yolov3实现训练自己数据集
环境:win10,GPU显卡:1660Ti,keras2.1.5,tensorflow:1.13.1 数据集:安检X光危险品图片
文章目录
- 1.制作数据集
- 1.1标定
- 1.2制作成voc数据集
- 2.开始训练
- 2.1加入VOC数据集
- 2.2修改相关文件准备训练
- 2.3kmeans聚类生成anchors(可选)
- 2.4开始训练
- 3.模型测试
1.制作数据集
1.1标定
1.标定软件为labeling,标注生成xml文件,传送门:labeling 提取码:uh9t。使用起来比较简单
2.保存
保存格式为xml,如下:

1.2制作成voc数据集
1.在代码文件夹目录下创建文件夹VOC2007,并在该文件夹下分别创建Annotations、ImageSets、JPEGImage三个文件夹,并继续在ImageSets下创建文件夹Main。然后将上文标注的xml文件(即类别标签)放入Annotations文件夹,将数据集图片放入JPEGImage文件夹。

2.复制下面test.py放在VOC2007同级目录下运行,注意路径不要错误。
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = './VOC2007/Annotations'
txtsavepath = './VOC2007/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('./VOC2007/ImageSets/Main/trainval.txt', 'w')
ftest = open('./VOC2007/ImageSets/Main/test.txt', 'w')
ftrain = open('./VOC2007/ImageSets/Main/train.txt', 'w')
fval = open('./VOC2007/ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
运行test.py后将在Main文件夹下生成四个txt文件,到此VOC数据集制作完毕。

2.开始训练
2.1加入VOC数据集
yolov3提供了将VOC数据集转为YOLO训练所需要的格式的代码,voc_annotation.py。此时需要修改的地方有两处:
sets和classes。改成自己数据需要的形式,classes为自己数据类别标签。
import xml.etree.ElementTree as ET
from os import getcwd
sets=[('2007', 'train'), ('2007', 'test')] #需要自行修改
classes = ["dahuoji", "daoju", "dian", "heidingzi", "jiandao"] #根据自己数据集修改
def convert_annotation(year, image_id, list_file):
in_file = open('VOC%s/Annotations/%s.xml'%(year, image_id))
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
wd = getcwd()
for year, image_set in sets:
image_ids = open('VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%sVOC%s/JPEGImages/%s.jpg'%(wd, year, image_id))
convert_annotation(year, image_id, list_file)
list_file.write('\n')
list_file.close()
运行后会生成两个txt文件

该文件内容如下图,包含了框的信息。使用下面语言合并生成train.txt文件可用于kmeans算法聚类和训练。
type 2007_train.txt 2007_val.txt > train.txt

2.2修改相关文件准备训练
1.修改model_data下的文件,classes和anchors,classes改成自己的数据类的名称,anchors由作者聚类VOC得到,如果自己的数据集与VOC差异很大,则可以自己通过kmeans.py聚类得到来进行修改,后面会提到。
2.对goods-train里面的cfg文件进行修改。此处注意若从零训练则不需要修改该文件,若使用预训练权重来训练则需要修改:进入文件,ctrl+f搜索yolo,共至少三处需要修改。
(1)filters:3*(5+len(classes))
(2)classes:自己数据标签种类个数
(3)random:原来是1,显存小改为0。(是否要多尺度输出。)
另外如果anchors自己聚类的话也需要修改,本文做过修改,后面会提到。

2.3kmeans聚类生成anchors(可选)
如果自己数据和VOC相差很大,则可以自己聚类生成anchors,打开kmeans.py,利用2.1生成的train.txt进行聚类,cluster_number为生成框的数量,以下为修改部分代码。fliename改成“train.txt",下面展示代码已经修改完成,这是数据集所有标定框的数据信息,根据其聚类产生anchors。
if __name__ == "__main__":
cluster_number = 9
filename = "train.txt"
kmeans = YOLO_Kmeans(cluster_number, filename)
kmeans.txt2clusters()
下面部分设置anchors保存路径。
def result2txt(self, data):
f = open("model_data/my_yolo_anchors.txt", 'w')
row = np.shape(data)[0]
for i in range(row):
if i == 0:
x_y = "%d,%d" % (data[i][0], data[i][1])
else:
x_y = ", %d,%d" % (data[i][0], data[i][1])
f.write(x_y)
f.close()运行后会在model_data文件夹下生成my_yolo_anchors.txt文件,即为自己数据生成的anchors。
2.4开始训练
做完以上工作即可运行train.py进行训练。以下路径需要自行修改,annotation_path,log_dir,classes_path,anchors_path分别代表了训练图片数据的路径,模型存放路径,数据集种类路径,模型anchors数据路径,如果按照以上步骤则不需要修改。其中log_dir的logs/000文件夹需要自己创建,以用来保存生成的权重文件。
def _main():
annotation_path = '2007_train.txt'
log_dir = 'logs/000/' #训练自己模型保存的目录,要创建不然报错
classes_path = 'model_data/goods_classes.txt'
anchors_path = 'model_data/my_yolo_anchors.txt'
class_names = get_classes(classes_path)
num_classes = len(class_names)
anchors = get_anchors(anchors_path)训练模式有两种,加载预训练权重和从零训练。默认加载预训练权重,若要更改则将其中create_model函数的load_pretrained=True改成False。训练分成两个阶段:
(1)第一阶段,冻结(freeze)部分网络,只训练底层权重,在训练过程中,也会不断保存,epoch完成的模型权重
(2)第二阶段,将全部权重设置为可训练,使用第1阶段已训练完成的网络权重,继续训练。训练完成后输出的网络权重,就是最终的模型权重。权重文件保存在logs/000/trained_weights_final.h5。
如果显存不够报错则需要修改batch_size,本人计算机资源有限所以将第二阶段batch_size改成了4。
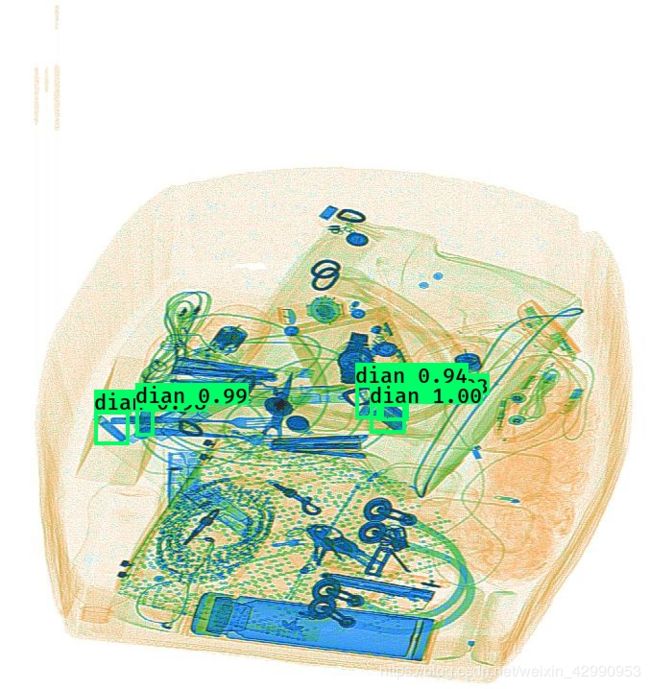
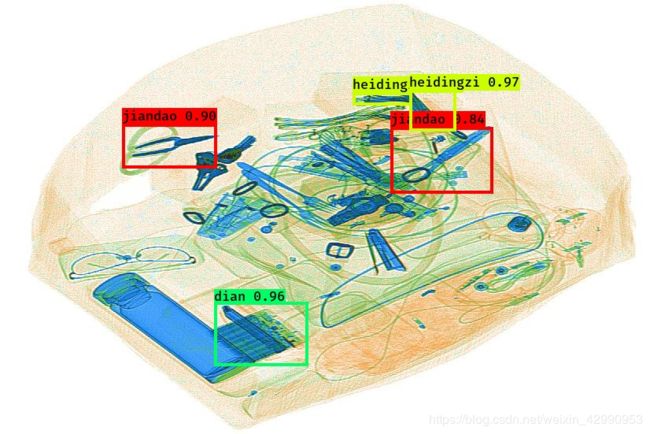
3.模型测试
模型已经训练完成,最后即可进行测试。这里以yolo_image.py为例,其他照例。对以下路径进行修改,改成自己的路径,包括权重文件、anchors文件以及类别文件。
class YOLO(object):
def __init__(self):
self.model_path = 'logs/000/trained_weights_final.h5' # model path or trained weights path
self.anchors_path = 'model_data/my_yolo_anchors.txt'
self.classes_path = 'model_data/goods_classes.txt'
运行,部分结果如下,这里结果并不是很好,因为显存不够没训练好,batch_size被改成了4。
完工。