(x)−l(x)∫−∞y∗p(y)dy∝(γ+l(x)g(x)(1−γ))−1。最后的表达式表明,为了最大化改进,我们希望点 x x x在 l ( x ) l(x) l(x)下具有高概率,在 g ( x ) g(x) g(x)下具有低概率。 树形结构形式的 l l l和 g g g使得根据 l l l来绘制许多候选者变得容易,并且可以根据 g ( x ) / l ( x ) g(x)/ l(x) g(x)/l(x)来评估它们。 在每次迭代时,算法返回具有最大EI的候选 x x x。
4.2 Parzen估计的细节
模型 l ( x ) l(x) l(x)和 g ( x ) g(x) g(x)是包含离散值和连续值变量的分层过程。自适应Parzen估计量通过将密度放置在 K K K个观测值 B = { X ( 1 ) , … , X ( K ) } ∝ H B=\{X(1),…,X (K)\}\propto H B={X(1),…,X(K)}∝H附近得到一个 X X X上的模型。每一个连续的超参数都由一个均匀先验或高斯分布或对数均匀分布在某个区间 ( a , b ) (a, b) (a,b)指定。TPE用以 x ( i ) ∝ B x^{(i)}\propto B x(i)∝B为中心的高斯分布代替先验分布的等权混合分布。每个高斯分布的标准差被设置为左右邻域之间的较大距离,但被截断以保持在合理范围内。在均匀的情况下,点 a a a和点 b b b被认为是潜在的邻居。对于离散变量,假设先验是一个有 N N N个概率 p i p_i pi的向量,后验向量元素与 N p i + C i N_{p_i} +C_i Npi+Ci成比例,其中 C i C_i Ci是选项 i i i在 B B B中的出现次数。将对数均匀超参数作为对数域内的均匀参数。
表1:随机抽样的DBN超参数分布。由预处理(包括随机种子)分隔的选项的权重相等。符号 U U U表示均匀, N N N表示高斯分布, l o g U logU logU表示在对数域中均匀分布。CD(也称为CD-1)代表对比发散,该算法用于初始化DBN的层参数。

5 DBN中的超参数优化:随机搜索
实现超参数优化的一个简单但有效的步骤是使用随机搜索[5]。[19]表明,在优化单层神经网络分类器参数时,随机搜索比网格搜索效率高得多。在本节中,通过与[1]中顺序网格辅助手工搜索比较,我们评估了DBN优化的随机搜索。
我们选择表1中先前列出的选项来定义DBN配置上的搜索空间。[1]提供了数据集的详细信息、DBN模型和基于CD的贪婪分层训练过程。这个先验对应于[1]的搜索空间,除了以下不同:(a)我们允许ZCA预处理[20],(b)我们允许每一层有不同的大小,©我们允许每一层有自己的CD训练参数,(d)我们允许将连续值数据作为CD算法中伯努利均值(理论上更正确)或伯努利样本(更典型)处理的可能性,(e)我们没有离散实值超参数的可能值。这些更改扩展了超参数搜索问题,同时将原始的超参数搜索空间作为扩展搜索空间的子集。
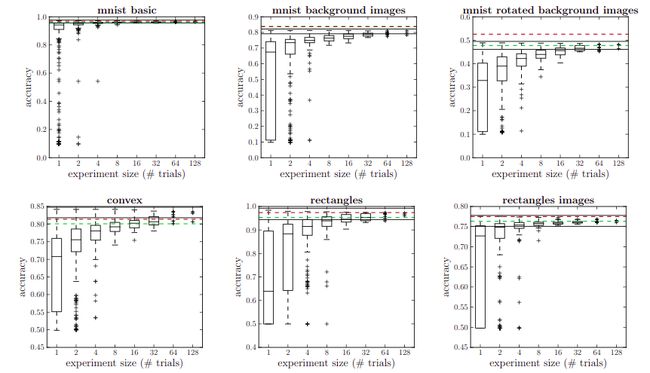
这个初步随机搜索的结果如图2所示。也许令人惊讶的是,手工搜索的结果可以可靠地与32个针对多个数据集的随机试验匹配。在[21]中进一步探讨了这种情况下随机搜索的效率。在随机搜索结果与人类性能匹配的情况下,从图2中并不清楚原因是搜索原始空间的效率一样高,还是搜索更大的空间更容易找到性能较好的空间。但是随机搜索通过搜索更大的空间以某种方式作弊的反对意见是反向的 – 表1中概述的搜索空间是超参数优化问题的自然描述,并且[1]对该空间的限制可能简化搜索问题,使其易于网格搜索辅助手动搜索。 关键的地方是,这两种方法都在相同的数据集上训练DBN。
图2中的结果表明,对于某些数据集,超参数优化更加困难。例如,在MNIST旋转背景图像数据集(MRBI)的情况下,随机抽样似乎相对较快地收敛到最大值(32个试验中的最佳模型在性能上的差异很小),但这个平台低于人工搜索发现的值。在另一个数据集(convex)中,随机抽样过程的性能超过了手工搜索,但收敛到任何一种平台都很慢。当选取32个模型中最好的模型时,泛化有很大的差异。这种缓慢的收敛表明性能可能更好,但是我们需要更有效地搜索配置空间来找到它。本文的其余部分探讨了convex和MRBI这两个数据集超参数优化的顺序优化策略。
6 DBN中的超参数优化:顺序搜索
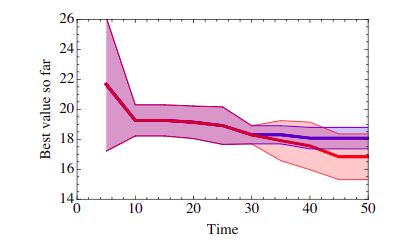
我们通过与波士顿住房数据集上的随机抽样进行比较,验证了3.1节中的GP方法,该数据集是一个由13个缩放输入变量组成的506个点的回归任务,以及一个标量回归输出。我们训练了一个具有10个超参数的多层感知器(MLP),包括学习速度、 l 1 l_1 l1和 l 2 l_2 l2惩罚、隐层大小、迭代次数、是否应用PCA预处理,其能量是唯一的条件超参数。我们的结果如图3所示。前30次迭代使用随机抽样,从30次开始,我们将随机样本与基于更新历史的GP方法进行区分。实验重复20次。虽然与维度相比,点的数量特别少,但是代理建模方法发现的点明显好于随机搜索,这表明可以将SMBO方法应用于更难的任务和数据集。
将遗传算法应用于DBN性能优化问题,我们允许每个提案 x ∗ x^* x∗随机重启CMA+ES算法3次,并通过多达500次的共轭梯度法迭代拟合遗传算法的长度尺度。每个节点都使用平方指数核。GPs的CMA-ES部分采用惩罚法处理边界,二项采样部分采用自然法处理边界。该GP算法在 H H H中以30个随机采样点初始化,经过200次试验,使用该GP对 x ∗ x^* x∗点的预测时间约为150秒。
对于基于TPE的算法,我们选择 γ = 0.15 γ= 0.15 γ=0.15并且在每次迭代中从 l ( x ) l(x) l(x)中抽取的100个候选中的最佳选择作为提议 x ∗ x^* x∗。 在200次试验之后,使用该TPE算法预测点 x ∗ x^* x∗需要大约10秒。在优化过程中允许TPE增长超过随机抽样的初始界限,而GP和随机搜索在优化过程中被限制在初始界限内。TPE算法也初始化了与GP种子相同的30个随机采样点。
6.1 并行化顺序搜索
GP和TPE方法实际上是异步运行的,以便利用多个计算节点并避免浪费时间等待试验评估完成。 对于GP方法,使用所谓的恒定谎言方法:每次提出候选点 x ∗ x^* x∗时,临时分配等于训练集 D D D中 y y y的平均值的假适应性评估,直到评价完成并报告实际损失 f ( x ∗ ) f(x^*) f(x∗)。对于TPE方法,我们只是简单地忽略最近提出的点,并依赖于 l ( x ) l(x) l(x)绘制的随机性来提供从一个迭代到下一个迭代的不同候选项。并行化的结果是,每个提案x基于较少的反馈。这使得搜索效率更低,但就经过时间而言速度更快。

每次试验的运行时被限制为1小时的GPU计算,无论在GTX 285、470、480或580上执行。理论上最慢和最快机器的速度差大约是两倍,但实际计算效率也取决于机器的负载和问题的配置(不同超参数配置下不同卡的相对速度不同)。通过GP和TPE算法对多达五个提案的并行评估,每个实验使用五个GPU花费大约24小时的待机时间。