python入门之爬虫篇 爬取图片,文章,网页
一,首先看看Python是如何简单的爬取网页的
1,准备工作
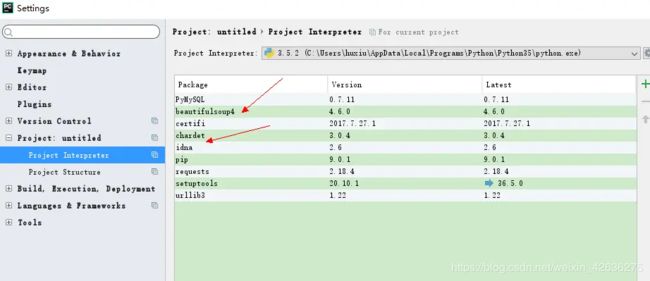
项目用的BeautifulSoup4和chardet模块属于三方扩展包,如果没有请自行pip安装,我是用pycharm来做的安装,下面简单讲下用pycharm安装chardet和BeautifulSoup4
在pycharm的设置里按照下图的步骤操作

如下图搜索你要的扩展类库,如我们这里需要安装chardet直接搜索就行,然后点击install package, BeautifulSoup4做一样的操作就行
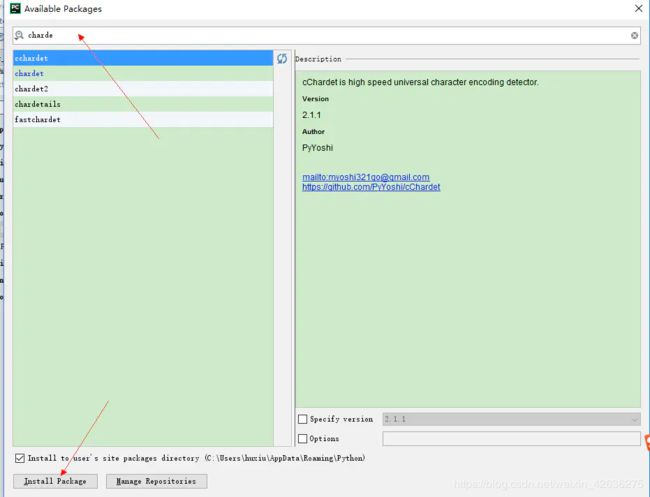
安装成功后就会出现在在安装列表中,到此就说明我们安装网络爬虫扩展库成功
二,由浅入深,我们先抓取网页
我们这里以抓取简书首页为例:http://www.jianshu.com/
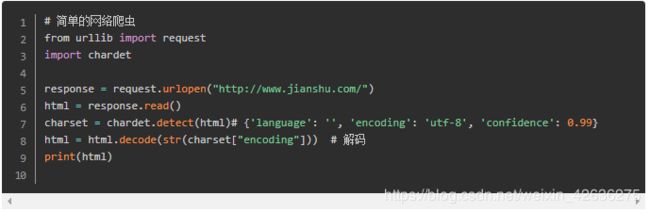
由于抓取的html文档比较长,这里简单贴出来一部分给大家看下
1.
2.
3.
4.
5.
6.
7.
8.
9.
10. 10.
11.
12.
13.
14.
15.
11.
17.
18.
19.
20.
21.
12.
23.
24...........后面省略一大堆
这就是Python3的爬虫简单入门,是不是很简单,建议大家多敲几遍
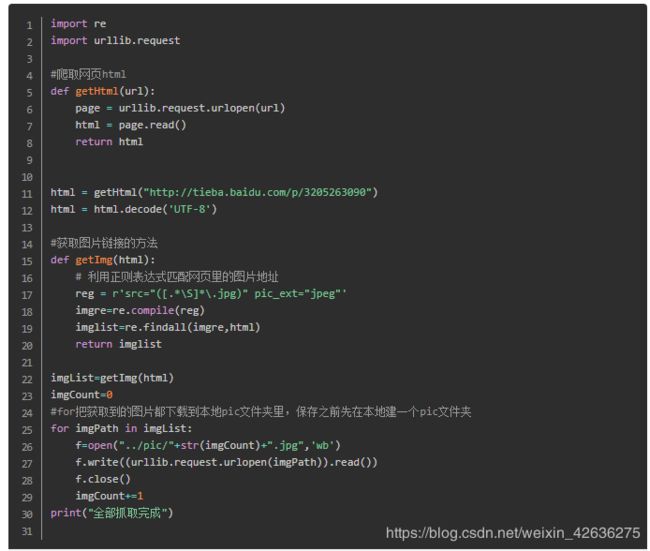
三,Python3爬取网页里的图片并把图片保存到本地文件夹
目标
爬取百度贴吧里的图片
把图片保存到本地,都是妹子图片奥
不多说,直接上代码,代码里的注释很详细。大家仔细阅读注释就可以理解了
迫不及待的看下都爬取到了些什么美图

就这么轻易的爬取到了24个妹子的图片。是不是很简单。
四,Python3爬取新闻网站新闻列表
这里我们只爬取新闻标题,新闻url,新闻图片链接。
爬取到的数据目前只做展示,等我学完Python操作数据库以后会把爬取到的数据保存到数据库。
到这里稍微复杂点,就分布给大家讲解
1 这里我们需要先爬取到html网页上面第一步有讲怎么抓取网页
2分析我们要抓取的html标签
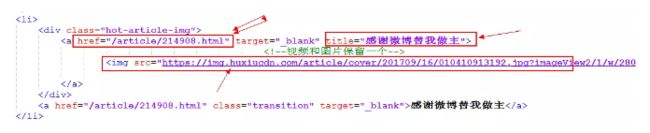
分析上图我们要抓取的信息再div中的a标签和img标签里,所以我们要想的就是怎么获取到这些信息
这里就要用到我们导入的BeautifulSoup4库了,这里的关键代码

上面代码获取到的allList就是我们要获取的新闻列表,抓取到的如下
1.[, , , , , , , , , , ]
这里数据是抓取到了,但是太乱了,并且还有很多不是我们想要的,下面就通过遍历来提炼出我们的有效信息
3 提取有效信息
1.#遍历列表,获取有效信息
2.for news in allList:
3. aaa = news.select(‘a’)
4. # 只选择长度大于0的结果
5. if len(aaa) > 0:
6. # 文章链接
7. try:#如果抛出异常就代表为空
8. href = url + aaa[0][‘href’]
9. except Exception:
10. href=’’
11. # 文章图片url
12. try:
13. imgUrl = aaa[0].select(‘img’)[0][‘src’]
14. except Exception:
15. imgUrl=""
16. # 新闻标题
17. try:
18. title = aaa[0][‘title’]
19. except Exception:
20. title = “标题为空”
21. print(“标题”,title,"\nurl:",href,"\n图片地址:",imgUrl)
22. print("==============================================================================================")
``
这里添加异常处理,主要是有的新闻可能没有标题,没有url或者图片,如果不做异常处理,可能导致我们爬取的中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/article/cover/201708/22/173535862821.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/article/cover/201709/17/094856378420.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/article/cover/201709/17/122655034450.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/article/cover/201709/14/182151300292.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/article/cover/201709/16/210518696352.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/article/cover/201709/15/180620783020.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/article/cover/201709/16/162049096015.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/article/cover/201709/16/010410913192.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/article/cover/201709/17/154147105217.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/article/cover/201709/17/101218317953.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/article/cover/201709/16/213400162818.jpg?imageView2/1/w/280/h/210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
到这里我们抓取新闻网站新闻信息就大功告成了,下面贴出来完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("=============================================================================================="
数据获取到了我们还要把数据存到数据库,只要存到我们的数据库里,数据库里有数据了,就可以做后面的数据分析处理,也可以用这些爬取来的文章,给app提供新闻api接口
最后给你大家分享一些小福利吧
链接:https://pan.baidu.com/s/1sMxwTn7P2lhvzvWRwBjFrQ
提取码:kt2v
链接容易被举报过期,如果失效了就加企鹅群654234959 领取吧