Python+selenium+Chromedriver+代理爬取Google图片
代码更新,缘由之前是缩略图,一直问怎么爬取原图,索性代码写在下面,莫嫌弃low。
想分享源码的原因就是发现网上有关于Google图片的抓取竟然很少很少有介绍,而且有一个分享的代码竟然还加密收钱mmp,很看不惯索性自己写一个共享出来当然代码可能会有点low就不要在意了。废话不多说上代码。
- 准备工作1:
Chromedriver的安装对应版本介绍参考网站如下:
https://blog.csdn.net/yoyocat915/article/details/80580066 # 参考版本【转载yoyocat915】
http://chromedriver.storage.googleapis.com/index.html # 对应版本下载
因为之前的工作一直没有selenium,今天索性用用
2. 准备工作2:
外网的准备,如果你本公司有的话就不用买了,如果没有想要科学上网这里打一波广告可去这个网站购买
https://g.2333.tn/ #购买的过程在这里就不介绍了
买过来后进行调试在这里作者就被公司的外网给坑了不少直接提出来坑在那防止你被坑
第一步:首先调试为全局模式,不然仅仅就Google能进行访问外网这样你是无法用其他浏览器访问外网的(个人理解)

第二步:查看自己所用的端口
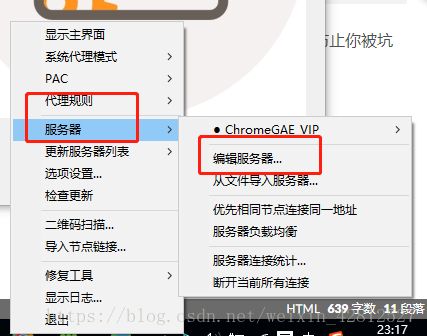

ok到这边几步已经可以开始编码了,那么便进行分析怎么使用selenium+chrome来实现图片的抓取了。分享代码如下如果你selenium使用不太熟练,基础教程这边也不分享了,因为我也在学习过程中。代码流程分享如下:
在这之前介绍一个图片储存的用法:
urllib.request.urlretrieve(图片的路径.jpg结尾\图片的base64编码,‘储存的位置)
可以参考博客:https://blog.csdn.net/wuguangbin1230/article/details/77680058
好了上最初的代码版本1.0
import os
import time
import urllib
from scrapy import Selector
from selenium import webdriver
class GoogleImgCrawl:
def __init__(self):
self.browser = webdriver.Chrome('F:\MyDownloads\chromedriver.exe')
self.browser.maximize_window()
self.key_world = input('Please input the content of the picture you want to grab >:')
self.img_path = r'D:\GoogleImgDownLoad' # 下载到的本地目录
if not os.path.exists(self.img_path): # 路径不存在时创建一个
os.makedirs(self.img_path)
def start_crawl(self):
self.browser.get('https://www.google.com/search?q=%s' % self.key_world)
self.browser.implicitly_wait(3) # 隐形等待时间
self.browser.find_element_by_xpath('//a[@class="iu-card-header"]').click() # 找到图片的链接点击进去
time.sleep(3) # 休眠3秒使其加载完毕
img_source = self.browser.page_source
img_source = Selector(text=img_source)
self.img_down(img_source) # 第一次下载图片
self.slide_down() # 向下滑动继续加载图片
def slide_down(self):
for i in range(7, 20): # 自己可以任意设置
pos = i * 500 # 每次向下滑动500
js = "document.documentElement.scrollTop=%s" % pos
self.browser.execute_script(js)
time.sleep(3)
img_source = Selector(text=self.browser.page_source)
self.img_down(img_source)
def img_down(self, img_source):
img_url_list = img_source.xpath('//div[@class="THL2l"]/../img/@src').extract()
for each_url in img_url_list:
if 'https' not in each_url: #仅仅就第一页可以,其他误判这个代码不是完整的是作者的错代码。
# print(each_url)
each_img_source = urllib.request.urlretrieve(each_url,
'%s/%s.jpg' % (self.img_path, time.time())) # 储存图片
if __name__ == '__main__':
google_img = GoogleImgCrawl()
google_img.start_crawl()
在这里所遇到的坑如下截图:
截图一:
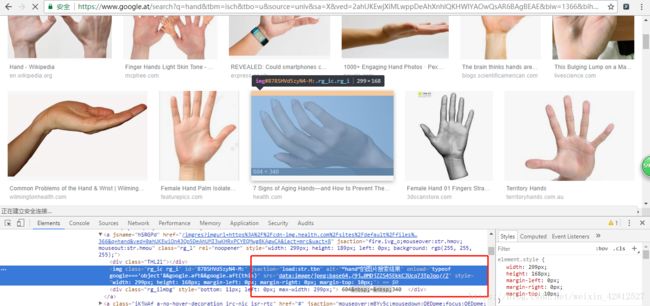
前20张图片的src显示的是base64编码呀这样就直接可以用上边的代码进行解决了呀可是你们看后边的图片src是什么?如下图
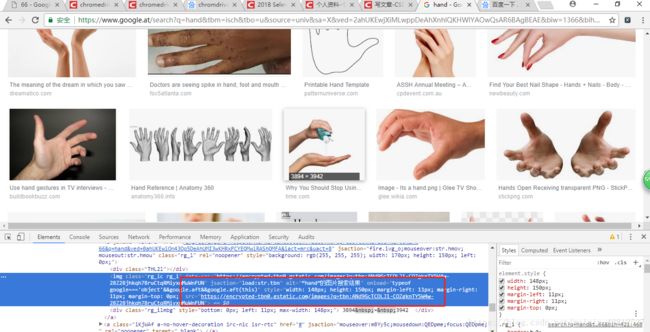
在这里既不是base64也不是以.jpg结尾的我去这怎么保存呢?难道使用
self.browser.get(图片的地址)
img_source = self.browser.page_source
通过这个继续拿吗?如果你这样想就错了,因为我们拿到的还是完完整整的页面呀,所以这个时候怎么办呀?想到我们最初的使用requests请求图片地址呀,这个时候作者便索性试了一下取出单独的图片src进行请求如果不加代理是肯定错了。所以加上代理如下结果:
import time
import requests
proxy = {"https": "https://127.0.0.1:8787"} //端口作者在前边的坑已经介绍了需要外网的端口
response = requests.get(
'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTwwkW09Hrnq5DOzSYAKqrxv3uGjbQzoCRP28AOF03pzJ2uFObS',
proxies=proxy, verify=False)
with open('./image%s.jpg' % time.time(), 'wb')as f:
f.write(response.content)
结果就是拿到了想要的结果

这样你知道该怎样修改上边的代码了吗?哈哈哈可能有点乱呀
修改代码如下:
import os
import time
import urllib
import requests
from scrapy import Selector
from selenium import webdriver
class GoogleImgCrawl:
def __init__(self):
self.proxy = {"https": "https://127.0.0.1:8787"} #初始化代理
self.browser = webdriver.Chrome('F:\MyDownloads\chromedriver.exe')
self.browser.maximize_window() #最大的适应屏幕
self.key_world = input('Please input the content of the picture you want to grab >:')
self.img_path = r'D:\GoogleImgDownLoad' # 下载到的本地目录
if not os.path.exists(self.img_path): # 路径不存在时创建一个
os.makedirs(self.img_path)
def start_crawl(self):
self.browser.get('https://www.google.com/search?q=%s' % self.key_world)
self.browser.implicitly_wait(3) # 隐形等待时间
self.browser.find_element_by_xpath('//a[@class="iu-card-header"]').click() # 找到图片的链接点击进去
time.sleep(3) # 休眠3秒使其加载完毕
img_source = self.browser.page_source
img_source = Selector(text=img_source)
self.img_down(img_source) # 第一次下载图片
self.slide_down() # 向下滑动继续加载图片
def slide_down(self):
for i in range(7, 20): # 自己可以任意设置
pos = i * 500 # 每次向下滑动500
js = "document.documentElement.scrollTop=%s" % pos
self.browser.execute_script(js)
time.sleep(3)
img_source = Selector(text=self.browser.page_source)
self.img_down(img_source)
def img_down(self, img_source):
img_url_list = img_source.xpath('//div[@class="THL2l"]/../img/@src').extract()
for each_url in img_url_list:
if 'https' not in each_url:
# print(each_url)
each_img_source = urllib.request.urlretrieve(each_url,
'%s/%s.jpg' % (self.img_path, time.time())) # 储存图片
else: #在这里添加一个不久行了吗?如果图片的链接不是base64的
response = requests.get(each_url,proxies=self.proxy, verify=False)
with open('D:\GoogleImgDownLoad\%s.jpg' % time.time(), 'wb')as f:
f.write(response.content)
if __name__ == '__main__':
google_img = GoogleImgCrawl()
google_img.start_crawl()
以上就是分享结束,当然直接使用requests模块+代理,也是比较方便的。百度的爬虫这边就不做分享了想要源码的联系作者分享个给你。当然美中不足的是图片的去重这边还么有做,也很简单的不知道你有没有想到思路反正作者这边是有思路咯。已经深夜了洗洗睡吧哈。
更新代码,原图获取…2019/1/21
import os
import time
import requests
from scrapy import Selector
from selenium import webdriver
from google_img.bloom_filter import *
class GoogleImgCrawl:
def __init__(self):
"""
初始化一些变量
"""
self.bf = BloomFilter() # 初始布隆过滤器
self.browser = webdriver.Chrome('G:\ChromDownLoad\chromedriver.exe')
self.browser.maximize_window()
self.proxy = {"https": "https://127.0.0.1:1080"} # 初始化代理
self.key_world = input('Please input the content of the picture you want to grab >:')
self.img_path = r'D:\Image\GoogleImgDownLoad\dog' # 下载到的本地目录
if not os.path.exists(self.img_path): # 路径不存在时创建一个
os.makedirs(self.img_path)
def start_crawl(self):
"""
抓取首页的内容
:return:
"""
self.browser.get('https://www.google.com/search?q=%s' % self.key_world)
self.browser.implicitly_wait(3) # 隐形等待时间
self.browser.find_element_by_xpath('//a[contains(text(),"图片")]').click() # 找到图片的链接点击进去
time.sleep(1) # 休眠3秒使其加载完毕
img_source = self.browser.page_source
img_source = Selector(text=img_source)
self.img_down(img_source) # 第一次下载图片
self.slide_down() # 向下滑动继续加载图片
def slide_down(self):
"""
向下滑动抓取,每次滑动1000高度
:return:
"""
for i in range(7, 100): # 自己可以任意设置
pos = i * 800 # 每次向下滑动800
js = "document.documentElement.scrollTop=%s" % pos
self.browser.execute_script(js)
time.sleep(3)
if int(i) == 20:
print(self.browser.page_source)
img_source = Selector(text=self.browser.page_source)
try:
self.img_down(img_source)
except BaseException as e:
print(e)
def img_down(self, img_source):
"""
图片的下载功能
:param img_source: 获取响应的内容
:return:
"""
img_url_list = img_source.xpath('//a[@jsname="hSRGPd"]/@href').extract()
for each_url in img_url_list:
if '#' not in each_url:
each_url = 'https://www.google.com' + each_url
if self.bf.isContains(each_url):
print('this %s url is exists!' % each_url)
continue
else:
try:
self.bf.insert(each_url)
except BaseException as e:
print('已经存在......')
else:
try:
response = requests.get(each_url, proxies=self.proxy, verify=False, timeout=3) # 请求大图的网址
except BaseException as e:
print(e)
else:
img_info = Selector(text=response.content)
img_url = img_info.xpath('//div[@id="il_ic"]/img/@src').extract_first() # 获取图片的网址
try:
response = requests.get(img_url, proxies=self.proxy, verify=False, timeout=3)
except BaseException as e:
print(e)
else:
print('正在下载中................')
with open('%s/%s.jpg' % (self.img_path, time.time()), 'wb')as f:
f.write(response.content)
if __name__ == '__main__':
google_img = GoogleImgCrawl()
google_img.start_crawl()
不明白的继续讨论,有更好的方法欢迎分享一起进步,代码有错误的地方请指出。