hadoop伪分布式 用java编写的jar包拉到Linux上运行
一、在eclipse上编写代码(以统计数据里面的字母出现次数为例)
(1)、打开eclipse,进行创建项目,随便起项目名与包名与新建类:
然后最重要的是导入与你的Linux上面一样版本的hadoop的jar包,例如我这里在Linux上面安装的2.6.5版本,所以我下载一份安装包到本地电脑解压,然后导入:(下面是需要导入的目录)
hadoop-2.6.5\share\hadoop\common
hadoop-2.6.5\share\hadoop\common/lib(这个目录里面全部是,直接ctrl+A就好了)
hadoop-2.6.5\share\hadoop\mapreduce
hadoop-2.6.5\share\hadoop\mapreduce\lib
(2)、代码与解释:
package wordCount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
/**
* 两个抽象类:wordCountMap wordCountReducer
*/
/**
* 第一个静态类 wordCountMap,该类继承Hadoop jar包的Mapper
*
*
*/
private static class wordCountMapper extends
Mapper {
@Override
protected void map(
Object key,
Text value,
org.apache.hadoop.mapreduce.Mapper.Context context)
throws java.io.IOException, InterruptedException {
// TODO 添加map处理逻辑代码
/**
* I like guilin guilin is good place a good palace in guilin
* 将上述文本转化为以下格式:
*
* .....
* 1、将每行数据转化为string 2、对每行数据按照空格拆分成string [] 3、生成对,其中V固定值为1
*/
//1、将每行数据转化为string
String lineConten=value.toString();
// 2、对每行数据按照空格拆分成string []
String [] conttentSpilt=lineConten.split(" ");
//3、生成对,其中V固定值为1
for(int i=0; i {
protected void reduce(
Text key,
java.lang.Iterable values,
org.apache.hadoop.mapreduce.Reducer.Context context)
throws java.io.IOException, InterruptedException {
int sum=0; //保存每个单词出现的频率
for(IntWritable value:values){
sum+=value.get();
}
context.write(key, new IntWritable(sum));
};
// 添加reducer的逻辑代码
/**
* 整理map数据,代码逻辑负责生成如下结果
*
*
*/
/**
* 1、遍历map的结果数,for
* 2、对map 的value值进行累加操作
*/
}
/**
* @param args
* @throws IOException
* @throws ClassNotFoundException
* @throws InterruptedException
*/
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//配置hadoop任务
// /input/demo.txt /out
Configuration conf=new Configuration();
String [] argArray=new GenericOptionsParser(conf,args).getRemainingArgs();
Job job = Job.getInstance(conf,"wumeiling"); //任务名字
job.setJarByClass(WordCount.class);
job.setMapperClass(wordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(wordCountReducer.class);
//最终结果的输出格式
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// hdfs 获取输入路径,结果输出路径
FileInputFormat.addInputPath(job, new Path(argArray[0]));
FileOutputFormat.setOutputPath(job, new Path(argArray[1]));
//退出hadoop
System.exit(job.waitForCompletion(true)?0:1);
}
}
二、打成jar与创建目录
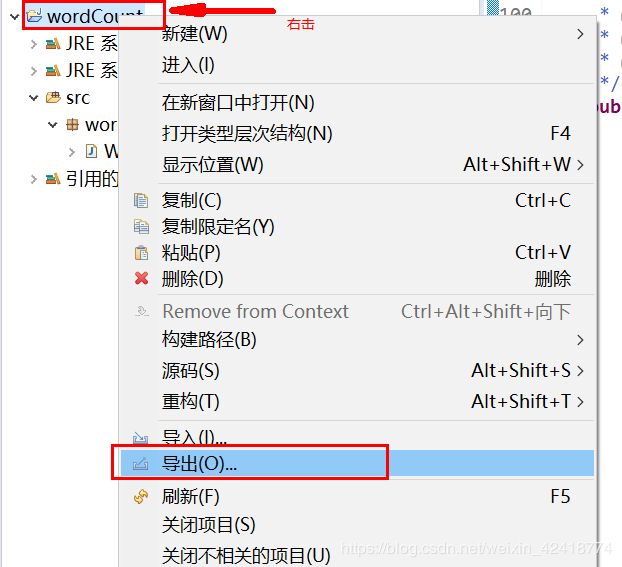


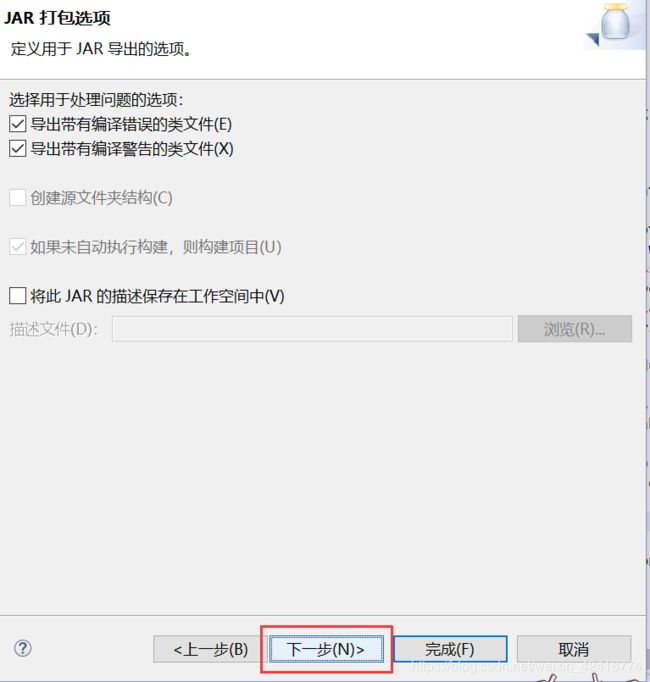
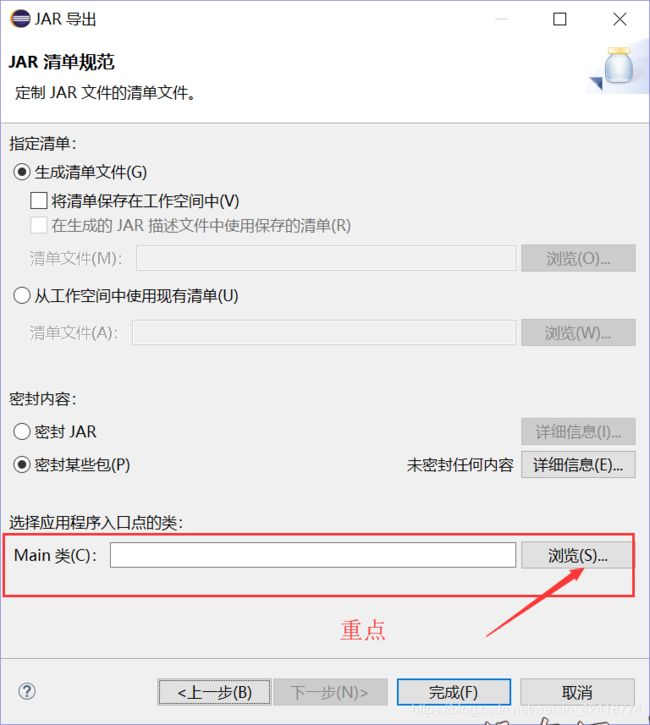
一定要选择main类,否则无法运行

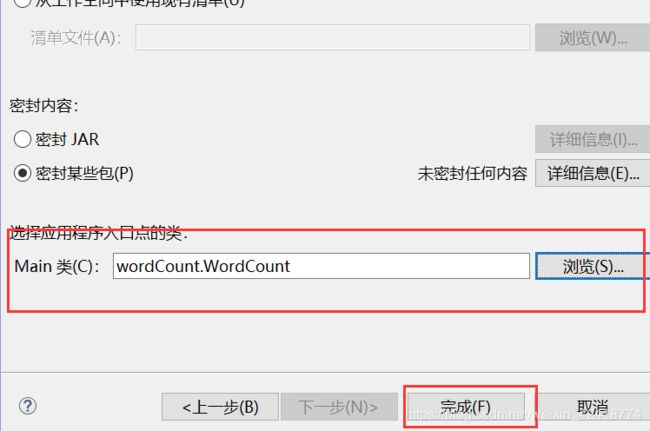
好了,这里就生成一个demo.jar了,然后就把它拉取到Linux上面的一个文件夹里面,但是你要知道路径在哪里:

接下就是在hadoop里面新建一个input文件来装data.txt数据了(data.txt自己新建,里面数据随便自己输入一些数据就可以了)
创建input文件夹: bin/hadoop fs -mkdir /input(因为我没有设置全局变量,所以运行都需要在前面加入bin/或者进入到bin目录下面执行)
查询语句:bin/hadoop fs -ls /
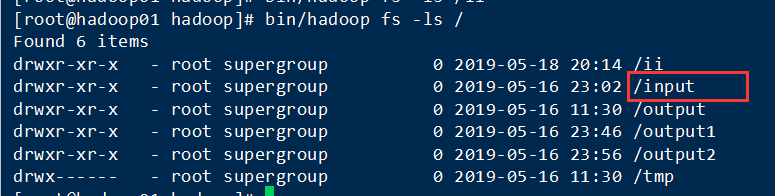
随便在哪一个目录下面新建data.txt然后用命令拉取到input下面:(data.txt里面的数据,随便输入的)
拉取命令:
bin/hadoop fs -put /root/hadoop/hadoop/data1.txt /input
/root/hadoop/hadoop/data1.txt //建文件的目录
/input //你要拉取到哪里的目录,这里拉取到input下 可以查看一下有没有: 这里我已经有data.txt了,所以用data1.txt做演示

可以查看一下里面的数据:

这里的output不用自己建,运行成功后会自动生成结果在里面存储
三、运行以及查看输出
执行语句:
bin/hadoop jar /root/hadoop/hadoop/demo.jar /input/data.txt /output
/root/hadoop/hadoop/demo.jar //jar根目录
/input/data.txt //在hadoop里面创建的数据根目录
/output //输出文件名字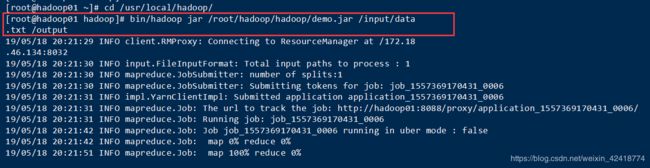
运行成功最后输出:
查看输出结果:
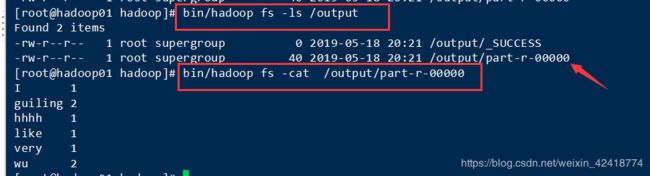
查看数据结果与你输入的data.txt内容判断一样就成功了:原数据下图

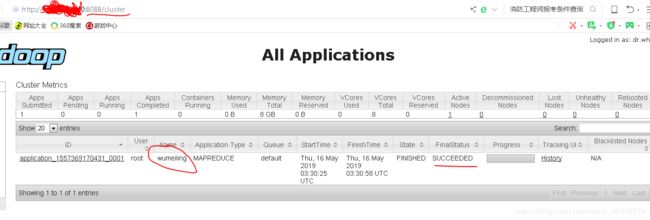
最后去查看自己的小象有没有进程出现:(不懂查看请看上次写的有关 hadoop 伪分布的博客)
四、运行出错以及解决办法
执行运行语句的时候报错了:下图是错误展示
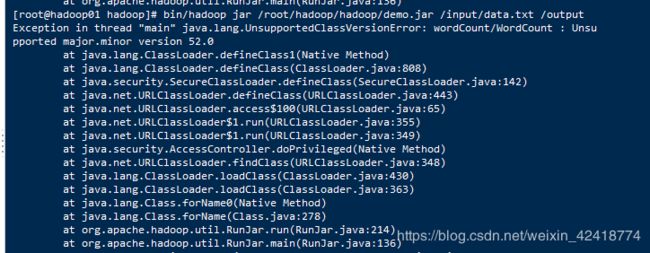
解释一下错误,大概就是说jdk的版本不一样:
就是说你编写的eclipse的jdk的版本要和Linux上面的jdk版本一样,不然运行就会出错,不兼容
所以就需要在Linux上面重新配置一下jdk,我在Linux上面是1.7的,但是eclipse上是1.8的,所以出错了
解决办法:
(1)、查看Linux的jdk版本以及eclipse的版本,简单的就是修改Linux上面的jdk
查看eclipse的jdk版本:
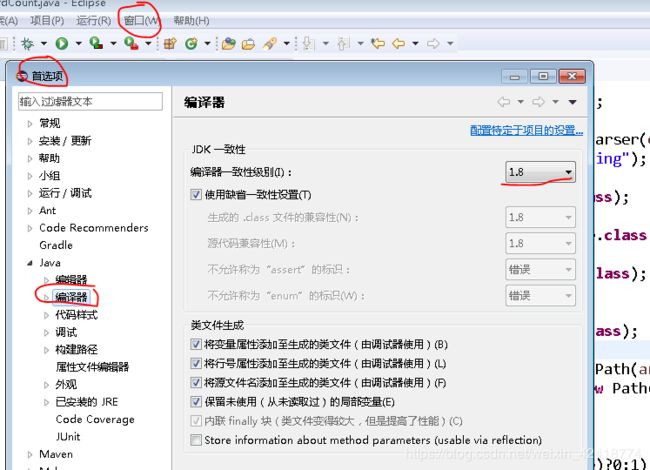
查询Linux上面的jdk,随便在那个目录下面执行:java -version 都可以查看(这里我已经修改了,所以是1.8的版本了)

(2)、下载配置jdk
下载我就不说了,直接去官网下载就好了,然后拉取到服务器目录下面,执行解压命令:
![]()
解压完成后,进去目录,有下图就是解压成功,或者执行javac:

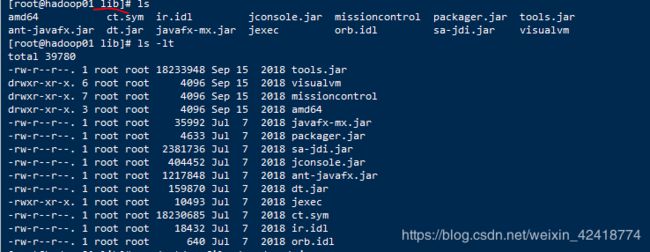
配置文件:
进入vim /etc/profile 添加如下图配置代码:
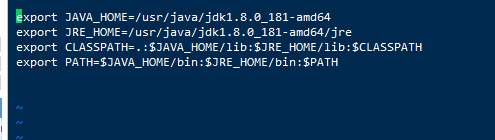
执行:source /etc/profile 命令让环境生效

执行javac,与java -version查看是否成功就可以了,再重复上面的运行代码就可以执行了!
我有一篇博客是用spark来统计单词数的,代码简短,易理解:
https://blog.csdn.net/weixin_42418774/article/details/90677860
到这里为止,我的第一个hadoop伪分布式的jar运行就成功了!!!!