JVM之配置参数详解和调优总结(二)
JVM提供了诸多的参数进行JVM各个方面内存大小的设置,为Java应用进行优化提供了诸多的工具,本文将会详细分析各个参数的功能与使用。
一、JVM内存参数概述
参数作用图:
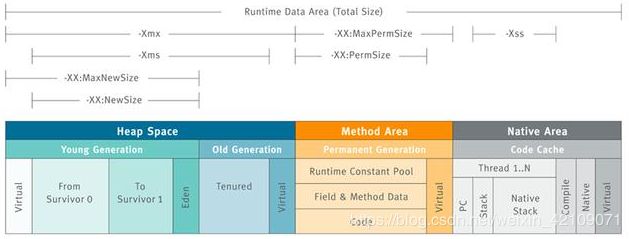
参数详细说明:
| 参数名称 | 含义 | 默认值 | 描述 |
| -Xms | 初始堆大小 | 物理内存的1/64(<1GB) | 默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制. |
| -Xmx | 最大堆大小 | 物理内存的1/4(<1GB) | 默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制 |
| -Xmn | 年轻代大小(1.4or lator) | 注意:此处的大小是(eden+ 2 survivor space).与jmap -heap中显示的New gen是不同的。 整个堆大小=年轻代大小 + 年老代大小 + 持久代大小. 增大年轻代后,将会减小年老代大小.此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8 |
|
| -XX:NewSize | 设置年轻代大小(for 1.3/1.4) | ||
| -XX:MaxNewSize | 年轻代最大值(for 1.3/1.4) | ||
| -XX:PermSize | 设置持久代(perm gen)初始值 | 物理内存的1/64 | |
| -XX:MaxPermSize | 设置持久代最大值 | 物理内存的1/4 | |
| -Xss | 每个线程的堆栈大小 | JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K.更具应用的线程所需内存大小进行 调整.在相同物理内存下,减小这个值能生成更多的线程.但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右 一般小的应用, 如果栈不是很深, 应该是128k够用的 大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。(校长) 和threadstacksize选项解释很类似,官方文档似乎没有解释,在论坛中有这样一句话:"” -Xss is translated in a VM flag named ThreadStackSize” 一般设置这个值就可以了。 |
|
| -XX:ThreadStackSize | Thread Stack Size | (0 means use default stack size) [Sparc: 512; Solaris x86: 320 (was 256 prior in 5.0 and earlier); Sparc 64 bit: 1024; Linux amd64: 1024 (was 0 in 5.0 and earlier); all others 0.] | |
| -XX:NewRatio | 年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代) | -XX:NewRatio=4表示年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5 Xms=Xmx并且设置了Xmn的情况下,该参数不需要进行设置。 |
|
| -XX:SurvivorRatio | Eden区与Survivor区的大小比值 | 设置为8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10 | |
| -XX:LargePageSizeInBytes | 内存页的大小不可设置过大, 会影响Perm的大小 | =128m | |
| -XX:+UseFastAccessorMethods | 原始类型的快速优化 | ||
| -XX:+DisableExplicitGC | 关闭System.gc() | 这个参数需要严格的测试 | |
| -XX:MaxTenuringThreshold | 垃圾最大年龄 | 如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代. 对于年老代比较多的应用,可以提高效率.如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活 时间,增加在年轻代即被回收的概率 该参数只有在串行GC时才有效. |
|
| -XX:+AggressiveOpts | 加快编译 | ||
| -XX:+UseBiasedLocking | 锁机制的性能改善 | ||
| -Xnoclassgc | 禁用垃圾回收 | ||
| -XX:SoftRefLRUPolicyMSPerMB | 每兆堆空闲空间中SoftReference的存活时间 | 1s | softly reachable objects will remain alive for some amount of time after the last time they were referenced. The default value is one second of lifetime per free megabyte in the heap |
| -XX:PretenureSizeThreshold | 对象超过多大是直接在旧生代分配 | 0 | 单位字节 新生代采用Parallel Scavenge GC时无效 另一种直接在旧生代分配的情况是大的数组对象,且数组中无外部引用对象. |
| -XX:TLABWasteTargetPercent | TLAB占eden区的百分比 | 1% | |
| -XX:+CollectGen0First | FullGC时是否先YGC | false |
典型JVM参数配置参考:
- java-Xmx3550m-Xms3550m-Xmn2g-Xss128k
- -XX:ParallelGCThreads=20
- -XX:+UseConcMarkSweepGC-XX:+UseParNewGC
-Xmx3550m:设置JVM最大可用内存为3550M。
-Xms3550m:设置JVM促使内存为3550m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个堆大小=年轻代大小+年老代大小+持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大 小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000 左右。
1.1 堆内存大小配置
设置Java应用最大可用内存为20M, 初始内存为5M(为了方便演示,开发工具用的ecplise)

注意:在配置前,先运行示例代码,否则图上的第4步,会找不到
参数说明:
-Xmx20m -Xms5m完整代码:
public static void main(String[] args) {
//-Xmx20m -Xms5m 最大堆内存为20M 初始堆内存为5M
//在实际工作中,我们可以直接将初始的堆大小与最大堆大小相等,这样的好处是可以减少程序运行时垃圾回收次数,从而提高效率
System.out.println("最大堆大小【-Xmx参数】:"+Runtime.getRuntime().maxMemory() / 1024.0 / 1024 + "M");
System.out.println("初始堆大小【-Xms参数】:"+Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M");
System.out.println("可用内存【无参数】:"+Runtime.getRuntime().freeMemory() / 1024.0 / 1024 + "M");
}输出结果:
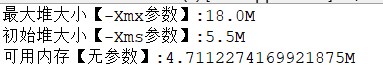
注意:我们设置的参数,控制台只会打印出近似值,因为在代码的运行过程中会出现一些其他的进程(即对内存有影响),影响该结果
1.2 设置新生代比例参数
堆内存初始化值5m,堆内存最大值20m,新生代最大值可用1m,eden空间和from/to空间的比例为2/1
参数说明:
-Xms5m -Xmx20m -Xmn1m -XX:SurvivorRatio=2 -XX:+PrintGCDetails -XX:+UseSerialGC完整代码:
public static void main(String[] args) {
//-Xms20m -Xmx20m -Xmn1m -XX:SurvivorRatio=2 -XX:+PrintGCDetails -XX:+UseSerialGC
System.out.println("最大堆大小【-Xmx参数】:"+Runtime.getRuntime().maxMemory() / 1024.0 / 1024 + "M");
System.out.println("初始堆大小【-Xms参数】:"+Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M");
System.out.println("可用内存【无参数】:"+Runtime.getRuntime().freeMemory() / 1024.0 / 1024 + "M");
System.out.println("===============创建5M大小的字符数组====================");
byte[] b = new byte[5 * 1024 * 1024];
System.out.println("最大堆大小【-Xmx参数】:"+Runtime.getRuntime().maxMemory() / 1024.0 / 1024 + "M");
System.out.println("初始堆大小【-Xms参数】:"+Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M");
System.out.println("可用内存【无参数】:"+Runtime.getRuntime().freeMemory() / 1024.0 / 1024 + "M");
}输出结果
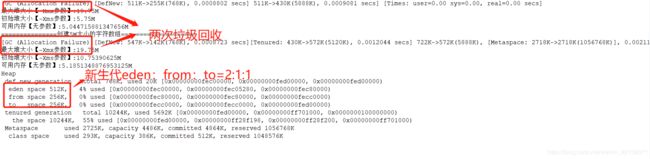
1.3 设置新生代与老年代比例参数
堆内存初始化值20m,堆内存最大值20m,新生代最大值可用1m,eden空间和from/to空间的比例为2/1,新生代和老年代的占比为1/2
参数说明:
-Xms20m -Xmx20m -XX:SurvivorRatio=2 -XX:+PrintGCDetails -XX:+UseSerialGC -XX:NewRatio=2二、实战OutOfMemoryError异常
2.1 Java堆溢出
2.2 虚拟机栈溢出
三、垃圾收集器类型
3.1 serial收集器
串行收集器是最古老,最稳定以及效率高的收集器,可能会产生较长的停顿,只使用一个线程去回收。新生代、老年代使用串行回收;新生代复制算法、老年代标记-压缩;垃圾收集的过程中会Stop The World(服务暂停)。一个单线程的收集器,在进行垃圾收集时候,必须暂停其他所有的工作线程直到它收集结束。
特点:CPU利用率最高,停顿时间即用户等待时间比较长。
适用场景:小型应用
通过JVM参数-XX:+UseSerialGC可以使用串行垃圾回收器。
3.2 ParNew收集器
ParNew收集器其实就是Serial收集器的多线程版本。新生代并行,老年代串行;新生代复制算法、老年代标记-压缩
参数控制:-XX:+UseParNewGC ParNew收集器
-XX:ParallelGCThreads 限制线程数量
3.4 parallel 收集器
Parallel Scavenge收集器类似ParNew收集器,Parallel收集器更关注系统的吞吐量。可以通过参数来打开自适应调节策略,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或最大的吞吐量;也可以通过参数控制GC的时间不大于多少毫秒或者比例;新生代复制算法、老年代标记-压缩
采用多线程来通过扫描并压缩堆
特点:停顿时间短,回收效率高,对吞吐量要求高。
适用场景:大型应用,科学计算,大规模数据采集等。
通过JVM参数 XX:+USeParNewGC 打开并发标记扫描垃圾回收器。
3.5 cms收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。目前很大一部分的Java应用都集中在互联网站或B/S系统的服务端上,这类应用尤其重视服务的响应速度,希望系统停顿时间最短,以给用户带来较好的体验。从名字(包含“Mark Sweep”)上就可以看出CMS收集器是基于“标记-清除”算法实现的,它的运作过程相对于前面几种收集器来说要更复杂一些,整个过程分为4个步骤,包括:
初始标记(CMS initial mark)
并发标记(CMS concurrent mark)
重新标记(CMS remark)
并发清除(CMS concurrent sweep)
其中初始标记、重新标记这两个步骤仍然需要“Stop The World”。初始标记仅仅只是标记一下GC Roots能直接关联到的对象,速度很快,并发标记阶段就是进行GC Roots Tracing的过程,而重新标记阶段则是为了修正并发标记期间,因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。
由于整个过程中耗时最长的并发标记和并发清除过程中,收集器线程都可以与用户线程一起工作,所以总体上来说,CMS收集器的内存回收过程是与用户线程一起并发地执行。老年代收集器(新生代使用ParNew)
优点:并发收集、低停顿
缺点:产生大量空间碎片、并发阶段会降低吞吐量
特点:响应时间优先,减少垃圾收集停顿时间
适应场景:大型服务器等。
采用“标记-清除”算法实现,使用多线程的算法去扫描堆,对发现未使用的对象进行回收。
(1)初始标记
(2)并发标记
(3)并发预处理
(4)重新标记
(5)并发清除
(6)并发重置
通过JVM参数 -XX:+UseConcMarkSweepGC设置
3.6 g1收集器
在G1中,堆被划分成 许多个连续的区域(region)。采用G1算法进行回收,吸收了CMS收集器特点。
特点:支持很大的堆,高吞吐量
--支持多CPU和垃圾回收线程
--在主线程暂停的情况下,使用并行收集
--在主线程运行的情况下,使用并发收集
实时目标:可配置在N毫秒内最多只占用M毫秒的时间进行垃圾回收
通过JVM参数 -XX:+UseG1GC 使用G1垃圾回收器
注意: 并发是指一个处理器同时处理多个任务。
并行是指多个处理器或者是多核的处理器同时处理多个不同的任务。
并发是逻辑上的同时发生(simultaneous),而并行是物理上的同时发生。
来个比喻:并发是一个人同时吃三个馒头,而并行是三个人同时吃三个馒头。
四、Tomcat配置调优测试
4.1 什么是吞吐量
QPS:Queries Per Second意思是“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
4.2 测试串行吞吐量
设置Java应用最大可用内存为20M, 初始内存为5M(为了方便演示,开发工具用的ecplise,demo是servlet的)
-XX:+PrintGCDetails -Xmx32M -Xms2M
-XX:+HeapDumpOnOutOfMemoryError
-XX:+UseSerialGC
-XX:PermSize=32M-Xmx20m -Xms5m 
servlet的代码
public class IndexServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
public IndexServlet() {
super();
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.out.println("起始堆最大内存:"+Runtime.getRuntime().maxMemory()/1024/1024+"M");
System.out.println("起始堆初始内存:"+Runtime.getRuntime().totalMemory()/1024/1024+"M");
System.out.println("起始堆可用内存"+Runtime.getRuntime().freeMemory()/1024/1024+"M");
Byte[] byteArr = new Byte[1*1024*1024];
System.out.println("************程序执行增加了"+byteArr.length/1024/1204+"M*************");
System.out.println("使用后堆最大内存:"+Runtime.getRuntime().maxMemory()/1024/1024+"M");
System.out.println("使用后堆初始内存:"+Runtime.getRuntime().totalMemory()/1024/1024+"M");
System.out.println("使用后堆可用内存"+Runtime.getRuntime().freeMemory()/1024/1024+"M");
// 使用 GBK 设置中文正常显示
response.setCharacterEncoding("GBK");
response.getWriter().write("XXX科技");
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
}启动tomcat,我们可以看到控制台已经输出垃圾回收的信息,大概有27次左右
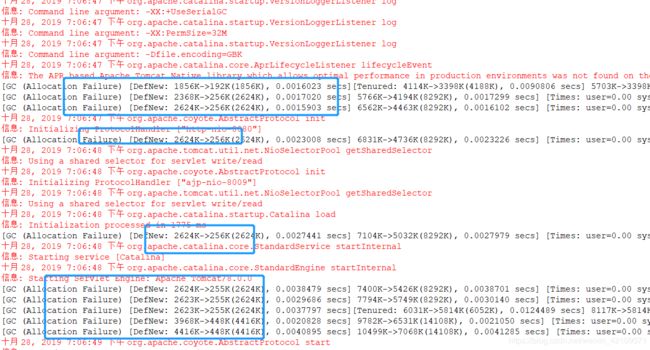
并访问http://localhost:8080/jvmweb002/index,我们又可以看到控制台输出结果,发现又执行了一次垃圾回收
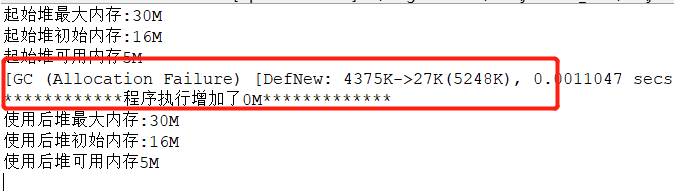
这时候我们在去调整堆内存的初始值将-Xms1M修改为32M
-XX:+PrintGCDetails -Xmx32M -Xms32M
-XX:+HeapDumpOnOutOfMemoryError
-XX:+UseSerialGC
-XX:PermSize=32M我再次启动tomcat,我们可以看到控制台已经输出垃圾回收的信息,大概有6次左右
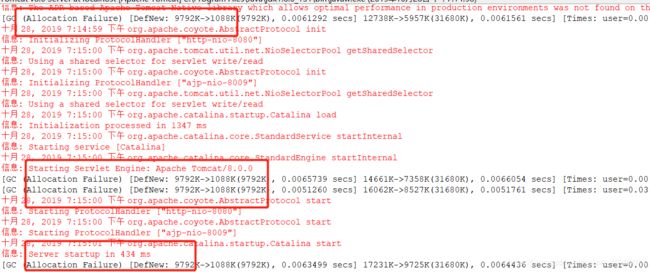
结论:堆的初始值和堆的最大一致,可以提升代码效率
4.2 扩大堆的内存
将之前的-Xmx32m修改为512m
参数说明:
-XX:+PrintGCDetails -Xmx512M -Xms32M
-XX:+HeapDumpOnOutOfMemoryError
-XX:+UseSerialGC
-XX:PermSize=32M启动tomcat,直接看结果
我可以看到,垃圾回收大概也是在6次左右,从而我又得出结论:垃圾回收次数和设置最大堆内存大小无关,只和初始内存有关系。初始内存会影响吞吐量。
4.3 调整初始堆
将-Xms32m修改为512m
-XX:+PrintGCDetails -Xmx512M -Xms512M
-XX:+HeapDumpOnOutOfMemoryError
-XX:+UseSerialGC
-XX:PermSize=32M直接运行代码

结论:堆的初始值和最大堆内存一致,并且初始堆越大代码执行效率就会高。
并行回收(UseParNewGC)
| -XX:+PrintGCDetails -Xmx512M -Xms512M -XX:+HeapDumpOnOutOfMemoryError -XX:+UseParNewGC -XX:PermSize=32M |
| GC回收0次 吞吐量6800 |
CMS收集器 (UseConcMarkSweepGC)
| -XX:+PrintGCDetails -Xmx512M -Xms512M -XX:+HeapDumpOnOutOfMemoryError -XX:+UseConcMarkSweepGC -XX:PermSize=32M |
|
|
G1回收方式(UseG1GC)
| -XX:+PrintGCDetails -Xmx512M -Xms512M -XX:+HeapDumpOnOutOfMemoryError -XX:+UseG1GC -XX:PermSize=32M |
|
|
调优总结
初始堆值和最大堆内存内存越大,吞吐量就越高。
最好使用并行收集器,因为并行收集器速度比串行吞吐量高,速度快。
设置堆内存新生代的比例和老年代的比例最好为1:2或者1:3。
减少GC对老年代的回收。