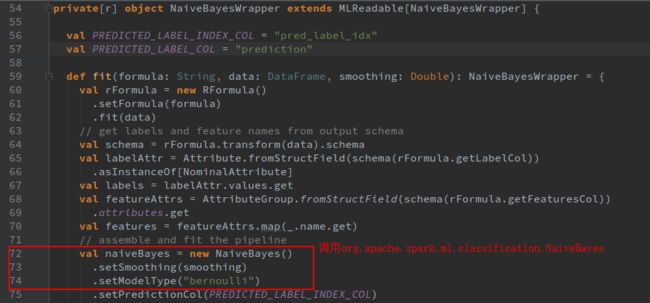
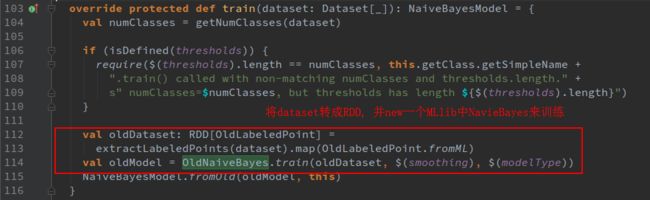
- 店群合一模式下的社区团购新发展——结合链动 2+1 模式、AI 智能名片与 S2B2C 商城小程序源码
说私域
人工智能小程序
摘要:本文探讨了店群合一的社区团购平台在当今商业环境中的重要性和优势。通过分析店群合一模式如何将互联网社群与线下终端紧密结合,阐述了链动2+1模式、AI智能名片和S2B2C商城小程序源码在这一模式中的应用价值。这些创新元素的结合为社区团购带来了新的机遇,提升了用户信任感、拓展了营销渠道,并实现了线上线下的完美融合。一、引言随着互联网技术的不断发展,社区团购作为一种新兴的商业模式,在满足消费者日常需
- 四章-32-点要素的聚合
彩云飘过
本文基于腾讯课堂老胡的课《跟我学Openlayers--基础实例详解》做的学习笔记,使用的openlayers5.3.xapi。源码见1032.html,对应的官网示例https://openlayers.org/en/latest/examples/cluster.htmlhttps://openlayers.org/en/latest/examples/earthquake-clusters.
- DIV+CSS+JavaScript技术制作网页(旅游主题网页设计与制作)云南大理
STU学生网页设计
网页设计期末网页作业html静态网页html5期末大作业网页设计web大作业
️精彩专栏推荐作者主页:【进入主页—获取更多源码】web前端期末大作业:【HTML5网页期末作业(1000套)】程序员有趣的告白方式:【HTML七夕情人节表白网页制作(110套)】文章目录二、网站介绍三、网站效果▶️1.视频演示2.图片演示四、网站代码HTML结构代码CSS样式代码五、更多源码二、网站介绍网站布局方面:计划采用目前主流的、能兼容各大主流浏览器、显示效果稳定的浮动网页布局结构。网站程
- 关于城市旅游的HTML网页设计——(旅游风景云南 5页)HTML+CSS+JavaScript
二挡起步
web前端期末大作业javascripthtmlcss旅游风景
⛵源码获取文末联系✈Web前端开发技术描述网页设计题材,DIV+CSS布局制作,HTML+CSS网页设计期末课程大作业|游景点介绍|旅游风景区|家乡介绍|等网站的设计与制作|HTML期末大学生网页设计作业,Web大学生网页HTML:结构CSS:样式在操作方面上运用了html5和css3,采用了div+css结构、表单、超链接、浮动、绝对定位、相对定位、字体样式、引用视频等基础知识JavaScrip
- libyuv之linux编译
jaronho
Linuxlinux运维服务器
文章目录一、下载源码二、编译源码三、注意事项1、银河麒麟系统(aarch64)(1)解决armv8-a+dotprod+i8mm指令集支持问题(2)解决armv9-a+sve2指令集支持问题一、下载源码到GitHub网站下载https://github.com/lemenkov/libyuv源码,或者用直接用git克隆到本地,如:gitclonehttps://github.com/lemenko
- ArrayList 源码解析
程序猿进阶
Java基础ArrayListListjava面试性能优化架构设计idea
ArrayList是Java集合框架中的一个动态数组实现,提供了可变大小的数组功能。它继承自AbstractList并实现了List接口,是顺序容器,即元素存放的数据与放进去的顺序相同,允许放入null元素,底层通过数组实现。除该类未实现同步外,其余跟Vector大致相同。每个ArrayList都有一个容量capacity,表示底层数组的实际大小,容器内存储元素的个数不能多于当前容量。当向容器中添
- Python神器!WEB自动化测试集成工具 DrissionPage
亚丁号
python开发语言
一、前言用requests做数据采集面对要登录的网站时,要分析数据包、JS源码,构造复杂的请求,往往还要应付验证码、JS混淆、签名参数等反爬手段,门槛较高。若数据是由JS计算生成的,还须重现计算过程,体验不好,开发效率不高。使用浏览器,可以很大程度上绕过这些坑,但浏览器运行效率不高。因此,这个库设计初衷,是将它们合而为一,能够在不同须要时切换相应模式,并提供一种人性化的使用方法,提高开发和运行效率
- 笋丁网页自动回复机器人V3.0.0免授权版源码
希希分享
软希网58soho_cn源码资源笋丁网页自动回复机器人
笋丁网页机器人一款可设置自动回复,默认消息,调用自定义api接口的网页机器人。此程序后端语言使用Golang,内存占用最高不超过30MB,1H1G服务器流畅运行。仅支持Linux服务器部署,不支持虚拟主机,请悉知!使用自定义api功能需要有一定的建站基础。源码下载:https://download.csdn.net/download/m0_66047725/89754250更多资源下载:关注我。安
- ESP32-C3入门教程 网络篇⑩——基于esp_https_ota和MQTT实现开机主动升级和被动触发升级的OTA功能
小康师兄
ESP32-C3入门教程https服务器esp32OTAMQTT
文章目录一、前言二、软件流程三、部分源码四、运行演示一、前言本文基于VSCodeIDE进行编程、编译、下载、运行等操作基础入门章节请查阅:ESP32-C3入门教程基础篇①——基于VSCode构建HelloWorld教程目录大纲请查阅:ESP32-C3入门教程——导读ESP32-C3入门教程网络篇⑨——基于esp_https_ota实现史上最简单的ESP32OTA远程固件升级功能二、软件流程
- 【Python搞定车载自动化测试】——Python实现车载以太网DoIP刷写(含Python源码)
疯狂的机器人
Python搞定车载自动化pythonDoIPUDSISO142291SO13400Bootloadertcp/ip
系列文章目录【Python搞定车载自动化测试】系列文章目录汇总文章目录系列文章目录前言一、环境搭建1.软件环境2.硬件环境二、目录结构三、源码展示1.DoIP诊断基础函数方法2.DoIP诊断业务函数方法3.27服务安全解锁4.DoIP自动化刷写四、测试日志1.测试日志五、完整源码链接前言随着智能电动汽车行业的发展,汽车=智能终端+四个轮子,各家车企都推出了各自的OTA升级方案,本章节主要介绍如何使
- 进销存小程序源码 PHP网络版ERP进销存管理系统 全开源可二开
摸鱼小号
php
可直接源码搭建部署发布后使用:一、功能模块介绍该系统模板主要有进,销,存三个主要模板功能组成,下面将介绍各模块所对应的功能;进:需要将产品采购入库,自动生成采购明细台账同时关联财务生成付款账单;销:是指对客户的销售订单记录,汇总生成产品销售明细及回款计划;存:库存的日常盘点与统计,库存下限预警、出入库台账、库存位置等。1.进购管理采购订单:采购下单审批→由上级审批通过采购入库;采购入库:货品到货>
- 计算机毕业设计PHP仓储综合管理系统(源码+程序+VUE+lw+部署)
java毕设程序源码王哥
php课程设计vue.js
该项目含有源码、文档、程序、数据库、配套开发软件、软件安装教程。欢迎交流项目运行环境配置:phpStudy+Vscode+Mysql5.7+HBuilderX+Navicat11+Vue+Express。项目技术:原生PHP++Vue等等组成,B/S模式+Vscode管理+前后端分离等等。环境需要1.运行环境:最好是小皮phpstudy最新版,我们在这个版本上开发的。其他版本理论上也可以。2.开发
- JVM源码分析之堆外内存完全解读
HeapDump性能社区
概述广义的堆外内存说到堆外内存,那大家肯定想到堆内内存,这也是我们大家接触最多的,我们在jvm参数里通常设置-Xmx来指定我们的堆的最大值,不过这还不是我们理解的Java堆,-Xmx的值是新生代和老生代的和的最大值,我们在jvm参数里通常还会加一个参数-XX:MaxPermSize来指定持久代的最大值,那么我们认识的Java堆的最大值其实是-Xmx和-XX:MaxPermSize的总和,在分代算法
- html+css网页设计 旅游网站首页1个页面
html+css+js网页设计
htmlcss旅游
html+css网页设计旅游网站首页1个页面网页作品代码简单,可使用任意HTML辑软件(如:Dreamweaver、HBuilder、Vscode、Sublime、Webstorm、Text、Notepad++等任意html编辑软件进行运行及修改编辑等操作)。获取源码1,访问该网站https://download.csdn.net/download/qq_42431718/897527112,点击
- Istio pilot-discovery服务发现源码解析(1.13版本)
xidianjiapei001
#Istioistio云原生服务发现
Istiopilot-discovery服务发现介绍工作机制初始化初始化Config控制器初始化Service控制器controller初始化NamespaceServiceNodePodPilotDiscovery各组件启动流程DiscoveryServer接收Envoy的gRPC连接请求流程Config变化后向Envoy推送更新的流程总结参考介绍IstioPilot的代码分为Pilot-Dis
- python中文版软件下载-Python中文版
编程大乐趣
python中文版是一种面向对象的解释型计算机程序设计语言。python中文版官网面向对象编程,拥有高效的高级数据结构和简单而有效的方法,其优雅的语法、动态类型、以及天然的解释能力,让它成为理想的语言。软件功能强大,简单易学,可以帮助用户快速编写代码,而且代码运行速度非常快,几乎可以支持所有的操作系统,实用性真的超高的。python中文版软件介绍:python中文版的解释器及其扩展标准库的源码和编
- Scanpy源码浅析之pp.normalize_total
何物昂
版本导入Scanpy,其版本为'1.9.1',如果你看到的源码和下文有差异,其可能是由于版本差异。importscanpyasscsc.__version__#'1.9.1'例子函数pp.normalize_total用于Normalizecountspercell,其源代码在scanpy/preprocessing/_normalization.py我们通过一个简单例子来了解该函数主要功能:将一
- 基于JavaWeb开发的Java+SpringMvc+vue+element实现上海汽车博物馆平台
网顺技术团队
成品程序项目javavue.js汽车课程设计springboot
基于JavaWeb开发的Java+SpringMvc+vue+element实现上海汽车博物馆平台作者主页网顺技术团队欢迎点赞收藏⭐留言文末获取源码联系方式查看下方微信号获取联系方式承接各种定制系统精彩系列推荐精彩专栏推荐订阅不然下次找不到哟Java毕设项目精品实战案例《1000套》感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人文章目录基
- 【K8s】专题十一:Kubernetes 集群证书过期处理方法
行者Sun1989
Kuberneteskubernetes云原生容器
本文内容均来自个人笔记并重新梳理,如有错误欢迎指正!如果对您有帮助,烦请点赞、关注、转发、订阅专栏!专栏订阅入口Linux专栏|Docker专栏|Kubernetes专栏往期精彩文章【Docker】(全网首发)KylinV10下MySQL容器内存占用异常的解决方法【Docker】(全网首发)KylinV10下MySQL容器内存占用异常的解决方法(续)【Docker】MySQL源码构建Docker镜
- SAP自动化-ME12批量更新最后一行的价格
小九不懂SAP
自动化SAPpython
Python源码#-Begin-----------------------------------------------------------------#-Includes--------------------------------------------------------------importsys,win32com.clientimportosimporttime#-Sub
- linux gcc 格式,Linux下gcc与gdb简介
神奇的战士
linuxgcc格式
gcc编译器可以将C、C++等语言源程序、汇编程序编译、链接成可执行程序。gdb是GNU开发的一个Unix/Linux下强大的程序调试工具。linux下没有后缀名的概念。但gcc根据文件的后缀来区别输入文件的类别:.cC语言源代码文件.a由目标文件构成的库文件.C、.cc、.cppC++源码文件.h头文件.i经过预处理之后的C语言文件.ii经过预处理之后的C++文件.o编译后的目标文件.s汇编源码
- 浅谈openresty
爱编码的钓鱼佬
nginxopenresty运维
熟悉了nginx后再来看openresty,不得不说openresty是比较优秀的。对nginx和openresty的历史等在这此就不介绍了。首先对标nginx,自然有优劣一、开发难度nginx:毫无疑问nginx的开发难度比较高,需要扎实的c/c++基础,而且还需要对nginx源码比较熟悉,开发效率慢,比如实现一个类似echo的功能,至少要上百行代码。而openresty只需要一句ngx.say
- Golang Channel
PandaSkr
golang
Channel解析1.Channel源码分析1.1Channel数据结构typehchanstruct{qcountuint//channel的元素数量dataqsizuint//channel循环队列长度bufunsafe.Pointer//指向循环队列的指针elemsizeuint16//元素大小closeduint32//channel是否关闭0-未关闭elemtype*_type//元素类
- 分享一个基于python的电子书数据采集与可视化分析 hadoop电子书数据分析与推荐系统 spark大数据毕设项目(源码、调试、LW、开题、PPT)
计算机源码社
Python项目大数据大数据pythonhadoop计算机毕业设计选题计算机毕业设计源码数据分析spark毕设
作者:计算机源码社个人简介:本人八年开发经验,擅长Java、Python、PHP、.NET、Node.js、Android、微信小程序、爬虫、大数据、机器学习等,大家有这一块的问题可以一起交流!学习资料、程序开发、技术解答、文档报告如需要源码,可以扫取文章下方二维码联系咨询Java项目微信小程序项目Android项目Python项目PHP项目ASP.NET项目Node.js项目选题推荐项目实战|p
- 使用FPGA接收MIPI CSI RX信号并进行去抖动、RGB转YUV处理:FX3014 USB3.0 UVC传输与帧率控制源代码,FPGA实现MIPI CSI RX接收,去Debayer, RGB转
kVfINoSzdrt
fpga开发程序人生
fpgamipicsirx接收去debayer,rgb转yuv,fx3014usb3.0uvc传输与帧率控制源代码,具体架构看图,除dphy物理层外,mipi均为源码sensorimx219mipi源码mipi4lanecsirxraw10fpgamachXO3lf-690usb3.0fx301432bityuvdatawithframesync测试模式3280*246415fps1920*108
- 移动订货小程序哪个好 批发订货系统源码哪个好
多用户商城系统
订货系统源码移动订货小程序批发订货系统订货系统源码
订货小程序就是依托微信小程序的订货系统,微信小程序订货系统相较于其他终端的订货方式,能够更快进入商城,对经销商而言更为方便。今天,我们一起盘点三个主流的移动订货小程序,看看哪个移动订货小程序好。第一、核货宝订货小程序核货宝是商淘科技旗下的订货系统,可为批发企业提供不同客户不同商品、不同客户不同价格快速订货和商家账期管理。功能介绍:客户批发订货的专属数字化订货系统,可以移动端订货。与传统手写开单相比
- MacOS Catalina 从源码构建Qt6.2开发库之01: 编译Qt6.2源代码
捕鲸叉
QTmacosc++QT
安装xcode,cmake,ninjabrewinstallnodemac下安装OpenGL库并使之对各项目可见在macOS上安装OpenGL通常涉及到安装一些依赖库,如MGL、GLUT或者是GLEW等,同时确保LLVM的OpenGL框架和相关工具链的兼容性。以下是一个基本的安装步骤,你可以在终端中执行:安装Homebrew(如果还没有安装的话):/bin/bash-c"$(curl-fsSLht
- 基于Python执行lua脚本
xu-jssy
Python自动化脚本pythonlua自动化rpa
一、依赖安装pipinstalllupa二、源码将lua文件存放在base_path路径,将lua文件名称(不包含后缀名)传递给lua_runner函数即可importmultiprocessingimportlupa#lua文件存放位置base_path='D:\\test\\lua'classLuaFuncion:#创建Lua运行时环境lua=lupa.LuaRuntime(unpack_re
- Python实现mysql命令行
xu-jssy
pythonmysqladb
一、源码importosimportpymysqldefsql_shell():password=input("EnterPassword:")#访问密码ifpassword.strip()!="yyds":print("Bye")return#清空控制台输出os.system("cls"ifos.name=="nt"else"clear")try:#连接到MySQL数据库conn=pymysql
- Java集合类框架源码分析 之 RoleList源码解析 【6】
yunzhonghefei
Java集合类源码分析RoleList源码解析
该类继承于ArrayList,针对Role进行了一些扩展。其他方法和ArrayList中基本相同,源码不做针对性分析:看一下类简介:/***代表了一个roles的列表,作为方法setRoles()的参数,去创建一个关联关系,并且尝试在同一个关系中设置多个角色。*ARoleListrepresentsalistofroles(Roleobjects).Itisusedas*parameterwhen
- xml解析
小猪猪08
xml
1、DOM解析的步奏
准备工作:
1.创建DocumentBuilderFactory的对象
2.创建DocumentBuilder对象
3.通过DocumentBuilder对象的parse(String fileName)方法解析xml文件
4.通过Document的getElem
- 每个开发人员都需要了解的一个SQL技巧
brotherlamp
linuxlinux视频linux教程linux自学linux资料
对于数据过滤而言CHECK约束已经算是相当不错了。然而它仍存在一些缺陷,比如说它们是应用到表上面的,但有的时候你可能希望指定一条约束,而它只在特定条件下才生效。
使用SQL标准的WITH CHECK OPTION子句就能完成这点,至少Oracle和SQL Server都实现了这个功能。下面是实现方式:
CREATE TABLE books (
id &
- Quartz——CronTrigger触发器
eksliang
quartzCronTrigger
转载请出自出处:http://eksliang.iteye.com/blog/2208295 一.概述
CronTrigger 能够提供比 SimpleTrigger 更有具体实际意义的调度方案,调度规则基于 Cron 表达式,CronTrigger 支持日历相关的重复时间间隔(比如每月第一个周一执行),而不是简单的周期时间间隔。 二.Cron表达式介绍 1)Cron表达式规则表
Quartz
- Informatica基础
18289753290
InformaticaMonitormanagerworkflowDesigner
1.
1)PowerCenter Designer:设计开发环境,定义源及目标数据结构;设计转换规则,生成ETL映射。
2)Workflow Manager:合理地实现复杂的ETL工作流,基于时间,事件的作业调度
3)Workflow Monitor:监控Workflow和Session运行情况,生成日志和报告
4)Repository Manager:
- linux下为程序创建启动和关闭的的sh文件,scrapyd为例
酷的飞上天空
scrapy
对于一些未提供service管理的程序 每次启动和关闭都要加上全部路径,想到可以做一个简单的启动和关闭控制的文件
下面以scrapy启动server为例,文件名为run.sh:
#端口号,根据此端口号确定PID
PORT=6800
#启动命令所在目录
HOME='/home/jmscra/scrapy/'
#查询出监听了PORT端口
- 人--自私与无私
永夜-极光
今天上毛概课,老师提出一个问题--人是自私的还是无私的,根源是什么?
从客观的角度来看,人有自私的行为,也有无私的
- Ubuntu安装NS-3 环境脚本
随便小屋
ubuntu
将附件下载下来之后解压,将解压后的文件ns3environment.sh复制到下载目录下(其实放在哪里都可以,就是为了和我下面的命令相统一)。输入命令:
sudo ./ns3environment.sh >>result
这样系统就自动安装ns3的环境,运行的结果在result文件中,如果提示
com
- 创业的简单感受
aijuans
创业的简单感受
2009年11月9日我进入a公司实习,2012年4月26日,我离开a公司,开始自己的创业之旅。
今天是2012年5月30日,我忽然很想谈谈自己创业一个月的感受。
当初离开边锋时,我就对自己说:“自己选择的路,就是跪着也要把他走完”,我也做好了心理准备,准备迎接一次次的困难。我这次走出来,不管成败
- 如何经营自己的独立人脉
aoyouzi
如何经营自己的独立人脉
独立人脉不是父母、亲戚的人脉,而是自己主动投入构造的人脉圈。“放长线,钓大鱼”,先行投入才能产生后续产出。 现在几乎做所有的事情都需要人脉。以银行柜员为例,需要拉储户,而其本质就是社会人脉,就是社交!很多人都说,人脉我不行,因为我爸不行、我妈不行、我姨不行、我舅不行……我谁谁谁都不行,怎么能建立人脉?我这里说的人脉,是你的独立人脉。 以一个普通的银行柜员
- JSP基础
百合不是茶
jsp注释隐式对象
1,JSP语句的声明
<%! 声明 %> 声明:这个就是提供java代码声明变量、方法等的场所。
表达式 <%= 表达式 %> 这个相当于赋值,可以在页面上显示表达式的结果,
程序代码段/小型指令 <% 程序代码片段 %>
2,JSP的注释
<!-- -->
- web.xml之session-config、mime-mapping
bijian1013
javaweb.xmlservletsession-configmime-mapping
session-config
1.定义:
<session-config>
<session-timeout>20</session-timeout>
</session-config>
2.作用:用于定义整个WEB站点session的有效期限,单位是分钟。
mime-mapping
1.定义:
<mime-m
- 互联网开放平台(1)
Bill_chen
互联网qq新浪微博百度腾讯
现在各互联网公司都推出了自己的开放平台供用户创造自己的应用,互联网的开放技术欣欣向荣,自己总结如下:
1.淘宝开放平台(TOP)
网址:http://open.taobao.com/
依赖淘宝强大的电子商务数据,将淘宝内部业务数据作为API开放出去,同时将外部ISV的应用引入进来。
目前TOP的三条主线:
TOP访问网站:open.taobao.com
ISV后台:my.open.ta
- 【MongoDB学习笔记九】MongoDB索引
bit1129
mongodb
索引
可以在任意列上建立索引
索引的构造和使用与传统关系型数据库几乎一样,适用于Oracle的索引优化技巧也适用于Mongodb
使用索引可以加快查询,但同时会降低修改,插入等的性能
内嵌文档照样可以建立使用索引
测试数据
var p1 = {
"name":"Jack",
"age&q
- JDBC常用API之外的总结
白糖_
jdbc
做JAVA的人玩JDBC肯定已经很熟练了,像DriverManager、Connection、ResultSet、Statement这些基本类大家肯定很常用啦,我不赘述那些诸如注册JDBC驱动、创建连接、获取数据集的API了,在这我介绍一些写框架时常用的API,大家共同学习吧。
ResultSetMetaData获取ResultSet对象的元数据信息
- apache VelocityEngine使用记录
bozch
VelocityEngine
VelocityEngine是一个模板引擎,能够基于模板生成指定的文件代码。
使用方法如下:
VelocityEngine engine = new VelocityEngine();// 定义模板引擎
Properties properties = new Properties();// 模板引擎属
- 编程之美-快速找出故障机器
bylijinnan
编程之美
package beautyOfCoding;
import java.util.Arrays;
public class TheLostID {
/*编程之美
假设一个机器仅存储一个标号为ID的记录,假设机器总量在10亿以下且ID是小于10亿的整数,假设每份数据保存两个备份,这样就有两个机器存储了同样的数据。
1.假设在某个时间得到一个数据文件ID的列表,是
- 关于Java中redirect与forward的区别
chenbowen00
javaservlet
在Servlet中两种实现:
forward方式:request.getRequestDispatcher(“/somePage.jsp”).forward(request, response);
redirect方式:response.sendRedirect(“/somePage.jsp”);
forward是服务器内部重定向,程序收到请求后重新定向到另一个程序,客户机并不知
- [信号与系统]人体最关键的两个信号节点
comsci
系统
如果把人体看做是一个带生物磁场的导体,那么这个导体有两个很重要的节点,第一个在头部,中医的名称叫做 百汇穴, 另外一个节点在腰部,中医的名称叫做 命门
如果要保护自己的脑部磁场不受到外界有害信号的攻击,最简单的
- oracle 存储过程执行权限
daizj
oracle存储过程权限执行者调用者
在数据库系统中存储过程是必不可少的利器,存储过程是预先编译好的为实现一个复杂功能的一段Sql语句集合。它的优点我就不多说了,说一下我碰到的问题吧。我在项目开发的过程中需要用存储过程来实现一个功能,其中涉及到判断一张表是否已经建立,没有建立就由存储过程来建立这张表。
CREATE OR REPLACE PROCEDURE TestProc
IS
fla
- 为mysql数据库建立索引
dengkane
mysql性能索引
前些时候,一位颇高级的程序员居然问我什么叫做索引,令我感到十分的惊奇,我想这绝不会是沧海一粟,因为有成千上万的开发者(可能大部分是使用MySQL的)都没有受过有关数据库的正规培训,尽管他们都为客户做过一些开发,但却对如何为数据库建立适当的索引所知较少,因此我起了写一篇相关文章的念头。 最普通的情况,是为出现在where子句的字段建一个索引。为方便讲述,我们先建立一个如下的表。
- 学习C语言常见误区 如何看懂一个程序 如何掌握一个程序以及几个小题目示例
dcj3sjt126com
c算法
如果看懂一个程序,分三步
1、流程
2、每个语句的功能
3、试数
如何学习一些小算法的程序
尝试自己去编程解决它,大部分人都自己无法解决
如果解决不了就看答案
关键是把答案看懂,这个是要花很大的精力,也是我们学习的重点
看懂之后尝试自己去修改程序,并且知道修改之后程序的不同输出结果的含义
照着答案去敲
调试错误
- centos6.3安装php5.4报错
dcj3sjt126com
centos6
报错内容如下:
Resolving Dependencies
--> Running transaction check
---> Package php54w.x86_64 0:5.4.38-1.w6 will be installed
--> Processing Dependency: php54w-common(x86-64) = 5.4.38-1.w6 for
- JSONP请求
flyer0126
jsonp
使用jsonp不能发起POST请求。
It is not possible to make a JSONP POST request.
JSONP works by creating a <script> tag that executes Javascript from a different domain; it is not pos
- Spring Security(03)——核心类简介
234390216
Authentication
核心类简介
目录
1.1 Authentication
1.2 SecurityContextHolder
1.3 AuthenticationManager和AuthenticationProvider
1.3.1 &nb
- 在CentOS上部署JAVA服务
java--hhf
javajdkcentosJava服务
本文将介绍如何在CentOS上运行Java Web服务,其中将包括如何搭建JAVA运行环境、如何开启端口号、如何使得服务在命令执行窗口关闭后依旧运行
第一步:卸载旧Linux自带的JDK
①查看本机JDK版本
java -version
结果如下
java version "1.6.0"
- oracle、sqlserver、mysql常用函数对比[to_char、to_number、to_date]
ldzyz007
oraclemysqlSQL Server
oracle &n
- 记Protocol Oriented Programming in Swift of WWDC 2015
ningandjin
protocolWWDC 2015Swift2.0
其实最先朋友让我就这个题目写篇文章的时候,我是拒绝的,因为觉得苹果就是在炒冷饭, 把已经流行了数十年的OOP中的“面向接口编程”还拿来讲,看完整个Session之后呢,虽然还是觉得在炒冷饭,但是毕竟还是加了蛋的,有些东西还是值得说说的。
通常谈到面向接口编程,其主要作用是把系统��设计和具体实现分离开,让系统的每个部分都可以在不影响别的部分的情况下,改变自身的具体实现。接口的设计就反映了系统
- 搭建 CentOS 6 服务器(15) - Keepalived、HAProxy、LVS
rensanning
keepalived
(一)Keepalived
(1)安装
# cd /usr/local/src
# wget http://www.keepalived.org/software/keepalived-1.2.15.tar.gz
# tar zxvf keepalived-1.2.15.tar.gz
# cd keepalived-1.2.15
# ./configure
# make &a
- ORACLE数据库SCN和时间的互相转换
tomcat_oracle
oraclesql
SCN(System Change Number 简称 SCN)是当Oracle数据库更新后,由DBMS自动维护去累积递增的一个数字,可以理解成ORACLE数据库的时间戳,从ORACLE 10G开始,提供了函数可以实现SCN和时间进行相互转换;
用途:在进行数据库的还原和利用数据库的闪回功能时,进行SCN和时间的转换就变的非常必要了;
操作方法: 1、通过dbms_f
- Spring MVC 方法注解拦截器
xp9802
spring mvc
应用场景,在方法级别对本次调用进行鉴权,如api接口中有个用户唯一标示accessToken,对于有accessToken的每次请求可以在方法加一个拦截器,获得本次请求的用户,存放到request或者session域。
python中,之前在python flask中可以使用装饰器来对方法进行预处理,进行权限处理
先看一个实例,使用@access_required拦截:
?