【MapReduce】表自然连接笔记 Windows环境(HadoopStreaming、mrjob、java api三个版本)
表自然连接
student_course表:(SID, CID, SCORE, TID)
student表:(SID, NAME, SEX, AGE, BIRTHDAY, DNAME, CLASS)
均有表头
思路
根据文件名添加标记,两个表通过mapper分别转换为
查询知,streaming可以通过以下方式获得输入文件名
try:
input_file = os.environ['mapreduce_map_input_file']
except KeyError:
input_file = os.environ['map_input_file'] # 老版本
另一种替代方式是在reducer判断中,根据属性的数目,sc是4个,s是7个。但这样做并不普适。
Hadoop Streaming方式
Windows
请先在本地安装好Hadoop(我尝试过Docker的几个hadoop、mapreduce镜像,都需要再配置,总之有挺多bug没解决成功)
mapper.py
mapper.py
import sys
import os
def mapper():
try:
input_file = os.environ['mapreduce_map_input_file']
except KeyError:
input_file = os.environ['map_input_file']
input_file = os.path.basename(input_file).split('.')[0]
tag = 'sc' if input_file == 'student_course' else 's'
for line in sys.stdin:
data = line.strip().split('\t')
print('\t'.join([data[0]] + [tag] + data[1:]))
mapper()
reducer.py
import sys
def reducer():
ss = []
scs = []
old_key = None
for line in sys.stdin:
l = line.strip().split('\t')
key = l[0]
if old_key and key != old_key:
if ss and scs:
print('\n'.join(['\t'.join([key] + s + sc) for sc in scs for s in ss]))
ss = []
scs = []
old_key = key
if l[1] == 's':
ss.append(l[2:])
else:
scs.append(l[2:])
if old_key and ss and scs:
print('\n'.join(['\t'.join([old_key] + s + sc) for sc in scs for s in ss]))
reducer()
配置一下环境变量(cmd里set是临时的大概,只在该窗口内有效)
C:\Users\Stranded>set HADOOP_HOME
HADOOP_HOME=D:\Nosql\Hadoop\hadoop-2.7.7
C:\Users\Stranded>set STREAM = %HADOOP_HOME%\share\hadoop\tools\lib\hadoop-streaming-2.7.7.jar
(linux参考 Hadoop实践之Python(一) )
type student.txt + student_course.txt | python mapper.py | sort | python reducer.py
修改后,写一个bat脚本(注意,windows上用streaming和网上一般能查到的linux脚本是不一样的,不能使用-files传多个文件,必须-file一个一个上传,另外-mapper等也得是cmd或者jar的形式,可以通过hadoop jar %STREAM% -help 的方式查看)
参考 Hadoop-Streaming(Python篇)
::hdfs dfs -mkdir /user
::hdfs dfs -mkdir /user/input
::hdfs dfs -put ./*.txt /user/input
hadoop jar %STREAM% ^
-D stream.non.zero.exit.is.failure=false ^
-file mapper.py ^
-file reducer.py ^
-input /user/input ^
-output /user/output ^
-mapper "python mapper.py" ^
-reducer "python reducer.py"
注意最开始要在hdfs里创建目录、上传输入文件
(base) PS C:\Users\Stranded\PycharmProjects\Aliyun\hadoopTest> hdfs dfs -ls /user/input
Found 2 items
-rw-r--r-- 1 Stranded supergroup 253605 2019-12-30 17:54 /user/input/student.txt
-rw-r--r-- 1 Stranded supergroup 1013707 2019-12-30 17:54 /user/input/student_course.txt
报错
There are 0 datanode(s) running and no node(s) are excluded in this operation
解决:
将hdfs-site.xml配置文件中的 dfs.datanode.data.dir配置项对应的文件夹下的cureent文件夹删除
start-all重启,jps里有datanode了
报错
Exception message: CreateSymbolicLink error (1314): ???
解决:
修改了core-site.xml文件,要添加 fs.defaultFS 和 fs.default.name两个相同的属性
https://blog.csdn.net/qq_29477175/article/details/89683491
报错:
safemode
解决
等待他过几秒自动OFF或者
hdfs dfsadmin -safemode leave
还有其他一堆报错,我太南了
各种排除问题,最后发现可能是bin的问题,之前下的是2.7.1的windows编译版本,2.7.4前后不一样,所以重新下了个2.7.7的
https://github.com/cdarlint/winutils/tree/master/hadoop-2.7.7
还要注意!要把bin文件里的hadoop.dll复制到C:/Windows/System32里,之前原本的没覆盖就还是有问题。
job运行成功后,查看各个统计信息,我最开始输出是0,修改脚本,去掉combiner就有输出了。
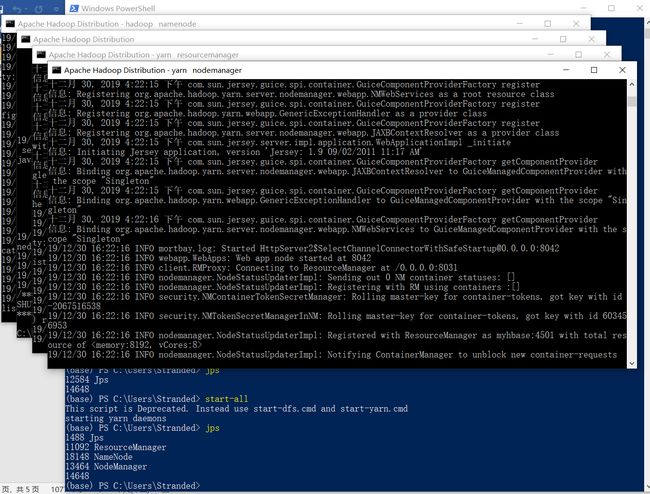
(base) PS C:\Users\Stranded\PycharmProjects\Aliyun\hadoopTest> .\run.bat
C:\Users\Stranded\PycharmProjects\Aliyun\hadoopTest>hadoop jar D:\Nosql\Hadoop\hadoop-2.7.7\share\hadoop\tools\lib\hadoop-streaming-2.7.7.jar -D stream.non.zero.exit.is.failure=false -file mapper.py -file reducer.py -input /user/input -output /user/output -mapper "python mapper.py" -reducer "python reducer.py"
19/12/31 12:51:05 WARN streaming.StreamJob: -file option is deprecated, please use generic option -files instead.
packageJobJar: [mapper.py, reducer.py, /C:/Users/Stranded/AppData/Local/Temp/hadoop-unjar4405973670165844345/] [] C:\Users\Stranded\AppData\Local\Temp\streamjob3497312476657191470.jar tmpDir=null
19/12/31 12:51:06 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
19/12/31 12:51:06 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
19/12/31 12:51:08 INFO mapred.FileInputFormat: Total input paths to process : 2
19/12/31 12:51:08 INFO mapreduce.JobSubmitter: number of splits:3
19/12/31 12:51:08 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1577764863539_0010
19/12/31 12:51:08 INFO impl.YarnClientImpl: Submitted application application_1577764863539_0010
19/12/31 12:51:08 INFO mapreduce.Job: The url to track the job: http://DESKTOP-3EELJOI:8088/proxy/application_1577764863539_0010/
19/12/31 12:51:08 INFO mapreduce.Job: Running job: job_1577764863539_0010
19/12/31 12:51:19 INFO mapreduce.Job: Job job_1577764863539_0010 running in uber mode : false
19/12/31 12:51:19 INFO mapreduce.Job: map 0% reduce 0%
19/12/31 12:51:33 INFO mapreduce.Job: map 100% reduce 0%
19/12/31 12:51:42 INFO mapreduce.Job: map 100% reduce 100%
19/12/31 12:51:42 INFO mapreduce.Job: Job job_1577764863539_0010 completed successfully
19/12/31 12:51:42 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=1303853
FILE: Number of bytes written=3115959
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1271710
HDFS: Number of bytes written=2585774
HDFS: Number of read operations=12
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=3
Launched reduce tasks=1
Data-local map tasks=3
Total time spent by all maps in occupied slots (ms)=36326
Total time spent by all reduces in occupied slots (ms)=6563
Total time spent by all map tasks (ms)=36326
Total time spent by all reduce tasks (ms)=6563
Total vcore-milliseconds taken by all map tasks=36326
Total vcore-milliseconds taken by all reduce tasks=6563
Total megabyte-milliseconds taken by all map tasks=37197824
Total megabyte-milliseconds taken by all reduce tasks=6720512
Map-Reduce Framework
Map input records=36535
Map output records=36535
Map output bytes=1230777
Map output materialized bytes=1303865
Input split bytes=302
Combine input records=0
Combine output records=0
Reduce input groups=3998
Reduce shuffle bytes=1303865
Reduce input records=36535
Reduce output records=32508
Spilled Records=73070
Shuffled Maps =3
Failed Shuffles=0
Merged Map outputs=3
GC time elapsed (ms)=498
CPU time spent (ms)=6307
Physical memory (bytes) snapshot=1049423872
Virtual memory (bytes) snapshot=1223659520
Total committed heap usage (bytes)=739246080
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1271408
File Output Format Counters
Bytes Written=2585774
19/12/31 12:51:42 INFO streaming.StreamJob: Output directory: /user/output
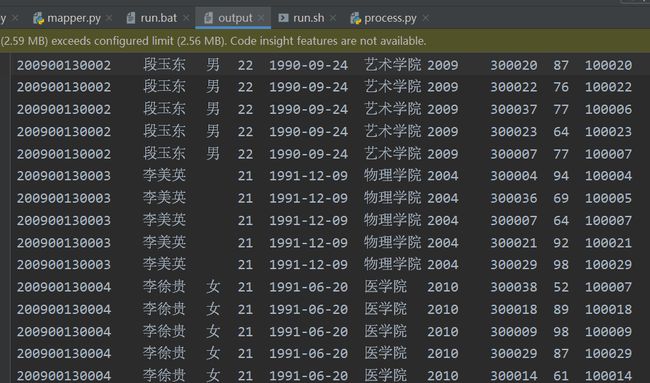
这样输出就在hdfs上了,-cat查看中文乱码,可以下到本地
hdfs dfs -get /user/output/part-00000 ./output
高级API方式(mrjob)
pip install pyhdfs -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip3 install mrjob -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
import os
import re
from mrjob.job import MRJob
from mrjob.protocol import RawProtocol, ReprProtocol
class Join(MRJob):
# mrjob allows you to specify input/intermediate/output serialization
# default output protocol is JSON; here we set it to text
OUTPUT_PROTOCOL = RawProtocol
# def mapper_init(self):
def mapper(self, key, line):
# note that the key is an object (a list in this case)
# that mrjob will serialize as JSON text
data = line.strip().split('\t')
yield (data[0], data[1:])
def combiner(self, key, values):
# the combiner must be separate from the reducer because the input
# and output must both be JSON
try:
input_file = os.environ['mapreduce_map_input_file']
except KeyError:
input_file = os.environ['map_input_file']
input_file = os.path.basename(input_file).split('.')[0]
self.tag = 'sc' if input_file == 'student_course' else 's'
yield (key, [self.tag] + list(values))
def reducer(self, key, values):
# the final output is encoded as text
scs = []
ss = []
for val in values:
if val[0] == 's':
ss += [val[1]]
else:
scs += [val[1]]
for s in ss:
for sc in scs:
yield (key, '\t'.join(s + sc))
if __name__ == '__main__':
# sets up a runner, based on command line options
Join.run()
combiner应该也可以不写

JAVA版
一样是写mapper、reducer,还有Runner,代码就比较复杂了
package joiner;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.omg.PortableInterceptor.SYSTEM_EXCEPTION;
public class JoinMapper extends Mapper<Text,Text,Text,Text>{
private static final String STUDENT_XLS = "student.xls";
private static final String STUDENT_COURSE_XLS = "student_course.xls";
private static final String STUDENT_FLAG = "student";
private static final String STUDENT_COURSE_FLAG = "student_course";
private FileSplit fileSplit;
private Text outKey = new Text();
private Text outValue = new Text();
@Override
protected void map(Text key, Text value, Context context)
throws IOException, InterruptedException {
fileSplit = (FileSplit) context.getInputSplit();
String filePath = fileSplit.getPath().toString();
if (filePath.contains(STUDENT_XLS))
outValue.set(STUDENT_FLAG + "\t" + value);
else if (filePath.contains(STUDENT_COURSE_XLS))
outValue.set(STUDENT_COURSE_FLAG + "\t" + value);
context.write(key, outValue);
}
}
package joiner;
import java.io.IOException;
import java.util.*;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class JoinReducer extends Reducer<Text, Text, Text, Text>{
private static final String STUDENT_FLAG = "student";
private static final String STUDENT_COURSE_FLAG = "student_course";
private String fileFlag = null;
private String stuName = null;
private List<String> stuClassNames;
private Text outKey = new Text();
private Text outValue = new Text();
private Map<String,List<String>> sMap = new HashMap<String, List<String>>();
private Map<String,List<String>> scMap = new IdentityHashMap<String, List<String>>();
private Map<String,List<String>> finalMap = new IdentityHashMap<String, List<String>>();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
stuClassNames = new ArrayList<String>();
sMap.clear();
scMap.clear();
finalMap.clear();
for (Text val : values) {
String[] fields = StringUtils.split(val.toString(),"\t");
fileFlag = fields[0];
if (fileFlag.equals(STUDENT_FLAG)) {
List<String> line = new ArrayList<String>();
for (int i = 1;i<fields.length;i++)
line.add(fields[i]);
sMap.put(key.toString(),line);
}
else if (fileFlag.equals(STUDENT_COURSE_FLAG)) {
List<String> line = new ArrayList<String>();
for (int i = 1;i<fields.length;i++)
line.add(fields[i]);
scMap.put(key.toString(),line);
}
}
for (String k :scMap.keySet()) {
if (sMap.containsKey(k)) {
List<String> strings = scMap.get(k);
strings.addAll(sMap.get(k));
finalMap.put(k,strings);
}
}
for (String k:finalMap.keySet()) {
List<String> strings = finalMap.get(k);
StringBuilder stringBuilder = new StringBuilder();
for (String string:strings)
stringBuilder.append("\t").append(string);
outKey.set(k);
outValue.set(stringBuilder.toString());
context.write(outKey, outValue);
}
}
}
package joiner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import tool.FileUtil;
import java.util.HashMap;
import java.util.Map;
import java.util.TreeMap;
public class JoinRunner extends Configured implements Tool{
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new JoinRunner(), new String[]{"input","output"});
System.exit(res);
}
public int run(String[] args) throws Exception {
FileUtil.deleteDir("output");
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Join");
job.setJarByClass(JoinRunner.class);
job.setMapperClass(JoinMapper.class);
job.setReducerClass(JoinReducer.class);
job.setInputFormatClass(ExcelInputFormat.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0:1;
}
}