用Python爬取淘宝2000款套套

作者 | 猪哥
出自 | 裸睡的猪(ID:IT--Pig)
警告:本教程仅用作学习交流,请勿用作商业盈利,违者后果自负!如本文有侵犯任何组织集团公司的隐私或利益,请告知联系猪哥删除!!!
一、淘宝登录复习
前面我们已经介绍过了如何使用requests库登录淘宝,收到了很多同学的反馈和提问,猪哥感到很欣慰,同时对那些没有及时回复的同学说声抱歉!
顺便再提一下这个登录功能,代码是完全没有问题。如果你登录出现申请st码失败的错误时候,可以更换_verify_password方法中的所有请求参数。

在淘宝登录2.0改进中我们增加了cookies序列化的功能,目的就是为了方便爬取淘宝数据,因为如果你同一个ip频繁登录淘宝的话可能就会触发淘宝的反扒机制!
关于淘宝登录的成功率,在猪哥实际的使用中基本都能成功,如果不成功就按上面的方法更换登录参数!
二、淘宝商品信息爬取
这篇文章主要是讲解如何爬取数据,数据的分析放在下一篇。之所以分开是因为爬取淘宝遇到的问题太多,而猪哥又打算详细再详细的为大家讲解如何爬取,所以考虑篇幅及同学吸收率方面就分两篇讲解吧!宗旨还会不变:让小白也能看得懂!
本次爬取是调用淘宝pc端搜索接口,对返回的数据进行提取、然后保存为excel文件!
看似一个简单的功能却包含了很多问题,我们来一点一点往下看吧!
三、爬取单页数据
开始写一个爬虫项目我们都需要量化后再分步,而一般第一步便是先爬取一页试试!
1.查找加载数据URL
我们在网页中打开淘宝网,然后登录,打开chrome的调试窗口,点击network,然后勾选上Preserve log,在搜索框中输入你想要搜索的商品名称
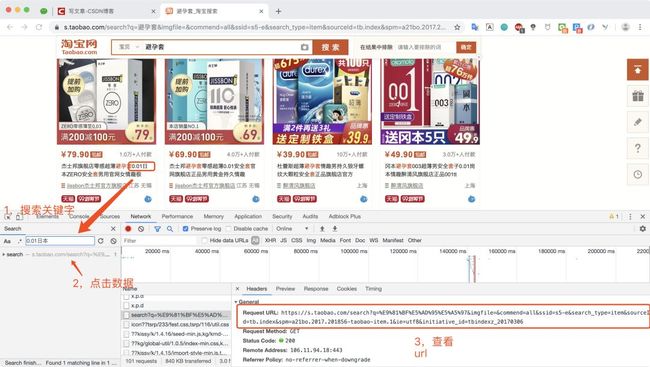
这是第一页的请求,我们查看了数据发现:返回的商品信息数据插入到了网页里面,而不是直接返回的纯json数据!
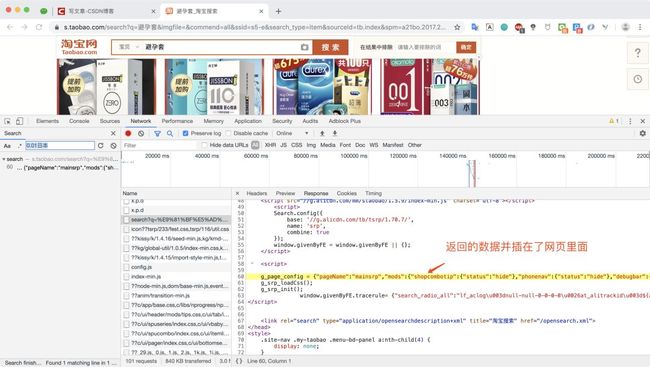
2. 是否有返回纯json数据接口?
然后猪哥就好奇有没有返回纯json的数据接口呢?于是我就点了下一页(也就是第二页)

请求第二页后猪哥发现返回的数据竟然是纯json,然后比较两次请求url,找到只返回json数据的参数!
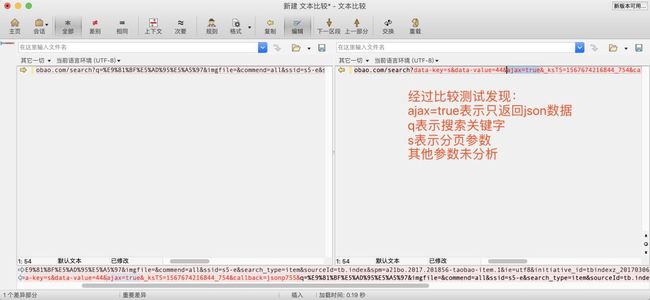
通过比较我们发现搜索请求url中如果带ajax=true参数的话就直接返回json数据,那我们是不是可以直接模拟直接请求json数据!
所以猪哥就直接使用第二页的请求参数去请求数据(也就是直接请求json数据),但是请求第一页就出现错误:

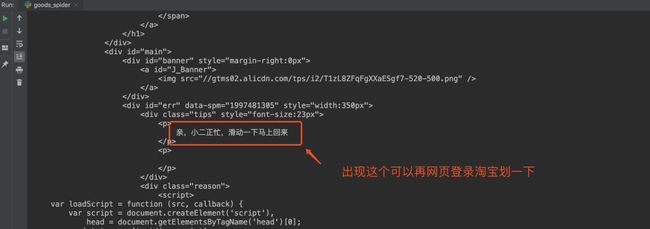
直接返回一个链接而 不是json数据,这个链接是什么鬼?点一下。。。

铛铛铛,滑块出现,有同学会问:用requests能搞定淘宝滑块吗?猪哥咨询过几个爬虫大佬,滑块的原理是收集响应时间,拖拽速度,时间,位置,轨迹,重试次数等然后判断是否是人工滑动。而且还经常变算法,所以猪哥选择放弃这条路!
3.使用请求网页接口
所以我们只能选择类似第一页(请求url中不带ajax=true参数,返回整个网页形式)的请求接口,然后再把数据提取出来!

这样我们就可以爬取到淘宝的网页信息了
四、提取商品属性
爬到网页之后,我们要做的就是提取数据,这里先从网页提取json数据,然后解析json获取想要的属性。
1.提取网页中商品json数据
既然我们选择了请求整个网页,我们就需要了解数据内嵌在网页的哪个位置,该怎么提取出来。
经过猪哥搜索比较发现,返回网页中的js参数:g_page_config就是我们要的商品信息,而且也是json数据格式!
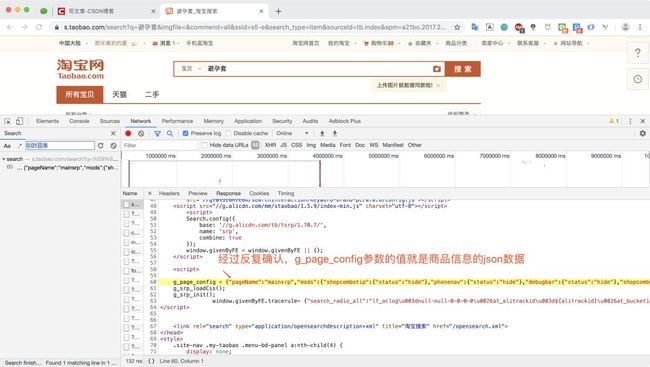
然后我们写一个正则就可以将数据提取出来了!
goods_match = re.search(r'g_page_config = (.*?)}};', response.text)
2.获取商品价格等属性
要想提取json数据,就要了解返回json数据的结构,我们可以将数据复制到一些json插件或在线解析
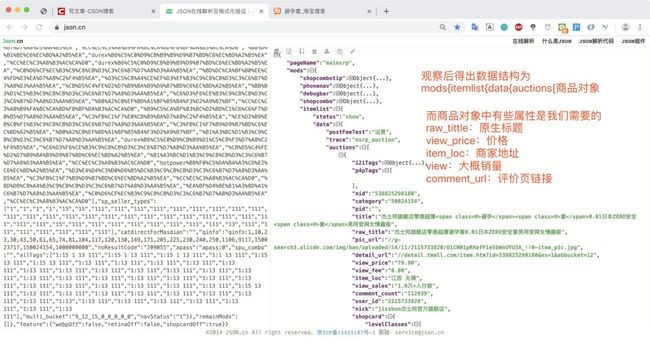
了解json数据结构之后,我们就可以写一个方法去提取我们想要的属性了

五、保存为excel
操作excel有很多库,网上有人专门针对excel操作库做了对比与测评感兴趣可以看看:https://dwz.cn/M6D8AQnq
猪哥选择使用pandas库来操作excel,原因是pandas比较操作方便且是比较常用数据分析库!
1.安装库
pandas库操作excel其实是依赖其他的一些库,所以我们需要安装多个库
pip install xlrd
pip install openpyxl
pip install numpy
pip install pandas
2.保存excel

这里有点坑的是pandas操作excel没有追加模式,只能先读取数据后使用append追加再写入excel!
查看效果

六、批量爬取
一次爬取的整个流程(爬取、数据提取、保存)完成之后,我们就可以批量循环调用了。

这里设置的超时秒数是猪哥实践出来的,从3s、5s到10s以上,太频繁容易出现验证码!
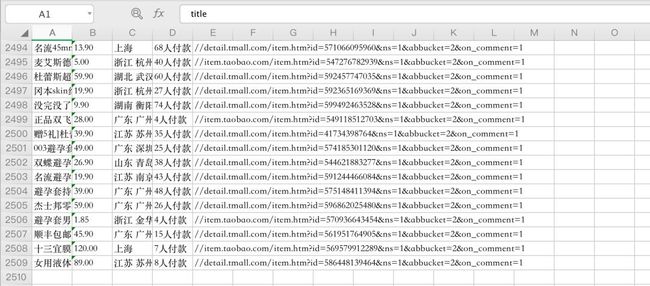
猪哥分多次爬取了两千多条数据
七、爬取淘宝遇到的问题
爬取淘宝遇到了非常多的问题,这里为大家一一列举:
1.登录问题
问题:申请st码失败怎么办?
回答:更换_verify_password方法中的所有请求参数。
参数没问题的话登录基本都会成功!
2.代理池
为了防止自己的ip被封,猪哥使用了代理池。爬取淘宝需要高质量的ip才能爬取,猪哥试了很多网上免费的ip,基本都不能爬取。
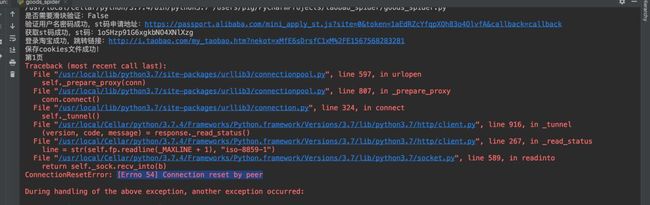
但是有一个网站的ip很好 站大爷:http://ip.zdaye.com/dayProxy.html ,这个网站每小时都会更新一批ip,猪哥试过还是有很多ip是可以爬取淘宝的。
3.重试机制
为了防止正常请求失败,猪哥在爬取的方法上加上了重试机制!
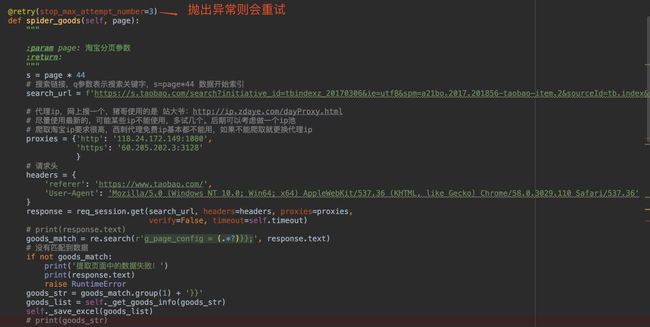
需要安装retry库
pip install retry
4.出现滑块
上面那些都没问题,但是还是会出现滑块,猪哥测试过很多次,有些爬取20次-40次左右最容易出现滑块。
出现滑块只能等个半小时后继续爬,因为目前还不能使用requests库解决滑块,后面学习selenium等其他框架看看是否能解决!
5.目前这只爬虫
目前这只爬虫并不完善,只能算是半成品,有很多可以改进的地方,比如自动维护ip池功能,多线程分段爬取功能,解决滑块问题等等,后面我们一起来慢慢完善这只爬虫,使他可以成为一只完善懂事的爬虫!
(*本文为Python大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
由易观携手CSDN联合主办的第三届易观算法大赛正在火热进行中!冠军奖3万元,每人最多邀请5位用户组队参赛。本次比赛主要预测访问平台的相关事件的PV,UV流量(包括Web端,移动端等),大赛将会提供相应事件的流量数据,以及对应时间段内的所有事件明细表和用户属性表等数据,进行模型训练,并用训练好的模型预测规定日期范围内的事件流量。
推荐阅读
Python内存分配时的小秘密
吐血整理!140种Python标准库、第三方库和外部工具都有了
如何用爬虫技术帮助孩子秒到心仪的幼儿园(基础篇)
Python传奇:30年崛起之路
干货 | Python后台开发的高并发场景优化解决方案
2019年最新华为、BAT、美团、头条、滴滴面试题目及答案汇总
阿里巴巴杨群:高并发场景下Python的性能挑战

你点的每个“在看”,我都认真当成了喜欢