强化学习:CartPole
欢迎加群:1012878218,一起学习、交流强化学习,里面会有关于深度学习、机器学习、强化学习的各种资料 。
强化学习(Reinforcement Learning),是机器学习的一个分支,解决连续策略问题。区别于无监督学习(如聚类,kmeans,自编码器)和有监督学习(分类和回归,CNN,RNN,LSTM),强化学习的目标变化不明确,不存在绝对的正确标签。
强化学习主要包含几个概念:环境状态(Observation),行动(Action)和奖励(Reward),通过智能体(Agent)与环境(Enviroment)不断的交互,不断的试错,从经验中学习,最终确定出最佳策略,即每个状态下最佳的Action,从而获得最大的累计奖励。
强化学习已经应用在了AlphaGo,无人驾驶,游戏等领域,AlphaGo主要使用了快速走子,策略网络,估值网络和蒙特卡洛搜索树等技术。
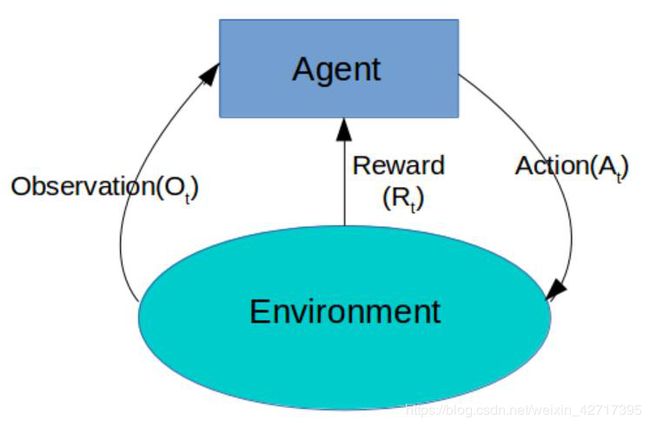
强化学习模型本质上也是神经网络,主要分为策略网络(Policy network,如Policy Gradient)和估值网络(Value Network,如Q-Learnning,Sarsa,Deep Q Network)。第一种直接预测在某个环境状态下应该采取的行动,第二种是预测在某个环境状态下所有行动的期望价值,然后选择Q值最高的策略执行。策略网络的训练方法是策略梯度,好的策略产生更高的期望值,通过对样本的学习,模型会逐渐输出好的策略。
强化学习还有其他的划分方式:
model-free(Q learning, Sarsa, Policy Gradients)和model-based,model-based的可以理解环境。
基于概率(Policy Gradient)和基于价值(Q learning, Sarsa),两者结合(Actor-Critic)。
回合更新(Monte-carlo learning,基础版的policy gradients)和单步更新(Qlearning, Sarsa, 升级版的 policy gradients)。
在线学习(Sarsa,Sarsa lambda)和离线学习(Q learning),两者结合(Deep-Q-Network),离线学习不需要agent亲自参与游戏。

策略网络的一个实例:使用Tensorflow创建一个基于策略网络的Agent(智能体)来解决CartPole(小车倒立摆)问题。算法的大致结构如下所示:

代码+详细注释、分块
# coding:utf-8
import numpy as np
import pickle
import tensorflow as tf
import matplotlib.pylab as plt
import math
import gym
# 初始化环境
env = gym.make('CartPole-v0') # 创建环境
env.reset() # 初始化环境
random_episodes = 0 # 进行10次试验
reward_sum = 0 # 总奖励
while random_episodes < 10:
env.render() # 将CartPole问题的图像渲染出来
observation, reward, done, _ = env.step(np.random.randint(0, 2)) # 执行随机的Action
reward_sum += reward # 累计奖励总和
if done: # done为TRUE说明进行过一次试验
random_episodes += 1
print("Reward for this episode was:", reward_sum)
reward_sum = 0 # 累计奖励清零
env.reset() # 重置环境
# 定义超参数
H = 50 # 隐含的节点数
batch_size = 25 # 批数量
learning_rate = 1e-1 # 学习率
gamma = 0.99 # Reward的Discount比例
D = 4 # 环境信息oberservation的维度
# 定义策略网络的具体结构,输入为oberservation,输出为向左或向右施加力的概率
tf.reset_default_graph() # 初始化
observations = tf.placeholder(tf.float32, [None, D], name="input_x") # 创建observations,维度为D
W1 = tf.get_variable("W1", shape=[D, H], # 初始化隐含层权重W1,维度为[D,H]
initializer=tf.contrib.layers.xavier_initializer())
layer1 = tf.nn.relu(tf.matmul(observations, W1)) # 参数相乘经激活后输出
W2 = tf.get_variable("W2", shape=[H, 1], # 初始化隐含层权重W2,维度为[H,1]
initializer=tf.contrib.layers.xavier_initializer())
score = tf.matmul(layer1, W2)
probability = tf.nn.sigmoid(score) # 参数相乘经激活后输出
# 定义策略网络的loss函数
tvars = tf.trainable_variables() # 获取策略网络中全部可以训练的参数
input_y = tf.placeholder(tf.float32, [None, 1], name="input_y") # 定义虚拟label的占位符
advantages = tf.placeholder(tf.float32, name="reward_signal") # 定义Action潜在价值的占位符
loglik = tf.log(input_y * (input_y - probability) + (1 - input_y) * (input_y + probability))
loss = -tf.reduce_mean(loglik * advantages) # 交叉熵损失函数,取负数后作为loss
newGrads = tf.gradients(loss, tvars) # 求解模型参数关于loss
# 进行梯度的积累后更新参数,防止单一样本的随机扰动对模型的影响
adam = tf.train.AdamOptimizer(learning_rate=learning_rate) # 使用AdamOptimizer优化器
W1Grad = tf.placeholder(tf.float32, name="batch_grad1") # 定义W1梯度的占位符
W2Grad = tf.placeholder(tf.float32, name="batch_grad2") # 定义W2梯度的占位符
batchGrad = [W1Grad, W2Grad] # 合并w1和w2
updateGrads = adam.apply_gradients(zip(batchGrad, tvars)) # 执行updateGrads更新参数
# 计算r中每个Action的期望价值
# CartPole每次获得的Reward都和前面的Action有关,属于Delayed_Reward
# 衡量Action的期望价值要考虑当前的Reward和以后的Delayed_Reward
# 得到全部Action期望价值discounted_r
def discount_rewards(r):
discounted_r = np.zeros_like(r)
running_add = 0
for t in reversed(range(0, r.size)):
running_add = running_add * gamma + r[t] # 从后往前累计running_add,越往前期望价值越大
discounted_r[t] = running_add
return discounted_r
# xs为环境信息observeration的列表
# ys为定义label的列表
# drs为记录每一个Action的Reward
xs, hs, dlogps, drs, ys, tfps = [], [], [], [], [], []
running_reward = None
reward_sum = 0 # 累计的Reward
episode_number = 1 # 迭代次数初始值
total_episodes = 10000 # 总的试验次数
init = tf.initialize_all_variables()
# 模型开始工作
with tf.Session() as sess:
rendering = False
sess.run(init) # 初始化所有参数
observation = env.reset() # 得到环境的初始observation
gradBuffer = sess.run(tvars) # 创建存储参数梯度的缓冲器gradBuffer
for ix, grad in enumerate(gradBuffer): # 初始化gradBuffer
gradBuffer[ix] = grad * 0
while episode_number <= total_episodes:
if reward_sum / batch_size > 100 or rendering == True: # 当某个batch的平均Reward到达100以上时,说明Agent表现良好
env.render() # 对试验环境进行渲染
rendering = True # 保持渲染
# 进行一次试验,并更新记录于xs,ys和drs
x = np.reshape(observation, [1, D]) # 将输入observation的维度限定为[1, D]
tfprob = sess.run(probability, feed_dict={observations: x}) # 通过策略网络得到Action为1的概率
action = 1 if np.random.uniform() < tfprob else 0 # 随机取值判断
xs.append(x) # 将输入的环境信息添加到xs
y = 1 if action == 0 else 0 # 虚拟label
ys.append(y) # 将虚拟label加入到ys
observation, reward, done, info = env.step(action) # 环境执行一次Action
reward_sum += reward # 累加Reward
drs.append(reward) # 将每一个Action的Reward添加到drs
if done: # 一次试验结束
episode_number += 1
# 更新gradBuffer
epx = np.vstack(xs) # 使用np.vstack纵向堆叠xs
epy = np.vstack(ys) # 使用np.vstack纵向堆叠ys
epr = np.vstack(drs) # 使用np.vstack纵向堆叠drs
tfp = tfps
xs, hs, dlogps, drs, ys, tfps = [], [], [], [], [], [] # 清空列表
discounted_epr = discount_rewards(epr) # 计算每一步Action的潜在价值
discounted_epr -= np.mean(discounted_epr) # 标准化discounted_epr为一个正态分布
discounted_epr /= np.std(discounted_epr) # discounted_epr参与损失的计算,有利于训练的稳定
tGrad = sess.run(newGrads, feed_dict={observations: epx, input_y: epy, advantages: discounted_epr})
# writer = tf.summary.FileWriter('./improved_graph2', sess.graph) # tensorboard可视化
for ix, grad in enumerate(tGrad): # 得到本次试验的梯度
gradBuffer[ix] += grad # 将获得的梯度累加到gradBuffer中
# 迭代次数达到batch_size更新参数并打印数据
if episode_number % batch_size == 0: # 达到batch_size的整数倍时,gradBuffer已积累了足够的梯度
sess.run(updateGrads, feed_dict={W1Grad: gradBuffer[0], W2Grad: gradBuffer[1]})
for ix, grad in enumerate(gradBuffer): # 使用updateGrads和gradBuffer更新策略网络的参数
gradBuffer[ix] = grad * 0 # 清空gradBuffer
running_reward = reward_sum if running_reward is None else running_reward * 0.99 + reward_sum * 0.01
print('Average reward for episode %f. Total average reward %f.' % (
reward_sum / batch_size, running_reward / batch_size)) # 打印Reward数据
if reward_sum / batch_size >= 200:
print("Task solved in", episode_number, 'episodes!') # 打印solved
break
reward_sum = 0 # reward_sum清零
observation = env.reset() # 重置env,进行下一次试验
print(episode_number, 'Episodes completed.') # 试验次数已经完成