深入浅出kubernetes之client-go的SharedInformer
记得大学刚毕业那年看了侯俊杰的《深入浅出MFC》,就对深入浅出这四个字特别偏好,并且成为了自己对技术的要求标准——对于技术的理解要足够的深刻以至于可以用很浅显的道理给别人讲明白。以下内容为个人见解,如有雷同,纯属巧合,如有错误,烦请指正。
本文基于kubernetes1.11版本,后续会根据kubernetes版本更新及时更新文档,所有代码引用为了简洁都去掉了日志打印相关的代码,尽量只保留有价值的内容。
在开始本文内容前,请先阅读《深入浅出kubernetes之client-go的indexer》和《深入浅出kubernetes之client-go的DeltaFIFO》。
目录
ListerWatcher
Reflector实现
Controller实现
CacheMutationDetector
processorListener分析
总结
SharedInformer概述
Informer(就是SharedInformer)是client-go的重要组成部分,在了解client-go之前,了解一下Informer的实现是很有必要的,下面引用了官方的图,可以看到Informer在client-go中的位置。

前期铺垫了Indexer和DeltaFIFO,为的就是方便本文的理解,也是时候来一个长篇大论了。SharedInformer总名字上直译就是信息提供者,至于Shared是什么意思,我们来看看官方注释:
// SharedInformer has a shared data cache and is capable of distributing notifications for changes
// to the cache to multiple listeners who registered via AddEventHandler不难看出Shared指的是多个listeners共享同一个cache,而且资源的变化会同时通知到cache和listeners。这个解释和上面图所展示的内容的是一致的,cache我们在Indexer的介绍中已经分析过了,listerners指的就是OnAdd、OnUpdate、OnDelete这些回调函数背后的对象,本文就要对Informer进行系统性的分析。我们先对上面的图做一些初步的认识:
- List/Watch:List是列举apiserver中对象的接口,Watch是监控apiserver资源变化的接口;
- Reflector:我习惯成称之为反射器,实现对apiserver指定类型对象的监控,其中反射实现的就是把监控的结果实例化成具体的对象;
- DeltaIFIFO:将Reflector监控的变化的对象形成一个FIFO队列,此处的Delta就是变化,DeltaFIFO我们已经有文章详细介绍了;
- LocalStore:指的就是Indexer的实现cache,这里面缓存的就是apiserver中的对象(其中有一部分可能还在DeltaFIFO中),此时使用者再查询对象的时候就直接从cache中查找,减少了apiserver的压力;
- Callbacks:通知回调函数,Infomer感知的所有对象变化都是通过回调函数通知使用者(Listener);
ListerWatcher
ListerWatcher是一个interface类型,定义如下:
// 代码源自client-go/tools/cache/listwatch.go
// 其中metav1.ListOptions,runtime.Object,watch.Interface都定义在apimachinery这个包中
type ListerWatcher interface {
// 根据选项列举对象
List(options metav1.ListOptions) (runtime.Object, error)
// 根据选项监控对象变化
Watch(options metav1.ListOptions) (watch.Interface, error)
}这里面我们不会无限的展开下去,只要知道ListerWatcher是通过apiserver的API来列举和监控的就行了,具体是如何实现的其实当前来看并不重要。需要注意一点:ListerWatcher是针对某一类对象的,比如Pod,不是所有对象的,这个在构造ListerWatcher对象的时候由apiserver的client类型决定了。
Reflector实现
为了方便理解,本章节引入资源的概念,其实对于kubernetes资源和对象是同一个东西,只是我更喜欢称之为对象。但是下面需要引入同类对象这个概念,所以采用资源代表同类对象的集合(例如Pod集合)。按照惯例,我们先从类型定义入手:
// 代码源自client-go/tools/cache/reflector.go
type Reflector struct {
name string // 名字
metrics *reflectorMetrics // 但凡遇到metrics多半是用于做监控的,可以忽略
expectedType reflect.Type // 反射的类型,也就是要监控的对象类型,比如Pod
store Store // 存储,就是DeltaFIFO,为什么,后面会有代码证明
listerWatcher ListerWatcher // 这个是用来从apiserver获取资源用的
period time.Duration // 反射器在List和Watch的时候理论上是死循环,只有出现错误才会退出
// 这个变量用在出错后多长时间再执行List和Watch,默认值是1秒钟
resyncPeriod time.Duration // 重新同步的周期,很多人肯定认为这个同步周期指的是从apiserver的同步周期
// 其实这里面同步指的是shared_informer使用者需要定期同步全量对象
ShouldResync func() bool // 如果需要同步,调用这个函数问一下,当然前提是该函数指针不为空
clock clock.Clock // 时钟
lastSyncResourceVersion string // 最后一次同步的资源版本
lastSyncResourceVersionMutex sync.RWMutex // 还专门为最后一次同步的资源版本弄了个锁
}根据上面定义的成员变量,我们可以推导出:
- listerWatcher用于获取和监控资源,lister可以获取对象的全量,watcher可以获取对象的增量(变化);
- 系统会周期性的执行list-watch的流程,一旦过程中失败就要重新执行流程,这个重新执行的周期就是period指定的;
- expectedType规定了监控对象的类型,非此类型的对象将会被忽略;
- 实例化后的expectedType类型的对象会被添加到store中;
- kubernetes资源在apiserver中都是有版本的,对象的任何除了修改(添加、删除、更新)都会造成资源版本更新,所以lastSyncResourceVersion就是指的这个版本;
- 如果使用者需要定期同步全量对象,那么Reflector就会定期产生全量对象的同步事件给DeltaFIFO;
按照上面的推导,基本每个成员变量都涉及到了,仿佛我们已经知道Reflector的工作原理了,下面我们就要通过源码逐一验证上面的推导。Reflector有一个Run()函数,这个是Reflector的核心功能流程,我们可以沿着这个流程分析:
// 代码源自client-go/tools/cache/reflector.go
func (r *Reflector) Run(stopCh <-chan struct{}) {
// func Until(f func(), period time.Duration, stopCh <-chan struct{})是下面函数的声明
// 这里面我们不用关心wait.Until是如何实现的,只要知道他调用函数f会被每period周期执行一次
// 意思就是f()函数执行完毕再等period时间后在执行一次,也就是r.ListAndWatch()会被周期性的调用
wait.Until(func() {
if err := r.ListAndWatch(stopCh); err != nil {
utilruntime.HandleError(err)
}
}, r.period, stopCh)
}从这里看,代码的实现符合推导2,我们继续看ListAndWatch()函数实现:
// 代码源自client-go/tools/cache/reflector.go
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {
var resourceVersion string
// 很多存储类的系统都是这样设计的,数据采用版本的方式记录,数据每变化(添加、删除、更新)都会触发版本更新,
// 这样的做法可以避免全量数据访问。以apiserver资源监控为例,只要监控比缓存中资源版本大的对象就可以了,
// 把变化的部分更新到缓存中就可以达到与apiserver一致的效果,一般资源的初始版本为0,从0版本开始列举就是全量的对象了
options := metav1.ListOptions{ResourceVersion: "0"}
// 与监控相关的内容不多解释
r.metrics.numberOfLists.Inc()
start := r.clock.Now()
// 列举资源,这部分是apimachery相关的内容,读者感兴趣可以自己了解
list, err := r.listerWatcher.List(options)
if err != nil {
return fmt.Errorf("%s: Failed to list %v: %v", r.name, r.expectedType, err)
}
// 还是监控相关的
r.metrics.listDuration.Observe(time.Since(start).Seconds())
// 下面的代码主要是利用apimachinery相关的函数实现,就是把列举返回的结果转换为对象数组
// 下面的代码大部分来自apimachinery,此处不做过多说明,读者只要知道实现什么功能就行了
listMetaInterface, err := meta.ListAccessor(list)
if err != nil {
return fmt.Errorf("%s: Unable to understand list result %#v: %v", r.name, list, err)
}
resourceVersion = listMetaInterface.GetResourceVersion()
items, err := meta.ExtractList(list)
if err != nil {
return fmt.Errorf("%s: Unable to understand list result %#v (%v)", r.name, list, err)
}
// 和监控相关的内容
r.metrics.numberOfItemsInList.Observe(float64(len(items)))
// 以上部分都是对象实例化的过程,可以称之为反射,也是Reflector这个名字的主要来源,本文不是讲解反射原理的,
// 而是作为SharedInformer的前端,所以我们重点介绍的是对象在SharedInformer中流转过程,所以反射原理部分不做为重点讲解
// 这可是真正从apiserver同步过来的全量对象,所以要同步到DeltaFIFO中
if err := r.syncWith(items, resourceVersion); err != nil {
return fmt.Errorf("%s: Unable to sync list result: %v", r.name, err)
}
// 设置最新的同步的对象版本
r.setLastSyncResourceVersion(resourceVersion)
// 下面要启动一个后台协程实现定期的同步操作,这个同步就是将SharedInformer里面的对象全量以同步事件的方式通知使用者
// 我们暂且称之为“后台同步协程”,Run()函数退出需要后台同步协程退出,所以下面的cancelCh就是干这个用的
// 利用defer close(cancelCh)实现的,而resyncerrc是后台同步协程反向通知Run()函数的报错通道
// 当后台同步协程出错,Run()函数接收到信号就可以退出了
resyncerrc := make(chan error, 1)
cancelCh := make(chan struct{})
defer close(cancelCh)
// 下面这个匿名函数就是后台同步协程的函数了
go func() {
// resyncCh返回的就是一个定时器,如果resyncPeriod这个为0那么就会返回一个永久定时器,cleanup函数是用来清理定时器的
resyncCh, cleanup := r.resyncChan()
defer func() {
cleanup()
}()
// 死循环等待各种信号
for {
// 只有定时器有信号才继续处理,其他的都会退出
select {
case <-resyncCh:
case <-stopCh:
return
case <-cancelCh:
return
}
// ShouldResync是个函数地址,创建反射器对象的时候传入,即便时间到了,也要通过函数问问是否需要同步
if r.ShouldResync == nil || r.ShouldResync() {
// 我们知道这个store是DeltaFIFO,DeltaFIFO.Resync()做了什么,读者自行温习相关的文章~
// 就在这里实现了我们前面提到的同步,从这里看所谓的同步就是以全量对象同步事件的方式通知使用者
if err := r.store.Resync(); err != nil {
resyncerrc <- err
return
}
}
// 清理掉当前的计时器,获取下一个同步时间定时器
cleanup()
resyncCh, cleanup = r.resyncChan()
}
}()
// 前面已经列举了全量对象,接下来就是watch的逻辑了
for {
// 如果有退出信号就立刻返回,否则就会往下走,因为有default.
select {
case <-stopCh:
return nil
default:
}
// 计算watch的超时时间
timeoutSeconds := int64(minWatchTimeout.Seconds() * (rand.Float64() + 1.0))
// 设置watch的选项,因为前期列举了全量对象,从这里只要监听最新版本以后的资源就可以了
// 如果没有资源变化总不能一直挂着吧?也不知道是卡死了还是怎么了,所以有一个超时会好一点
options = metav1.ListOptions{
ResourceVersion: resourceVersion,
TimeoutSeconds: &timeoutSeconds,
}
// 监控相关
r.metrics.numberOfWatches.Inc()
// 开始监控对象
w, err := r.listerWatcher.Watch(options)
// watch产生错误了,大部分错误就要退出函数然后再重新来一遍流程
if err != nil {
switch err {
case io.EOF:
case io.ErrUnexpectedEOF:
default:
utilruntime.HandleError(fmt.Errorf("%s: Failed to watch %v: %v", r.name, r.expectedType, err))
}
// 类似于网络拒绝连接的错误要等一会儿再试,因为可能网络繁忙
if urlError, ok := err.(*url.Error); ok {
if opError, ok := urlError.Err.(*net.OpError); ok {
if errno, ok := opError.Err.(syscall.Errno); ok && errno == syscall.ECONNREFUSED {
time.Sleep(time.Second)
continue
}
}
}
return nil
}
// watch返回是流,apiserver会将变化的资源通过这个流发送出来,client-go最终通过chan实现的
// 所以watchHandler()是一个需要持续从chan读取数据的流程,所以需要传入resyncerrc和stopCh
// 用于异步通知退出或者后台同步协程错误
if err := r.watchHandler(w, &resourceVersion, resyncerrc, stopCh); err != nil {
if err != errorStopRequested {
glog.Warningf("%s: watch of %v ended with: %v", r.name, r.expectedType, err)
}
return nil
}
}
}上面的函数中,调用了两个私有函数,分别为syncWith()和watchHandler()。syncWith()用于实现一次从apiserver全量对象的同步,这里的同步和我们上面提到的同步不是一回事,这里指的是从apiserver的同步。watchHandler是实现监控apiserver资源变化的处理过程,主要就是把apiserver的资源变化转换为DeltaFIFO调用。我们接下来就看这两个函数的具体实现
接下来我们就要看看watchHandler做了什么?
// 代码源自client-go/tools/cache/reflector.go
// 实现apiserver全量对象的同步
func (r *Reflector) syncWith(items []runtime.Object, resourceVersion string) error {
// 做一次slice类型转换
found := make([]interface{}, 0, len(items))
for _, item := range items {
found = append(found, item)
}
// 直接调用了DeltaFIFO的Replace()接口,这个接口就是用于同步全量对象的
return r.store.Replace(found, resourceVersion)
}
// 实现从watch返回的chan中持续读取变化的资源,并转换为DeltaFIFO相应的调用
func (r *Reflector) watchHandler(w watch.Interface, resourceVersion *string, errc chan error, stopCh <-chan struct{}) error {
start := r.clock.Now()
eventCount := 0
// 监控相关
defer func() {
r.metrics.numberOfItemsInWatch.Observe(float64(eventCount))
r.metrics.watchDuration.Observe(time.Since(start).Seconds())
}()
// 这里就开始无限循环的从chan中读取资源的变化,也可以理解为资源的增量变化,同时还要监控各种信号
loop:
for {
select {
// 系统退出信号
case <-stopCh:
return errorStopRequested
// 后台同步协程出错信号
case err := <-errc:
return err
// watch函数返回的是一个chan,通过这个chan持续的读取对象
case event, ok := <-w.ResultChan():
// 如果不OK,说明chan关闭了,就要重新获取,这里面我们可以推测这个chan可能会运行过程中重新创建
// 否则就应该退出而不是继续循环
if !ok {
break loop
}
// 看来event可以作为错误的返回值,挺有意思,而不是通过关闭chan,这种方式可以传递错误信息,关闭chan做不到
if event.Type == watch.Error {
return apierrs.FromObject(event.Object)
}
// 这里面就是利用反射实例化对象了,而且判断了对象类型是我们设定的类型
if e, a := r.expectedType, reflect.TypeOf(event.Object); e != nil && e != a {
utilruntime.HandleError(fmt.Errorf("%s: expected type %v, but watch event object had type %v", r.name, e, a))
continue
}
// 和list操作相似,也要获取对象的版本,要更新缓存中的版本,下次watch就可以忽略这些资源了
meta, err := meta.Accessor(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to understand watch event %#v", r.name, event))
continue
}
newResourceVersion := meta.GetResourceVersion()
// 根据事件的类型做不同的DeltaFIFO的操作
switch event.Type {
// 向DeltaFIFO添加一个添加的Delta
case watch.Added:
err := r.store.Add(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to add watch event object (%#v) to store: %v", r.name, event.Object, err))
}
// 更新对象,向DeltaFIFO添加一个更新的Delta
case watch.Modified:
err := r.store.Update(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to update watch event object (%#v) to store: %v", r.name, event.Object, err))
}
// 删除对象,向DeltaFIFO添加一个删除的Delta
case watch.Deleted:
err := r.store.Delete(event.Object)
if err != nil {
utilruntime.HandleError(fmt.Errorf("%s: unable to delete watch event object (%#v) from store: %v", r.name, event.Object, err))
}
// 其他类型就不知道干什么了,只能报错
default:
utilruntime.HandleError(fmt.Errorf("%s: unable to understand watch event %#v", r.name, event))
}
// 更新最新资源版本
*resourceVersion = newResourceVersion
r.setLastSyncResourceVersion(newResourceVersion)
eventCount++
}
}
// watch返回时间非常短而且没有任何事件要处理,这个属于异常现象,因为我们watch是设置了超时的
watchDuration := r.clock.Now().Sub(start)
if watchDuration < 1*time.Second && eventCount == 0 {
r.metrics.numberOfShortWatches.Inc()
return fmt.Errorf("very short watch: %s: Unexpected watch close - watch lasted less than a second and no items received", r.name)
}
return nil
}至此,Reflector的核心功能就算分析完了,我们再把其他的周边函数简单的过一下:
// 代码源自client-go/tools/cache/reflector.go
func (r *Reflector) setLastSyncResourceVersion(v string) {
// 设置已经获取到资源的最新版本
r.lastSyncResourceVersionMutex.Lock()
defer r.lastSyncResourceVersionMutex.Unlock()
r.lastSyncResourceVersion = v
rv, err := strconv.Atoi(v)
if err == nil {
r.metrics.lastResourceVersion.Set(float64(rv))
}
}
// 获取resync定时器,叫定时器比较好理解,叫chan很难和定时关联起来
func (r *Reflector) resyncChan() (<-chan time.Time, func() bool) {
// 如果resyncPeriod说明就不用定时同步,返回的是永久超时的定时器
if r.resyncPeriod == 0 {
return neverExitWatch, func() bool { return false }
}
// 构建定时起
t := r.clock.NewTimer(r.resyncPeriod)
return t.C(), t.Stop
}再次,我对Reflector做一下总结,其中内容和上面的推导很相似:
- Reflector利用apiserver的client列举全量对象(版本为0以后的对象全部列举出来)
- 将全量对象采用Replace()接口同步到DeltaFIFO中,并且更新资源的版本号,这个版本号后续会用到;
- 开启一个协程定时执行resync,如果没有设置定时同步则不会执行,同步就是把全量对象以同步事件的方式通知出去;
- 通过apiserver的client监控(watch)资源,监控的当前资源版本号以后的对象,因为之前的都已经获取到了;
- 一旦有对象发生变化,那么就会根据变化的类型(新增、更新、删除)调用DeltaFIFO的相应接口,产生一个相应的对象Delta,同时更新当前资源的版本;
Controller实现
此controller非我们比较熟悉的controller-manager管理的各种各样的controller,kubernetes里面controller简直是泛滥啊。这里的controller定义在client-go/tools/cache/controller.go中,目的是用来把Reflector、DeltaFIFO组合起来形成一个相对固定的、标准的处理流程。理解了Controller,基本就算把SharedInfomer差不多搞懂了。话不多说,先上代码:
// 代码源自client-go/tools/cache/controller.go
// 这是一个Controller的抽象
type Controller interface {
Run(stopCh <-chan struct{}) // 核心流程函数
HasSynced() bool // apiserver中的对象是否已经同步到了Store中
LastSyncResourceVersion() string // 最新的资源版本号
}从上面的定义来看,HasSynced()可调用DeltaFIFO. HasSynced()实现,LastSyncResourceVersion()可以通过Reflector实现。因为Controller把多个模块整合起来实现了一套业务逻辑,所以在创建Controller需要提供一些配置:
// 代码源自client-go/tools/cache/controller.go
type Config struct {
Queue // SharedInformer使用DeltaFIFO
ListerWatcher // 这个用来构造Reflector
Process ProcessFunc // 这个在调用DeltaFIFO.Pop()使用,弹出对象要如何处理
ObjectType runtime.Object // 对象类型,这个肯定是Reflector使用
FullResyncPeriod time.Duration // 全量同步周期,这个在Reflector使用
ShouldResync ShouldResyncFunc // Reflector在全量更新的时候会调用该函数询问
RetryOnError bool // 错误是否需要尝试
}从上面两个类型的定义我们可以猜测:Controller自己构造Reflector获取对象,Reflector作为DeltaFIFO生产者持续监控apiserver的资源变化并推送到队列中。Controller的Run()应该是队列的消费者,从队列中弹出对象并调用Process()处理。所以Controller相比于Reflector因为队列的加持表现为每次有资源变化就会调用一次使用者定义的处理函数。
我们顺着上面的推测看看代码的具体实现:
// 代码源自client-go/tools/cache/controller.go
// controller是Controller的实现类型
type controller struct {
config Config // 配置,上面有讲解
reflector *Reflector // 反射器
reflectorMutex sync.RWMutex // 反射器的锁
clock clock.Clock // 时钟
}
// 核心业务逻辑实现
func (c *controller) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
// 创建一个协程,如果收到系统退出的信号就关闭队列,相当于在这里析构的队列
go func() {
<-stopCh
c.config.Queue.Close()
}()
// 创建Reflector,传入的参数都是我们上一个章节解释过的,这里不赘述
r := NewReflector(
c.config.ListerWatcher,
c.config.ObjectType,
c.config.Queue,
c.config.FullResyncPeriod,
)
// r.ShouldResync的存在就是为了以后使用少些一点代码?否则直接使用c.config.ShouldResync不就完了么?不明白用意
r.ShouldResync = c.config.ShouldResync
r.clock = c.clock
// 记录反射器
c.reflectorMutex.Lock()
c.reflector = r
c.reflectorMutex.Unlock()
// wait.Group不是本章的讲解内容,只要把它理解为类似barrier就行了
// 被他管理的所有的协程都退出后调用Wait()才会退出,否则就会被阻塞
var wg wait.Group
defer wg.Wait()
// StartWithChannel()会启动协程执行Reflector.Run(),同时接收到stopCh信号就会退出协程
wg.StartWithChannel(stopCh, r.Run)
// wait.Until()在前面的章节讲过了,周期性的调用c.processLoop(),这里来看是1秒
// 不用担心调用频率太高,正常情况下c.processLoop是不会返回的,除非遇到了解决不了的错误,因为他是个循环
wait.Until(c.processLoop, time.Second, stopCh)
}从上面代码上看,私有函数processLoop()才是核心逻辑的实现:
// 代码源自client-go/tools/cache/controller.go
func (c *controller) processLoop() {
for {
// 从队列中弹出一个对象,然后处理它,这才是最主要的部分,这个c.config.Process是构造Controller的时候通过Config传进来的
// 所以这个读者要特别注意了,这个函数其实是ShareInformer传进来的,所以在分析SharedInformer的时候要重点分析的
obj, err := c.config.Queue.Pop(PopProcessFunc(c.config.Process))
if err != nil {
// 如果FIFO关闭了那就退出
if err == FIFOClosedError {
return
}
// 如果错误可以再试试
if c.config.RetryOnError {
c.config.Queue.AddIfNotPresent(obj)
}
}
}
}上面的代码是不是很简单?这就对了,因为核心处理逻辑实现在了Process函数中了。这时候是不是很想看看这个Process()函数到底干了什么?后面SharedInformer的实现章节会有详细介绍,我们还得把周边函数过一遍:
// 代码源自client-go/tools/cache/controller.go
// HasSynced() 调用的就是DeltaFIFO.HasSynced()实现的
func (c *controller) HasSynced() bool {
return c.config.Queue.HasSynced()
}
// LastSyncResourceVersion() 是利用Reflector实现的
func (c *controller) LastSyncResourceVersion() string {
if c.reflector == nil {
return ""
}
return c.reflector.LastSyncResourceVersion()
}SharedInformer分析
SharedInformer的定义
本文之所以长是因为需要前期介绍很多内容,现在才刚刚开始本文的正题,我们来看看源码是怎么定义SharedInformer:
// 代码源自client-go/tools/cache/shared_informer.go
type SharedInformer interface {
// 添加资源事件处理器,关于ResourceEventHandler的定义在下面
// 相当于注册回调函数,当有资源变化就会通过回调通知使用者,是不是能和上面介绍的Controller可以联系上了?
// 为什么是Add不是Reg,说明可以支持多个handler
AddEventHandler(handler ResourceEventHandler)
// 上面添加的是不需要周期同步的处理器,下面的接口添加的是需要周期同步的处理器,周期同步上面提了好多遍了,不赘述
AddEventHandlerWithResyncPeriod(handler ResourceEventHandler, resyncPeriod time.Duration)
// Store这个有专门的文章介绍,这个函数就是获取Store的接口,说明SharedInformer内有Store对象
GetStore() Store
// Controller在上面的章节介绍了,说明SharedInformer内有Controller对象
GetController() Controller
// 这个应该是SharedInformer的核心逻辑实现的地方
Run(stopCh <-chan struct{})
// 因为有Store,这个函数就是告知使用者Store里面是否已经同步了apiserver的资源,这个接口很有用
// 当创建完SharedInformer后,通过Reflector从apiserver同步全量对象,然后在通过DeltaFIFO一个一个的同志到cache
// 这个接口就是告知使用者,全量的对象是不是已经同步到了cache,这样就可以从cache列举或者查询了
HasSynced() bool
// 最新同步资源的版本,这个就不多说了,通过Controller(Controller通过Reflector)实现
LastSyncResourceVersion() string
}
// 扩展了SharedInformer类型,从类型名字上看共享的是Indexer,Indexer也是一种Store的实现
type SharedIndexInformer interface {
// 继承了SharedInformer
SharedInformer
// 扩展了Indexer相关的接口
AddIndexers(indexers Indexers) error
GetIndexer() Indexer
}
// 代码源自client-go/tools/cache/controller.go,SharedInformer使用者如果需要处理资源的事件
// 那么就要自己实现相应的回调函数
type ResourceEventHandler interface {
// 添加对象回调函数
OnAdd(obj interface{})
// 更新对象回调函数
OnUpdate(oldObj, newObj interface{})
// 删除对象回调函数
OnDelete(obj interface{})
}相信对Reflector、Controller、Indexer有深入了解的人基本已经把ShareInformer的实现基本猜个差不多了,那么我们来看看SharedInformer的实现类是如何定义的:
// 代码源自client-go/tools/cache/shared_informer.go
type sharedIndexInformer struct {
// Indexer也是一种Store,这个我们知道的,Controller负责把Reflector和FIFO逻辑串联起来
// 所以这两个变量就涵盖了开篇那张图里面的Reflector、DeltaFIFO和LocalStore(cache)
indexer Indexer
controller Controller
// sharedIndexInformer把上面提到的ResourceEventHandler进行了在层封装,并统一由sharedProcessor管理,后面章节专门介绍
processor *sharedProcessor
// CacheMutationDetector其实没啥用,我理解是开发者自己实现的一个调试工具,用来发现对象突变的
// 实现方法也比较简单,DeltaFIFO弹出的对象在处理前先备份(深度拷贝)一份,然后定期比对两个对象是否相同
// 如果不同那就报警,说明处理过程中有人修改过对象,这个功能默认是关闭,所以我说没啥用
cacheMutationDetector CacheMutationDetector
// 这两个变量是给Reflector用的,我们知道Reflector是在Controller创建的
listerWatcher ListerWatcher
objectType runtime.Object
// 定期同步的周期,因为可能存在多个ResourceEventHandler,就有可能存在多个同步周期,sharedIndexInformer采用最小的周期
// 这个周期值就存储在resyncCheckPeriod中,通过AddEventHandler()添加的处理器都采用defaultEventHandlerResyncPeriod
resyncCheckPeriod time.Duration
defaultEventHandlerResyncPeriod time.Duration
// 时钟
clock clock.Clock
// 启动、停止标记,肯定有人会问为啥用两个变量,一个变量不就可以实现启动和停止了么?
// 其实此处是三个状态,启动前,已启动和已停止,start表示了两个状态,而且为启动标记专门做了个锁
// 说明启动前和启动后有互斥的资源操作
started, stopped bool
startedLock sync.Mutex
// 这个名字起的也是够了,因为DeltaFIFO每次Pop()的时候需要传入一个函数用来处理Deltas
// 处理Deltas也就意味着要把消息通知给处理器,如果此时调用了AddEventHandler()
// 就会存在崩溃的问题,所以要有这个锁,阻塞Deltas....细想名字也没毛病~
blockDeltas sync.Mutex
}上面代码注释中简单介绍了sharedProcessor和CacheMutationDetector,我们下面就要对他们两个类型做详细解析。
CacheMutationDetector
CacheMutationDetector这个就是检测对象在过程中突变的,何所谓突变呢?突变就是莫名其妙的修改了,如何实现突变检测,也是比较简单的。CacheMutationDetector对所有的对象做了一次深度拷贝(DeepCopy),然后定期比较两个对象是否一致,当发现有不同时说明对象突变了,然后就panic。我认为CacheMutationDetector是用来调试的,因为代码默认是关闭的:
// 代码源自client-go/tools/cache/mutation_detector.go
// 默认关闭突变检测
var mutationDetectionEnabled = false
// 但是可以通过环境变量的KUBE_CACHE_MUTATION_DETECTOR开启
func init() {
mutationDetectionEnabled, _ = strconv.ParseBool(os.Getenv("KUBE_CACHE_MUTATION_DETECTOR"))
}
// 这个是突变检测的类型抽象
type CacheMutationDetector interface {
AddObject(obj interface{}) // 用于记录所有的对象
Run(stopCh <-chan struct{}) // 开启协程定期比对
}
// 创建CacheMutationDetector对象
func NewCacheMutationDetector(name string) CacheMutationDetector {
// 如果没有开启选项就构造一个什么都不做的对象
if !mutationDetectionEnabled {
return dummyMutationDetector{}
}
// 如果开启了选项,那么就构造一个默认的突变检测器
glog.Warningln("Mutation detector is enabled, this will result in memory leakage.")
return &defaultCacheMutationDetector{name: name, period: 1 * time.Second}
}
// 这就是什么都不做的突变检测器
type dummyMutationDetector struct{}
func (dummyMutationDetector) Run(stopCh <-chan struct{}) {
}
func (dummyMutationDetector) AddObject(obj interface{}) {
}默认的突变检测器读者自行分析把,因为比较简单并且默认还不开启,我就省点笔墨了~
sharedProcessor分析
有没有感觉shared这个词被kubernetes玩儿坏了(继controller之后有一个背玩儿坏的单词),sharedProcessor这又shared啥了?首先需要知道Processor的定义,这里定义的Processor就是处理事件的东西。什么事件,就是SharedInformer向外部通知的事件。因为官方代码没有注释,我猜是shared是同一个SharedInformer,有没有很绕嘴?还有更绕的在后面呢,我们还要了解一个新的类型,那就是processorListener,processor刚说完,又来了个Listener!
通过SharedInformer.AddEventHandler()添加的处理器最终就会封装成processorListener,然后通过sharedProcessor管理起来,通过processorListener的封装就可以达到所谓的有事处理,没事挂起。
processorListener分析
processorListener可以理解为两个核心功能,一个是processor,一个是listener,用一句话概括,有事做事没事挂起。先看看processorListener的定义:
// 代码源自clien-go/tools/cache/shared_informer.go
type processorListener struct {
// nextCh、addCh、handler、pendingNotifications的用法请参看我的《golang的chan有趣用法》里面有相关的例子
// 总结这四个变量实现了事件的输入、缓冲、处理,事件就是apiserver资源的变化
nextCh chan interface{}
addCh chan interface{}
handler ResourceEventHandler
pendingNotifications buffer.RingGrowing
// 下面四个变量就是跟定时同步相关的了,requestedResyncPeriod是处理器设定的定时同步周期
// resyncPeriod是跟sharedIndexInformer对齐的同步时间,因为sharedIndexInformer管理了多个处理器
// 最终所有的处理器都会对齐到一个周期上,nextResync就是下一次同步的时间点
requestedResyncPeriod time.Duration
resyncPeriod time.Duration
nextResync time.Time
resyncLock sync.Mutex
}我们需要知道就是processor如何接收事件(此处事件就是apiserver的资源变化,也就是DeltaFIFO输出的Deltas)?如何通知事件处理器?如何缓冲处理器?如何阻塞处理器进而形成listener的?一系列的问题我们需要沿着处理逻辑的流程逐一解释。第一个问题,事件是如何传入的:
// 代码源自client-go/tools/cache/shared_informer.go
// 对,就这么简单,通过addCh传入,这里面的notification就是我们所谓的事件
func (p *processorListener) add(notification interface{}) {
p.addCh <- notification
}因为addCh是无缓冲chan,调用add()函数的人是事件分发器。意思就是从DeltaFIFO弹出的Deltas要要逐一送到多个处理器,此时如果处理器没有及时处理会造成addCh把分发器阻塞,那别的处理器也就同样无法收到新的事件了。这一点,processorListener利用一个后台协程处理这个问题(相应的原理参看《golang的chan有趣用法》):
// 代码源自client-go/tools/cache/shared_informer.go
// 这个函数是通过sharedProcessor利用wait.Group启动的,读者可以自行查看wait.Group
func (p *processorListener) pop() {
defer utilruntime.HandleCrash()
// nextCh是在这里,函数退出前析构的
defer close(p.nextCh)
// 临时变量,下面会用到
var nextCh chan<- interface{}
var notification interface{}
// 进入死循环啦
for {
select {
// 有两种情况,nextCh还没有初始化,这个语句就会被阻塞,这个我在《深入浅出golang之chan》说过
// nextChan后面会赋值为p.nextCh,因为p.nextCh也是无缓冲的chan,数据不发送成功就阻塞
case nextCh <- notification:
// 如果发送成功了,那就从缓冲中再取一个事件出来
var ok bool
notification, ok = p.pendingNotifications.ReadOne()
if !ok {
// 如果没有事件,那就把nextCh再次设置为nil,接下来对于nextCh操作还会被阻塞
nextCh = nil
}
// 从p.addCh读取一个事件出来,这回看到消费p.addCh的地方了
case notificationToAdd, ok := <-p.addCh:
// 说明p.addCh关闭了,只能退出
if !ok {
return
}
// notification为空说明当前还没发送任何事件给处理器
if notification == nil {
// 那就把刚刚获取的事件通过p.nextCh发送个处理器
notification = notificationToAdd
nextCh = p.nextCh
} else {
// 上一个事件还没有发送成功,那就先放到缓存中
// pendingNotifications可以想象为一个slice,这样方便理解,是一个动态的缓存,
p.pendingNotifications.WriteOne(notificationToAdd)
}
}
}
}pop()函数实现的非常巧妙,利用一个协程就把接收、缓冲、发送全部解决了。它充分的利用了golang的select可以同时操作多个chan的特性,同时从addChd读取数据从nextCh发送数据,这两个chan任何一个完成都可以激活协程。对于C/C++程序猿理解起来有点费劲,但这就是GO的魅力所在。接下来,我们看看从nextCh读取事件后是如何处理的:
// 代码源自client-go/tools/cache/shared_informer.go
// 这个也是sharedProcessor通过wait.Group启动的
func (p *processorListener) run() {
// 因为wait.Until需要传入退出信号的chan
stopCh := make(chan struct{})
// wait.Until不多说了,我在前期不点的文章中说过了,只要没有收到退出信号就会周期的执行传入的函数
wait.Until(func() {
// wait.ExponentialBackoff()和wait.Until()类似,wait.Until()是无限循环
// wait.ExponentialBackoff()是尝试几次,每次等待时间会以指数上涨
err := wait.ExponentialBackoff(retry.DefaultRetry, func() (bool, error) {
// 这也是chan的range用法,可以参看我的《深入浅出golang的chan》了解细节
for next := range p.nextCh {
// 判断事件类型,这里面的handler就是调用SharedInfomer.AddEventHandler()传入的
// 理论上处理的不是Deltas么?怎么变成了其他类型,这是SharedInformer做的二次封装,后面会看到
switch notification := next.(type) {
case updateNotification:
p.handler.OnUpdate(notification.oldObj, notification.newObj)
case addNotification:
p.handler.OnAdd(notification.newObj)
case deleteNotification:
p.handler.OnDelete(notification.oldObj)
default:
utilruntime.HandleError(fmt.Errorf("unrecognized notification: %#v", next))
}
}
return true, nil
})
// 执行到这里只能是nextCh已经被关闭了,所以关闭stopCh,通知wait.Until()退出
if err == nil {
close(stopCh)
}
}, 1*time.Minute, stopCh)
}因为processorListener其他函数没啥大用,上面两个函数就就已经把核心功能都实现了。processorListener就是实现了事件的缓冲和处理,此处的处理就是使用者传入的函数。在没有事件的时候可以阻塞处理器,当事件较多是可以把事件缓冲起来,实现了事件分发器与处理器的异步处理。
processorListener的run()和pop()函数是sharedProcessor启动的协程调用的,所以下面就要对sharedProcessor进行分析了。
sharedProcessor管理processorListener
sharedProcessor的定义如下:
// client-go/tools/cache/shared_informer.go
// sharedProcessor是通过数组组织处理器的,只是分了需要定时同步和不需要要同步两类
type sharedProcessor struct {
listenersStarted bool // 所有处理器是否已经启动的标识
listenersLock sync.RWMutex // 读写锁
listeners []*processorListener // 通用的处理器
syncingListeners []*processorListener // 需要定时同步的处理器
clock clock.Clock // 时钟
wg wait.Group // 前面讲过了processorListener每个需要两个协程,
// 用wait.Group来管理所有处理器的携程,保证他们都能退出
}在sharedProcessor里面用的都是listener(监听器),我更倾向于叫处理器,因为我更看重他是处理事件的,所以后面见到listener我叫处理器的时候不要奇怪。我们来看看添加一个处理器是如何实现的:
// 代码源自client-go/tools/cache/shared_informer.go
// 添加处理器,sharedIndexInformer.AddEventHandler()就会调用这个函数实现处理器的添加
func (p *sharedProcessor) addListener(listener *processorListener) {
// 加锁,这个很好理解
p.listenersLock.Lock()
defer p.listenersLock.Unlock()
// 把处理器添加到数组中
p.addListenerLocked(listener)
// 通过wait.Group启动两个协程,做的事情我们在processorListener说过了,这里就是我们上面提到的启动两个协程的地方
// 这个地方判断了listenersStarted,这说明sharedProcessor在启动前、后都可以添加处理器
if p.listenersStarted {
p.wg.Start(listener.run)
p.wg.Start(listener.pop)
}
}
// 把处理器添加到数组中
func (p *sharedProcessor) addListenerLocked(listener *processorListener) {
// 两类(定时同步和不同步)的处理器数组都添加了,这是因为没有定时同步的也会用默认的时间,后面我们会看到
// 那么问题来了,那还用两个数组干什么呢?
p.listeners = append(p.listeners, listener)
p.syncingListeners = append(p.syncingListeners, listener)
}在SharedInformer的接口中有一个与之对应的接口,就是SharedInformer.AddEventHandler()。因为SharedInformer没有删除处理器的借口,sharedProcessor也没有相应借口。接下来就是sharedProcessor的分发事件的接口:
// 代码源自client-go/tools/cache/shared_informer.go
// 通过函数名称也能感觉到分发的感觉~sync表示obj对象是否为同步事件对象
func (p *sharedProcessor) distribute(obj interface{}, sync bool) {
// 加锁没毛病
p.listenersLock.RLock()
defer p.listenersLock.RUnlock()
// 无论是否为sync,添加处理器的代码中我们知道两个数组都会被添加,所以判断不判断没啥区别~
// 所以我的猜测是代码以前实现的是明显区分两类的,但随着代码的更新二者的界限已经没那么明显了
if sync {
for _, listener := range p.syncingListeners {
listener.add(obj)
}
} else {
for _, listener := range p.listeners {
listener.add(obj)
}
}
}sharedProcessor运行起来后,唯一需要做的就是等待退出信号然后关闭所有的处理器,来看看具体实现代码:
// 代码源自client-go/tools/cache/shared_informer.go
func (p *sharedProcessor) run(stopCh <-chan struct{}) {
// 启动前、后对于添加处理器的逻辑是不同,启动前的处理器是不会立刻启动连个协程执行处理器的pop()和run()函数的
// 而是在这里统一的启动
func() {
p.listenersLock.RLock()
defer p.listenersLock.RUnlock()
// 遍历所有的处理器,然后为处理器启动两个后台协程
for _, listener := range p.listeners {
p.wg.Start(listener.run)
p.wg.Start(listener.pop)
}
p.listenersStarted = true
}()
// 等待退出信号
<-stopCh
p.listenersLock.RLock()
defer p.listenersLock.RUnlock()
// 关闭addCh,processorListener.pop()这个协程就会退出,不明白的可以再次回顾代码
// 因为processorListener.pop()会关闭processorListener.nextCh,processorListener.run()就会退出
// 所以这里只要关闭processorListener.addCh就可以自动实现两个协程的退出,不得不说设计的还是挺巧妙的
for _, listener := range p.listeners {
close(listener.addCh)
}
// 等待所有的协程退出,这里指的所有协程就是所有处理器的那两个协程
p.wg.Wait()
}SharedInformer实现
既然已经定性为长篇大论了,那就从创建SharedInformer对象开始一撸到底。client-go实现了两个创建SharedInformer的接口,如下所示:
// 代码源自client-go/tools/cache/shared_informer.go
// lw:这个是apiserver客户端相关的,用于Reflector从apiserver获取资源,所以需要外部提供
// objType:这个SharedInformer监控的对象类型
// resyncPeriod:同步周期,SharedInformer需要多长时间给使用者发送一次全量对象的同步时间
func NewSharedInformer(lw ListerWatcher, objType runtime.Object, resyncPeriod time.Duration) SharedInformer {
// 还是用SharedIndexInformer实现的
return NewSharedIndexInformer(lw, objType, resyncPeriod, Indexers{})
}
// 创建SharedIndexInformer对象,其中大部分参数再上面的函数已经介绍了
// indexers:需要外部提供计算对象索引键的函数,也就是这里面的对象需要通过什么方式创建索引
func NewSharedIndexInformer(lw ListerWatcher, objType runtime.Object, defaultEventHandlerResyncPeriod time.Duration, indexers Indexers) SharedIndexInformer {
realClock := &clock.RealClock{}
sharedIndexInformer := &sharedIndexInformer{
// 管理所有处理器用的,这个上面的章节解释了
processor: &sharedProcessor{clock: realClock},
// 其实就是在构造cache,读者可以自行查看NewIndexer()的实现,
// 在cache中的对象用DeletionHandlingMetaNamespaceKeyFunc计算对象键,用indexers计算索引键
// 可以想象成每个对象键是Namespace/Name,每个索引键是Namespace,即按照Namesapce分类
// 因为objType决定了只有一种类型对象,所以Namesapce是最大的分类
indexer: NewIndexer(DeletionHandlingMetaNamespaceKeyFunc, indexers),
// 下面这两主要就是给Controller用,确切的说是给Reflector用的
listerWatcher: lw,
objectType: objType,
// 无论是否需要定时同步,SharedInformer都提供了一个默认的同步时间,当然这个是外部设置的
resyncCheckPeriod: defaultEventHandlerResyncPeriod,
defaultEventHandlerResyncPeriod: defaultEventHandlerResyncPeriod,
// 默认没有开启的对象突变检测器,没啥用,也不多介绍
cacheMutationDetector: NewCacheMutationDetector(fmt.Sprintf("%T", objType)),
clock: realClock,
}
return sharedIndexInformer
}创建完ShareInformer对象,就要添加事件处理器了:
// 代码源自client-go/tools/cache/shared_informer.go
// 添加没有指定同步周期的事件处理器
func (s *sharedIndexInformer) AddEventHandler(handler ResourceEventHandler) {
// defaultEventHandlerResyncPeriod是默认的同步周期,在创建SharedInformer的时候设置的
s.AddEventHandlerWithResyncPeriod(handler, s.defaultEventHandlerResyncPeriod)
}
// 添加需要定期同步的事件处理器
func (s *sharedIndexInformer) AddEventHandlerWithResyncPeriod(handler ResourceEventHandler, resyncPeriod time.Duration) {
// 因为是否已经开始对于添加事件处理器的方式不同,后面会有介绍,所以此处加了锁
s.startedLock.Lock()
defer s.startedLock.Unlock()
// 如果已经结束了,那就可以直接返回了
if s.stopped {
return
}
// 如果有同步周期,==0就是永远不用同步
if resyncPeriod > 0 {
// 同步周期不能太短,太短对于系统来说反而是个负担,大量的无效计算浪费在这上面
if resyncPeriod < minimumResyncPeriod {
resyncPeriod = minimumResyncPeriod
}
// SharedInformer管理了很多处理器,每个处理器都有自己的同步周期,所以此处要统一成一个,称之为对齐
// SharedInformer会选择所有处理器中最小的那个作为所有处理器的同步周期,称为对齐后的同步周期
// 此处就要判断是不是比当前对齐后的同步周期还要小
if resyncPeriod < s.resyncCheckPeriod {
// 如果已经启动了,那么只能用和大家一样的周期
if s.started {
resyncPeriod = s.resyncCheckPeriod
// 如果没启动,那就让大家都用最新的对齐同步周期
} else {
s.resyncCheckPeriod = resyncPeriod
s.processor.resyncCheckPeriodChanged(resyncPeriod)
}
}
}
// 创建处理器,代码一直用listener,可能想强调没事件就挂起把,我反而想用处理器这个名词
// determineResyncPeriod()这个函数读者自己分析把,非常简单,这里面只要知道创建了处理器就行了
listener := newProcessListener(handler, resyncPeriod, determineResyncPeriod(resyncPeriod, s.resyncCheckPeriod), s.clock.Now(), initialBufferSize)
// 如果没有启动,那么直接添加处理器就可以了
if !s.started {
s.processor.addListener(listener)
return
}
// 这个锁就是暂停再想所有的处理器分发事件用的,因为这样会遍历所有的处理器,此时添加会有风险
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
// 添加处理器
s.processor.addListener(listener)
// 这里有意思啦,遍历缓冲中的所有对象,通知处理器,因为SharedInformer已经启动了,可能很多对象已经让其他的处理器处理过了,
// 所以这些对象就不会再通知新添加的处理器,此处就是解决这个问题的
for _, item := range s.indexer.List() {
listener.add(addNotification{newObj: item})
}
}事件处理器添加完了,就要看SharedInformer如何把事件分发给每个处理器的了:
// 代码源自client-go/tools/cache/shared_informer.go
// sharedIndexInformer的核心逻辑函数
func (s *sharedIndexInformer) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
// 在此处构造的DeltaFIFO
fifo := NewDeltaFIFO(MetaNamespaceKeyFunc, s.indexer)
// 这里的Config是我们介绍Reflector时介绍的那个Config
cfg := &Config{
// 我前面一直在说Reflector输入到DeltaFIFO,这里算是直接证明了
Queue: fifo,
// 下面这些变量我们在Reflector都说了,这里赘述
ListerWatcher: s.listerWatcher,
ObjectType: s.objectType,
FullResyncPeriod: s.resyncCheckPeriod,
RetryOnError: false,
ShouldResync: s.processor.shouldResync,
// 这个才是重点,Controller调用DeltaFIFO.Pop()接口传入的就是这个回调函数,也是我们后续重点介绍的
Process: s.HandleDeltas,
}
// 创建Controller,这个不用多说了
func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.controller = New(cfg)
s.controller.(*controller).clock = s.clock
s.started = true
}()
// 这个processorStopCh 是给sharedProcessor和cacheMutationDetector传递退出信号的
// 因为这里要创建两个协程运行sharedProcessor和cacheMutationDetector的核心函数
processorStopCh := make(chan struct{})
var wg wait.Group
defer wg.Wait() // Wait for Processor to stop
defer close(processorStopCh) // Tell Processor to stop
wg.StartWithChannel(processorStopCh, s.cacheMutationDetector.Run)
wg.StartWithChannel(processorStopCh, s.processor.run)
// Run()函数都退出了,也就应该设置结束的标识了
defer func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.stopped = true
}()
// 启动Controller,Controller一旦运行,整个流程就开始启动了,所以叫Controller也不为过
// 毕竟Controller是SharedInformer的发动机嘛
s.controller.Run(stopCh)
}sharedIndexInformer通过Run()函数启动了Controller和sharedProcess(),Controller通过DeltaFIFO.Pop()函数弹出Deltas,并调用函数处理,这个处理函数就是sharedIndexInformer.HandleDeltas(),这个函数是衔接Controller和sharedProcess的关键点,他把Deltas转换为sharedProcess需要的各种Notification类型。下面我们就对这个函数进行代码分析:
// 代码源自client-go/tools/cache/shared_informer.go
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {
// 看到这里就知道为啥起名为blockDeltas了,这是阻塞处理器Deltas啊~因为分发事件到处理器,所以要加锁
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
// Deltas里面包含了一个对象的多个增量操作,所以要从最老的Delta到最先的Delta遍历处理
for _, d := range obj.(Deltas) {
// 根据不同的Delta做不同的操作,但是大致分为对象添加、删除两大类操作
// 所有的操作都要先同步到cache在通知处理器,这样保持处理器和cache的状态是一致的
switch d.Type {
// 同步、添加、更新都是对象添加类的造作,至于是否是更新还要看cache是否有这个对象
case Sync, Added, Updated:
// 看看对象是不是有定时同步产生的事件
isSync := d.Type == Sync
// 检测突变,没啥用
s.cacheMutationDetector.AddObject(d.Object)
// 如果cache中有的对象,一律看做是更新事件
if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {
// 把对象更新到cache中
if err := s.indexer.Update(d.Object); err != nil {
return err
}
// 通知处理器处理事件
s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)
// cache中没有的对象,一律看做是新增事件
} else {
// 把对象添加到cache中
if err := s.indexer.Add(d.Object); err != nil {
return err
}
// 通知处理器处理器事件
s.processor.distribute(addNotification{newObj: d.Object}, isSync)
}
// 对象被删除
case Deleted:
// 从cache中删除对象
if err := s.indexer.Delete(d.Object); err != nil {
return err
}
// 通知所有的处理器对象被删除了
s.processor.distribute(deleteNotification{oldObj: d.Object}, false)
}
}
return nil
}至此,我们算是把SharedInformer的核心功能全部撸了一遍,以前对他感觉非常复杂,先来来看并不复杂,甚至非常简单。
总结
我们对SharedInformer做一下总结:
-
利用apiserver的api实现资源的列举和监控(Reflector实现);
-
利用cache存储apiserver中的部分对象,通过对象类型进行制定,并在cache中采用Namespace做对象的索引
-
先通过apiserver的api将对象的全量列举出来存储在cache中,然后再watch资源,一旦有变化就更新cache中;
-
更新到cache中的过程通过DeltaFIFO实现的有顺序的更新,因为资源状态是通过全量+增量方式实现同步的,所以顺序错误会造成状态不一致;
-
使用者可以注册回调函数(类似挂钩子),在更新到cache的同时通知使用者处理,为了保证回调处理不被某一个处理器阻塞,SharedInformer实现了processorListener异步缓冲处理;
- 真个过程是Controller是发动机,驱动整个流程运转;
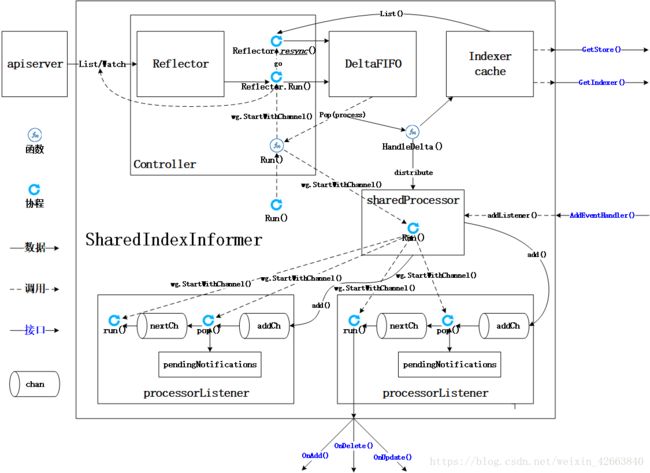
最后我们还是用一幅图来总结SharedInformer,绝对的干货(其中Reflector.resync()因为是个匿名函数,所以用斜体,其实是不存在这个函数的)~