python实现网络爬虫之scrapy框架
今天老师给我们讲了一下使用vscode环境下python实现爬取豆瓣电影网的信息,老师用的python是3.6.5,而我用的是3.6.4,但是结果没有什么不同。
准备工作:(1)先安装好python,我的电脑是安装的python3.6.4,安装python时第一步记得勾选添加路径 Add python3.6 to PATH....,如果安装成功后就可以在cmd运行 python -v就可以查看到是否安装成功。
(2)接下来在进行 Python在Windows系统中的开发环境搭建,使用 pip list命令可以查看当前模块库中已经安装的所有外部模块指令。
(3)Python3.6.5在安装时默认选中的Pip模块管理组件。 setuptools 和 wheel 两个组件都是Python安装第三方模块库的依赖工具组件。 目前 Python3.6.5默认安装的pip 和 setuptools均为最新版本,但wheel模块需手动安装。 建议安装Python的外部管理模块 wheel: 安装 wheel 指令:pip install -U wheel 。安装好之后:

(4)指定国内的镜像源 : 在用户目录下的你的用户名下新建一个pip文件夹,再往pip文件夹里面添加一个pip.ini的文件( Windows10: C:\用户\<用户名>\pip\pip.ini (pip文件夹及pip.ini 需要手动创建) )往pip.ini文家中添加如下两行代码
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple

(5)virtualenv虚拟环境安装(多版本Python共存)
我们可以在系统中安装多个版本的Python,为了方便Python版本之间的相互切换,我们可以使用virtualenv(虚拟环境)实现同一系统中多版本共存使用的问题。
Step1:使用 pip install –U virtualenv 下载安装虚拟模块包

Step2:创建虚拟环境文件夹
今后所有的python虚拟环境都放在这个文件夹下,新建一个venvs的文件夹
使用virtualenv命令,创建跟当前系统环境相同版本的虚拟环境:

此时可以看到新生成了一个文件夹,该文件夹就是虚拟环境:
Step3:进入当前虚拟环境 cd 虚拟文件夹名称,启动虚拟环境 虚拟环境文件夹/Script/activate
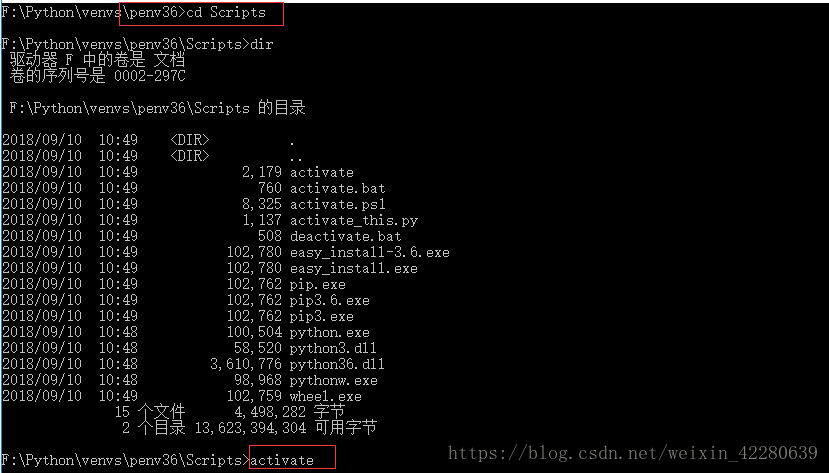
执行:pip install -U pypiwin32 安装
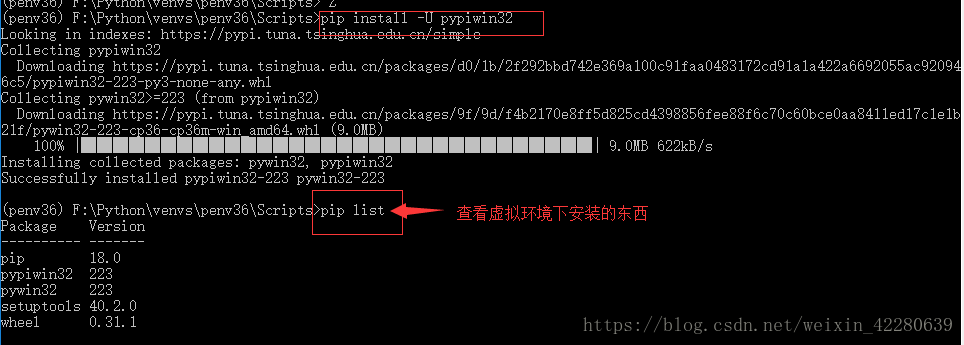
(6)Vscode安装配置,可以自行在网站下载VScode安装包进行安装
![]()
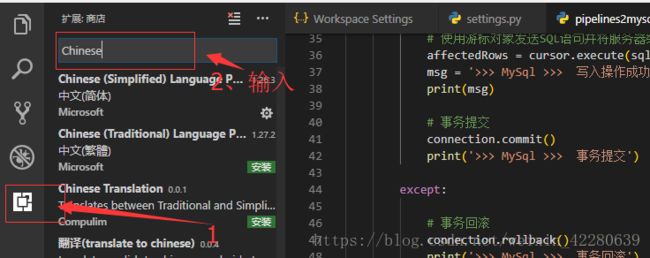
Step1:安装python开发插件,常用的如下所示:python、 Python-autopep8 、 GBKToUTF8 ;如果你的Vscode是英文的,下载中文安装包,安装第一个,安装成功后要点击重新加载才能成功,依次安装上述三个插件
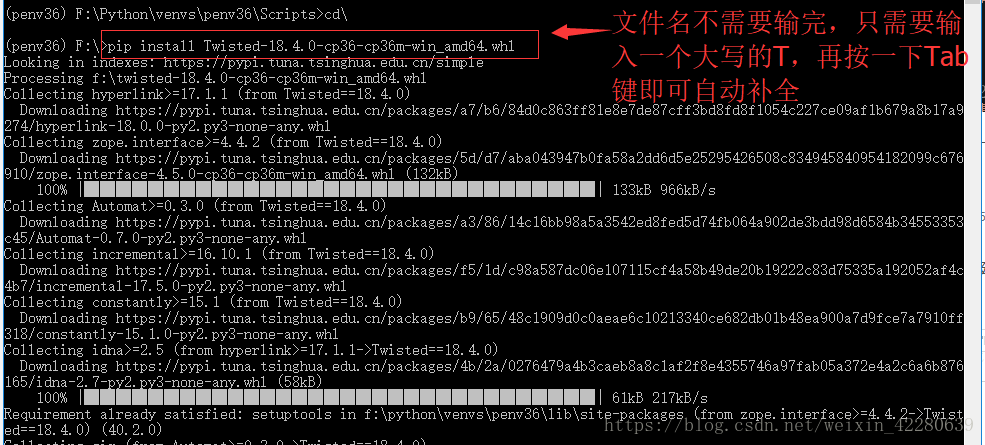
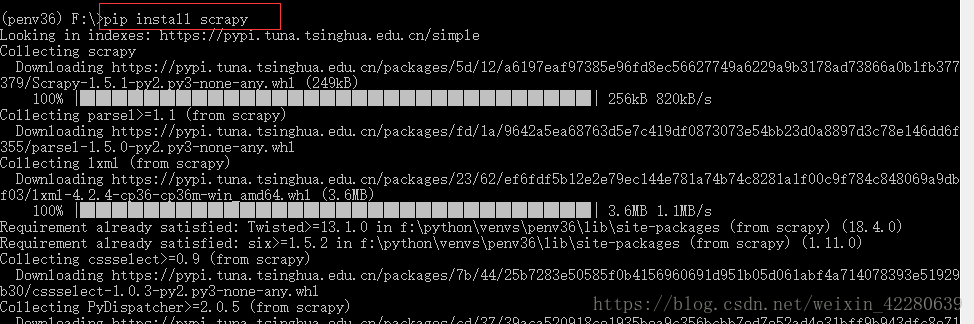
Step2:将下面这个文件夹复制到我所使用的盘的根目录,我放在了F盘的根目录,进入F盘根目录下,进行离线安装,记得联网,再安装Scrapy
![]()
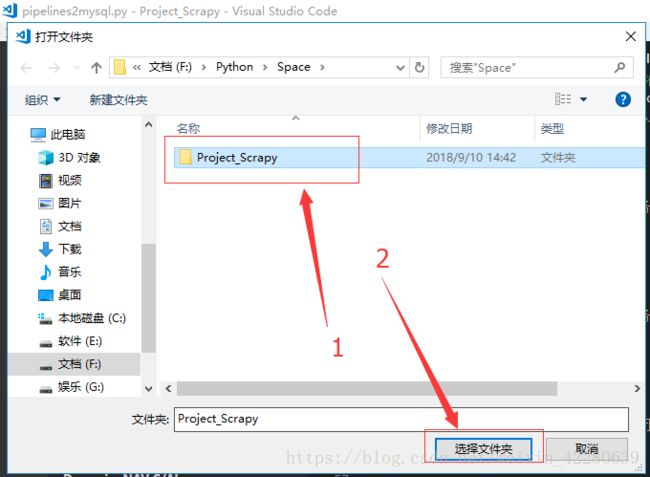
Step3:在本地创建一个workspace的文件夹,由于我已经有了一个workspace文件夹,所以我创建了一个Space的文件夹,再往space文件夹里面创建一个Project_Scrapy文件夹。接下来复制此路径。cmd里面进入此路径下,再创建工程
![]()
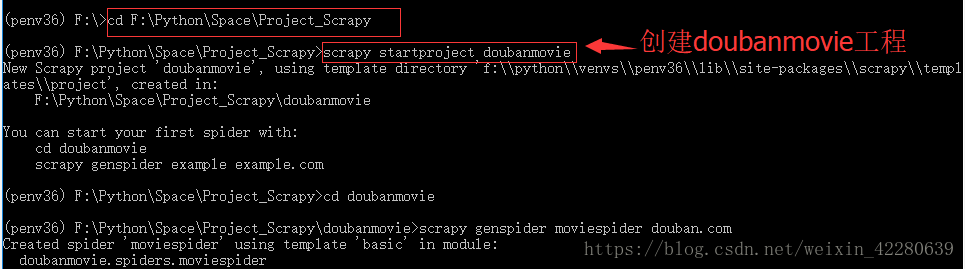
(7) 测试连接
Step1:在Vscode中导入刚刚新建的文件夹
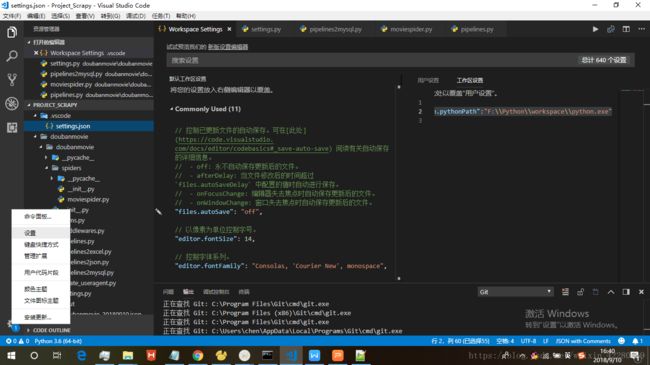
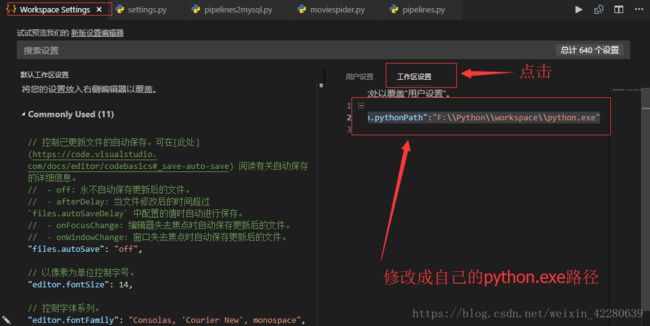
Step2:VScode打开设置,设置python.exe的路径,操作如下
Step3:接下来创建核心爬虫脚本程序:①使用命令:scrapy genspider 爬虫脚本名称 访问网站的域名

Step4:我们是通过程序从网站上爬取数据,但是并不是所有的网站都允许程序的访问,所以要测试一下程序与网站的连接情况。测试的方法,仅需一条指令:scrapy shell 网站Url地址。
测试常见的结果:200 正常 403 拒绝访问(浏览器访问没问题,拒绝程序的访问)
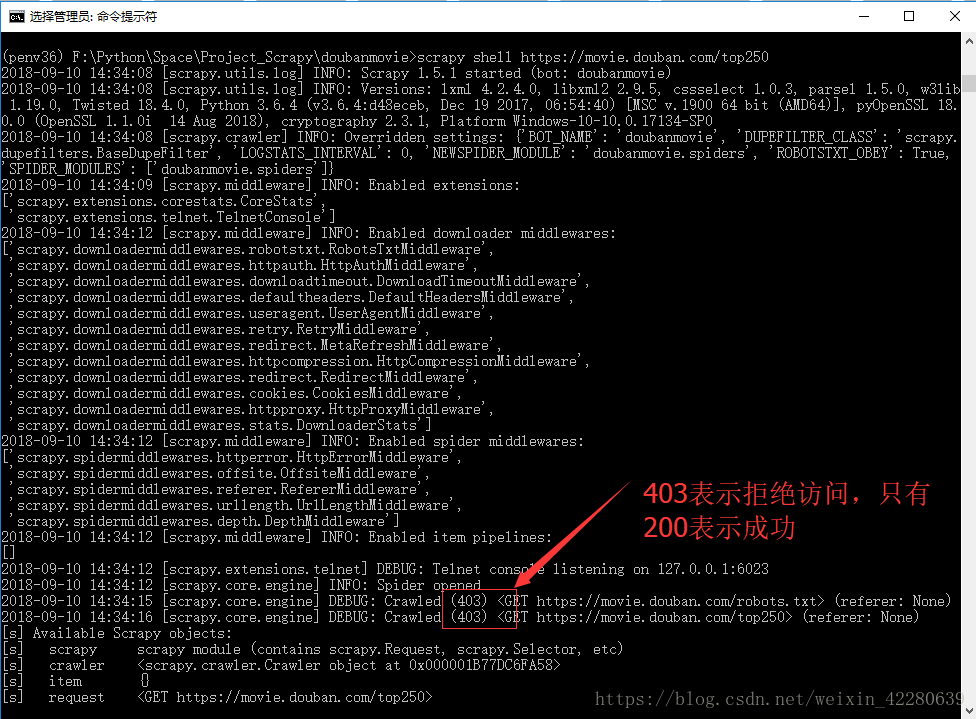
在项目下添加一个rotate_useragent.py文件,文件内容如下
# -*- coding: utf-8 -*-
'''
rotate_useragent.py
--------------------------------
用户代理轮循检索器
@Copyright: Chinasoft Interntional·ETC
@Author: Alvin
@Date: 2018-01-16
'''
# 导入random模块
import random
# 导入useragent用户代理模块中的UserAgentMiddleware类
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
# RotateUserAgentMiddleware类,继承 UserAgentMiddleware 父类
# 作用:创建动态代理列表,随机选取列表中的用户代理头部信息,伪装请求。
# 绑定爬虫程序的每一次请求,一并发送到访问网址。
# 发爬虫技术:由于很多网站设置反爬虫技术,禁止爬虫程序直接访问网页,
# 因此需要创建动态代理,将爬虫程序模拟伪装成浏览器进行网页访问。
class RotateUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, user_agent=''):
self.user_agent = user_agent
def process_request(self, request, spider):
#这句话用于随机轮换user-agent
ua = random.choice(self.user_agent_list)
if ua:
# 输出自动轮换的user-agent
print(ua)
request.headers.setdefault('User-Agent', ua)
# the default user_agent_list composes chrome,I E,firefox,Mozilla,opera,netscape
# for more user agent strings,you can find it in http://www.useragentstring.com/pages/useragentstring.php
# 编写头部请求代理列表
user_agent_list = [\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"\
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",\
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",\
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",\
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",\
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",\
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]可以发现项目中也自动显示了这一文件
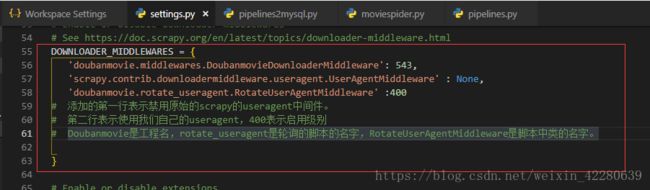
现在轮询文件已经考进去了,但是scrapy框架还不知道,所以要让scrapy框架知道,方法是配置settings.py文件。打开settings.py,找到
#DOWNLOADER_MIDDLEWARES = {
# 'doubanmovie.middlewares.DoubanmovieDownloaderMiddleware': 543,
#}将注释去掉并添加以下代码
DOWNLOADER_MIDDLEWARES = {
'doubanmovie.middlewares.DoubanmovieDownloaderMiddleware': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware' : None,
'doubanmovie.rotate_useragent.RotateUserAgentMiddleware' :400
}
之后保存即可生效 ,回到cmd命令下,再一次运行刚才的语句,即可成功
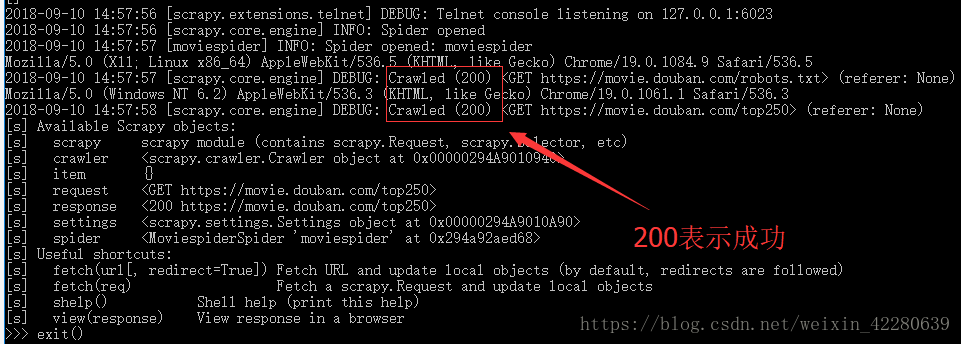
(8)正式爬取网站数据
Step1:明确爬取哪部分信息,此处我们主要爬取豆瓣的电影的排行榜的排名以及标题title,查看页面的源代码,分析要爬取数据的页面结构,可以发现每一个小块均存在 li 标签 下
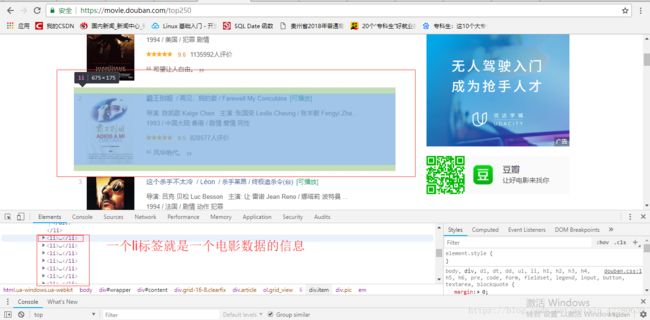
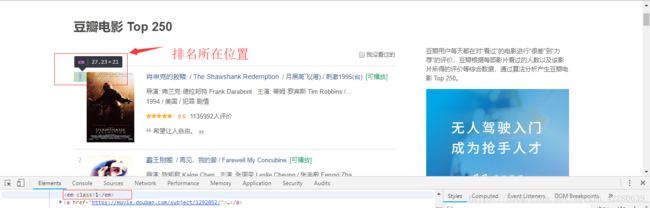

Step2:打开工程中的item.py文件,设置要采集的数据项:Scrapy框架中的 items.py 文件以采集对象的方式存在,将每一个采集项作为一个采集对象的属性处理。而且,每一个属性统一使用 scrapy.Field( ) 函数创建,非常方便
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 排名
rank = scrapy.Field()
#名称
title = scrapy.Field()
pass
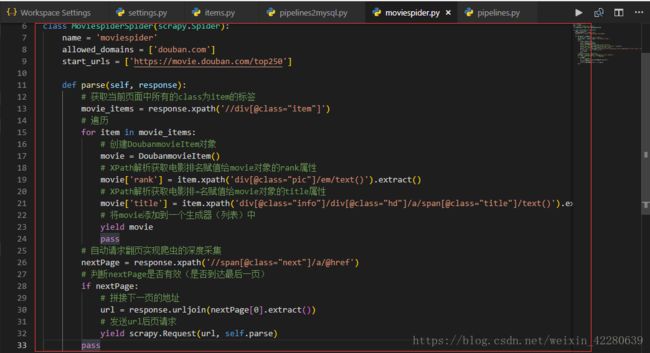
Step3:重点+难点:编写 moviespider.py 解析HTML标签获取数据
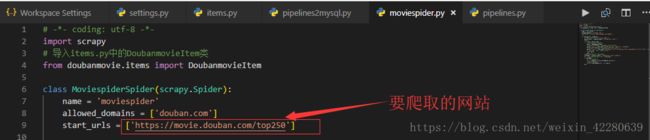
增加代码
# -*- coding: utf-8 -*-
import scrapy
# 导入items.py中的DoubanmovieItem类
from doubanmovie.items import DoubanmovieItem
class MoviespiderSpider(scrapy.Spider):
name = 'moviespider'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
# 获取当前页面中所有的class为item的标签
movie_items = response.xpath('//div[@class="item"]')
# 遍历
for item in movie_items:
# 创建DoubanmovieItem对象
movie = DoubanmovieItem()
# XPath解析获取电影排名赋值给movie对象的rank属性
movie['rank'] = item.xpath('div[@class="pic"]/em/text()').extract()
# XPath解析获取电影排=名赋值给movie对象的title属性
movie['title'] = item.xpath('div[@class="info"]/div[@class="hd"]/a/span[@class="title"]/text()').extract()
# 将movie添加到一个生成器(列表)中
yield movie
pass
# 自动请求翻页实现爬虫的深度采集
nextPage = response.xpath('//span[@class="next"]/a/@href')
# 判断nextPage是否有效(是否到达最后一页)
if nextPage:
# 拼接下一页的地址
url = response.urljoin(nextPage[0].extract())
# 发送url后页请求
yield scrapy.Request(url, self.parse)
passStep4:编写 piplines.py 设置控制台输出,打开piplines.py文件,添加如下代码:
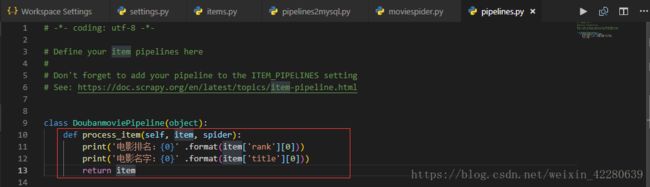
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
print('电影排名:{0}' .format(item['rank'][0]))
print('电影名字:{0}' .format(item['title'][0]))
return item要想启用该 输出模式,需要在 settings.py 文件中设置 输出项即可

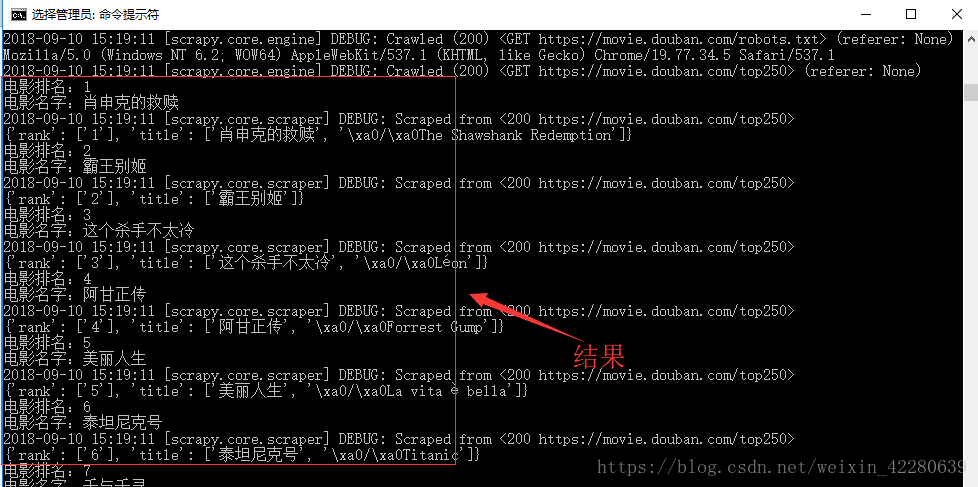
然后在cmd里面运行
![]()

(6)对数据进行存储
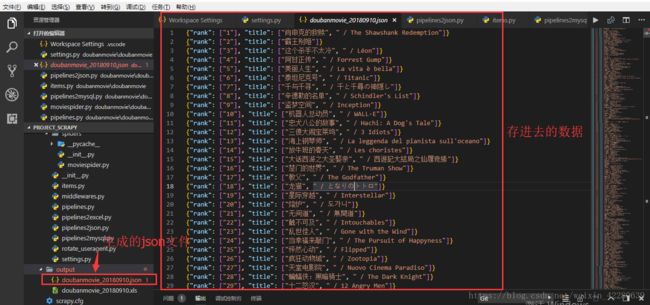
Step1:采用json存储
通过前面的讲解我们知道,控制输出的文件是piplines.py ,那么我们创建一个新的piplines2json.py 文件,来控制文件输出到json。 ①在同级目录下复制piplines.py文件,重命名为piplines2json.py。②打开文件,将输出到控制台的代码删除掉,留下基本模板。 ③接下来在构造方法中,判断是否有将要保存文件的文件夹,如果没有,则创建。这里要创建文件夹需要导入os模块 ④这里为什么要把创建文件夹的代码写在构造方法而不是process_item方法中呢,因为如果写在process_item方法中,那么每输出一条数据就会创建一个文件夹,这显然不是我们想要的结果。在process_item方法中添加写入json文件的代码:
import os
import time
import json
class DoubanmoviePipeline(object):
# 创建一个构造方法,用于创建所有类型输出文件的文件夹
def __init__(self):
# 设置输出文件夹的名称
self.folderName = 'output'
# 判断文件夹是否存在
if not os.path.exists(self.folderName):
# 创建文件夹
os.mkdir(self.folderName)
def process_item(self, item, spider):
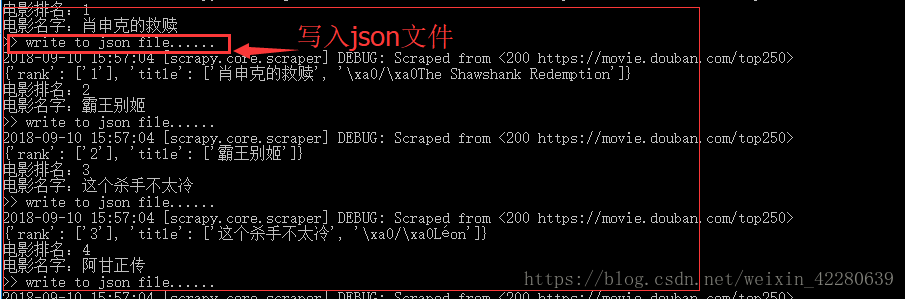
# 输出提示
print('>> write to json file......')
# 获取当前日期的字符串类型数据
now = time.strftime('%Y%m%d', time.localtime())
# 设置json文件名称
jsonFileName = 'doubanmovie_' + now + '.json'
try:
# 打开json文件,以追加的方式
with open(self.folderName + os.sep + jsonFileName, 'a', encoding="utf-8") as jsonfile:
# 当前数据序列化为json格式
data = json.dumps(dict(item), ensure_ascii=False) + '\n'
# 写入到json文件
jsonfile.write(data)
except IOError as err:
# 输出错误信息
raise('json file error: {0}' .format(str(err)))
finally:
#关闭文件流
jsonfile.close()
return itemSettings.py中也需要添加代码:

同样cmd下运行
![]()
Step2:采用Excel存储
首先安装Excel所需的三个插件

新增pipelines2excel.py文件: 代码如下
import time
import xlwt
import xlrd
from xlutils.copy import copy
class DoubanmoviePipeline(object):
# 构造方法:创建一个excel文件以及内容模板
def __init__(self):
folder_name = 'output'
current_date = time.strftime('%Y%m%d', time.localtime())
file_name = 'doubanmovie_' + current_date + '.xls'
# 最终的文件路径
self.excelPath = folder_name + '/' + file_name
# 构建workbook工作簿
self.workbook = xlwt.Workbook(encoding='UTF-8')
# 创建sheet工作页
self.sheet = self.workbook.add_sheet(u'豆瓣电影数据')
# 设置excel内容的标题
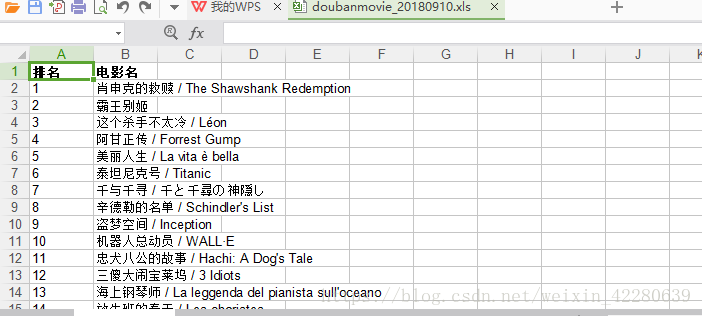
headers = ['排名', '电影名']
# 设置标题文字的样式
headStyle = xlwt.easyxf('font: color-index black, bold on')
# for循环写入标题内容
for colIndex in range(0, len(headers)):
# 按照规定好的字体样式将标题内容写入
self.sheet.write(0, colIndex, headers[colIndex], headStyle)
pass
# 保存创建好的excel文件
self.workbook.save(self.excelPath)
# 全局变量行数
self.rowIndex = 1
pass
def process_item(self, item, spider):
# 提示信息
print('>>>>>> write to Excel .................')
# 读取已经创建好的excel文件
oldWb = xlrd.open_workbook(self.excelPath, formatting_info=True)
# 拷贝一个副本
newWb = copy(oldWb)
# 获取到excel要操作的sheet工作页
sheet = newWb.get_sheet(0)
# 将采集到的数据转换成一个List列表
line = [item['rank'], item['title']]
# 使用for循环遍历excel中的每一个cell格(行,列)
for colIndex in range(0, len(item)):
#将数据写入到指定的行列中去
sheet.write(self.rowIndex, colIndex, line[colIndex])
pass
# 完毕后保存excel文件,自动覆盖原有的文件
newWb.save(self.excelPath)
# 全局行变量+1
self.rowIndex = self.rowIndex + 1
return itemSettings.py文件中配置:
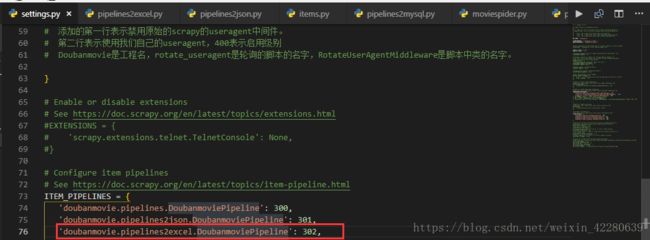
再次运行

输出已有xls文件


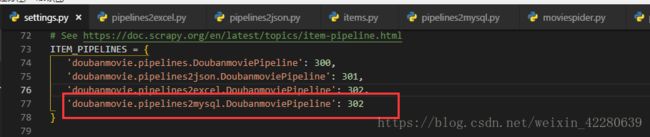
Step3:上传mysql数据库
新建crawl数据库,新建movieinfo表,添加以下属性

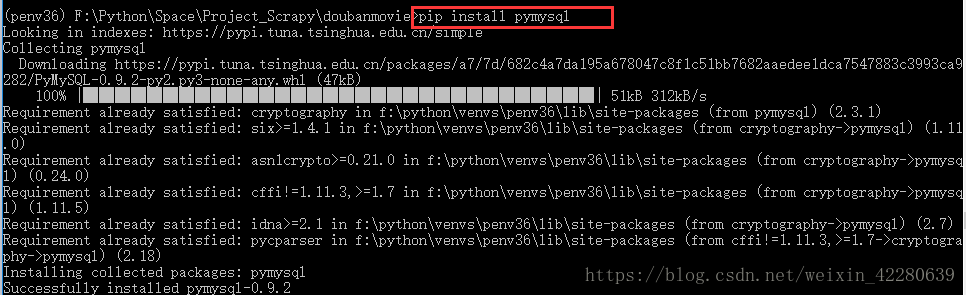
安装pymysql使得python可以连接数据库
新建pipelines2mysql.py文件: 文件代码
# 导入mysql模块
import pymysql
class DoubanmoviePipeline(object):
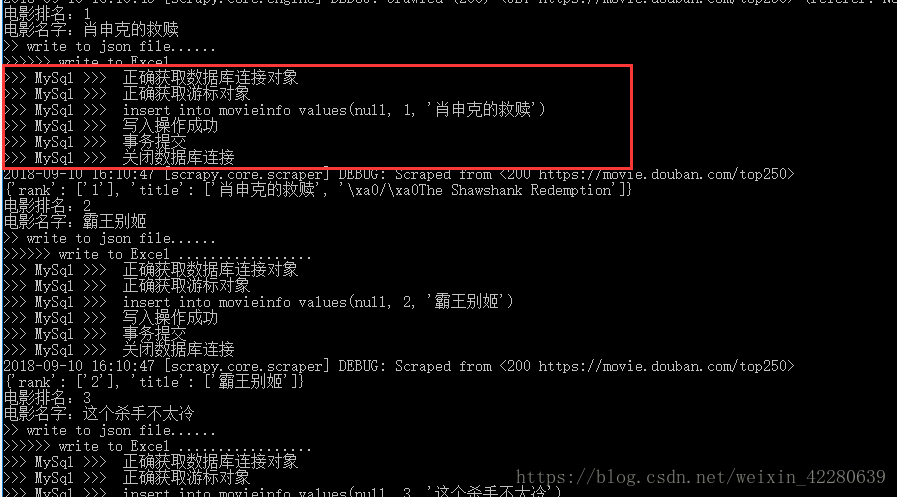
def process_item(self, item, spider):
# 设置一个全局的连接对象
connection = ''
try:
# 获取一个有效的数据库连接对象
connection = pymysql.connect(host='localhost', port=3306,\
user='root', password='970301cx',\
db='crawl', charset='utf8')
if connection:
print('>>> MySql >>> 正确获取数据库连接对象')
# 创建一个游标对象
cursor = connection.cursor()
print('>>> MySql >>> 正确获取游标对象')
# 设置插入数据的SQL语句模板
rank = int(item['rank'][0])#将排名强制转换为整形
title = item['title'][0]
sql = 'insert into movieinfo values(null, %d, \'%s\')' %(rank, title)
print('>>> MySql >>> %s' %sql)
# 使用游标对象发送SQL语句并将服务器结果返回
affectedRows = cursor.execute(sql)
msg = '>>> MySql >>> 写入操作成功' if affectedRows > 0 else '>>> MySql >>> 写入操作失败'
print(msg)
# 事务提交
connection.commit()
print('>>> MySql >>> 事务提交')
except:
# 事务回滚
connection.rollback()
print('>>> MySql >>> 事务回滚')
finally:
# 关闭数据库连接
connection.close()
print('>>> MySql >>> 关闭数据库连接')
return item修改setting.py
运行结果
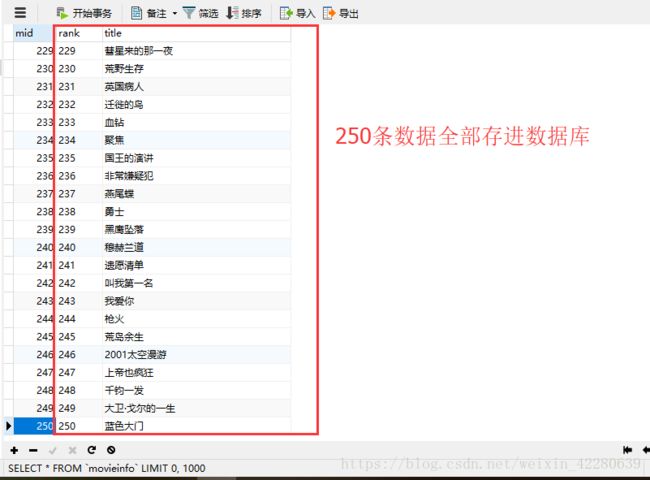
查看一下 mysql数据库中的内容
至此,今天的学习内容已经结束了