数据处理实例
前言:自己也是小白,主要用作练习和熟悉方法,其实里面很多处理方法还是花了心思去想的(可能还是不是特别简便,特别是膜拜的那个问题,欢迎指正),不涉及算法知识,仅锻炼自己的数据处理能力,数据集如有需要指明用处可共享,这里推荐一篇文章Python数据分析实战基础
数据挖掘专栏
- 数据挖掘——python基础
- 数据挖掘——numpy基础
- 数据挖掘——pandas基础
- 数据挖掘——matplotlib+seaborn数据可视化
文章目录
- 一、微博热点话题发现
- 二、膜拜单车数据分析
- 三、2017国赛数模B题数据处理
- 四、杭电宣讲会信息爬取
- 五、宣讲会信息统计——groupby
一、微博热点话题发现
数据介绍: Use of this dataset in publications must be acknowledged by referencing the following publication:
King-wa Fu, CH Chan, Michael Chau. Assessing Censorship on Microblogs in China: Discriminatory Keyword Analysis and Impact Evaluation of the ‘Real Name Registration’ Policy. IEEE Internet Computing. 2013; 17(3): 42-50. http://doi.ieeecomputersociety.org/10.1109/MIC.2013.28

我们的任务是提取热点话题,代码如下:
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 12 18:51:28 2019
@author: try
"""
import pandas as pd
import matplotlib.pyplot as plt
#import re
#读取数据
user_data=pd.read_table(r'userdata.csv',sep=',')
week_data=pd.read_table(r'week1.csv',sep=',',encoding='utf-8',error_bad_lines=False)
V_count=user_data['verified'].value_counts()#统计是否认证人数
plt.figure(1)
V_count.plot(kind='bar')#画是否认证人数对比图
#统计发博和被转发次数
uid_count=week_data['uid'].value_counts()
retweeted_uid_count=week_data['retweeted_uid'].value_counts()
#mid_data=mid_count.loc[mid_count>10]
#用dataframe进行正则提取,提取话题
data_text=week_data['text']
#str.extract用正则从字符数据中抽取匹配的数据,只返回第一个匹配的数据
out_text=data_text.str.extract(r'#(.*?)#',expand=True)
out_text1=out_text.dropna()#删除空行
out_text1=out_text1.reset_index(drop=True)#重新设置index
out_text1.columns=['text_R']
out_text1.rename(columns={'text_R':'text'},inplace=True)
#对话题统计
out_text_count=out_text1['text'].value_counts()#统计话题数目
out_text_count=out_text_count.loc[out_text_count>1000]
plt.figure(2)
out_text_count.plot(kind='bar',width=0.8)
#转发次数分区间统计
t_data=week_data['retweeted_uid'].value_counts()
Se_t=pd.Series(t_data)
#分区间统计
bin_t=range(0,3000,100)
count_t=pd.cut(Se_t,bin_t).value_counts()
plt.figure(3)
plt.title('被转发次数统计')
count_t.plot(kind='bar')
提取结果如下:


二、膜拜单车数据分析
数据:2017年5月两周内,北京40余万辆摩拜单车被30余万摩拜用户的使用情况(该开源数据来源于2017年摩拜算法挑战赛)。数据包含300余万条出行记录数据,每条的数据包含了订单号(orderid )、用户编号(userid )、单车编号(bikeid)、单车类(biketype)、开始使用单车时间(starttime)、使用起点坐标(startloc)和使用终点坐标(endloc),其中起点和终点坐标经过了geohash加密(数据考虑到各方面原因,就不放出来了)
python代码如下:
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import pandas as pd
import geohash
#读取
data=pd.read_csv(r'mobike_train_data.csv',sep=',')
#日期格式处理
data.starttime=data.starttime.astype('str')
data.starttime=pd.to_datetime(data.starttime,format='%Y-%m-%d %H:%M:%S')
data=data.dropna()#缺失值删除
#geohash解码
data["start_lat_lng"] = data["geohashed_start_loc"].apply(lambda s: geohash.decode(s))
data["end_lat_lng"] = data["geohashed_end_loc"].apply(lambda s: geohash.decode(s))
#筛选14-24号的数据
data_14=data.loc[data.starttime<='2017-05-14 23:59:59']
data_15=data.loc[(data.starttime<='2017-05-15 23:59:59')&(data.starttime>'2017-05-14 23:59:59')]
data_16=data.loc[(data.starttime<='2017-05-16 23:59:59')&(data.starttime>'2017-05-15 23:59:59')]
#data_17=data.loc[(data.starttime<='2017-05-17 23:59:59')&(data.starttime>'2017-05-16 23:59:59')]
#17号数据是空的
data_18=data.loc[(data.starttime<='2017-05-18 23:59:59')&(data.starttime>'2017-05-17 23:59:59')]
data_19=data.loc[(data.starttime<='2017-05-19 23:59:59')&(data.starttime>'2017-05-18 23:59:59')]
data_20=data.loc[(data.starttime<='2017-05-20 23:59:59')&(data.starttime>'2017-05-19 23:59:59')]
data_21=data.loc[(data.starttime<='2017-05-21 23:59:59')&(data.starttime>'2017-05-20 23:59:59')]
data_22=data.loc[(data.starttime<='2017-05-22 23:59:59')&(data.starttime>'2017-05-21 23:59:59')]
data_23=data.loc[(data.starttime<='2017-05-23 23:59:59')&(data.starttime>'2017-05-22 23:59:59')]
data_24=data.loc[(data.starttime<='2017-05-24 23:59:59')&(data.starttime>'2017-05-23 23:59:59')]
#统计14号数据
bike_count_14=data_14['bikeid'].value_counts()
user_count_14=data_14['userid'].value_counts()
#时间分区间统计
bin=pd.date_range(start='2017-05-14 00:00:00',end='2017-05-15 00:00:00',freq='0.5H')
data_scattertime=pd.cut(data_14['starttime'],bin)
scattertime_count=data_scattertime.value_counts(sort=False)
scattertime_count.plot(kind='line')
14号的分时间段的订单量结果图:

三、2017国赛数模B题数据处理
之所以选择这一题进行练习,是因为这一题涉及地图、经纬度相关模块和方法
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 18 20:17:00 2019
@author: 1
"""
import pandas as pd
import matplotlib.pyplot as plt
import smopy
#读取数据
df=pd.read_excel('附件一:已结束项目任务数据.xls')
#地图上画出任务的坐标
hz=smopy.Map((22.45, 112.65, 23.9, 114.5),z=10)
#hz.show_ipython()
#其中需要输入的参数为(lat_min, lon_min, lat_max, lon_max),即区域的经纬度范围。z为缩放程度,如果不指定的话smopy会自动使用最大缩放程度。
x, y = hz.to_pixels(df['任务gps 纬度'], df['任务gps经度'])
ax = hz.show_mpl(figsize=(8, 6))
ax.plot(x, y, 'or', ms=2)
#找定价高的地方
df_max=df.loc[df['任务标价']>=70]
x1, y1 = hz.to_pixels(df_max['任务gps 纬度'], df_max['任务gps经度'])
ax.plot(x1,y1,'ob',ms=2)
#读取会员数据
df_vip=pd.read_table('附件二:会员信息数据.csv',sep='\\s+')
x2,y2=hz.to_pixels(df_vip['纬度'],df_vip['纬度'])
ax.plot(x2,y2,'og',ms=2)
plt.show()
处理结果:

四、杭电宣讲会信息爬取
爬取内容: 宣讲单位,宣讲时间,所在学校,宣讲地点,单位简介等
项目需求
- 实现两层网页的信息爬取,并将爬取的信息进行整合保存到 excel 文件中。
(1) 基础:爬取一个外层页中,所有内层页的信息
(2) 进阶:爬取多个外层页中, 所有内层页的信息 - 每个题目中, 至少爬取上述给定爬取内容中的五项。
- 自学数据可视化方法,将爬取结果以曲线图、 柱状图等方式显示。
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 2 20:29:39 2019
@author: 1
"""
import requests # 导入网页请求库
from bs4 import BeautifulSoup # 导入网页解析库
import pandas as pd
import json
import re
#http://career.hdu.edu.cn/module/getcareers?start_page=1&k=&panel_name=&type=inner&day=&count=15&start=1&_=1572698708166 第一页
#http://career.hdu.edu.cn/module/getcareers?start_page=1&k=&panel_name=&type=inner&day=&count=15&start=2&_=1572698708167 第二页
#http://career.hdu.edu.cn/module/getcareers?start_page=1&k=&panel_name=&type=inner&day=&count=15&start=3&_=1572698708168 第三页
#http://career.hdu.edu.cn/module/careers?menu_id=6438
#http://career.hdu.edu.cn/detail/career?id=career_talk_id 二级网页
# 发起请求
def start_requests(url):
#print(url) # 查看在抓取哪个链接
r = requests.get(url)
return r.text
# 解析一级网页,获取career_talk_id列表
def get_id(text):
#soup = BeautifulSoup(text, 'html.parser')
list_id=[]
content=json.loads(text)
for item in content['data']:
list_id.append(item['career_talk_id'])
return list_id#返回序列
# 解析二级网页,获取公司简介信息
def parse_page(text):
mydict={}
soup = BeautifulSoup(text, 'html.parser')
pattern=re.compile(r'[\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5\d+]')
#data_name=soup.find('h1',class_="dm-text",style="font-weight:normal;").text.split('宣讲单位:')[1]
data_name=pattern.findall(soup.find('h1',class_="dm-text",style="font-weight:normal;").text.split('宣讲单位:')[1])
data_company=pattern.findall(str(soup.select('#data_details > div.main > div > div:nth-child(2) > div.dm-cont')))
#div class="dm-cont" style="font-size:14px;line-height:22px;"
data_time=soup.find_all('p',class_="dm-text")[0].text.split('宣讲时间:')[1]
data_school=soup.find_all('p',class_="dm-text")[1].text.split('所在学校:')[1]
data_place=soup.find_all('p',class_="dm-text")[2].text.split('宣讲地点:')[1]
str_data=''.join(data_company)
str_name=''.join(data_name)
mydict['宣讲地点']=data_place
mydict['公司简介']=str_data.replace('1422','')
mydict['宣讲学校']=data_school
mydict['宣讲单位']=str_name
mydict['宣讲时间']=data_time
return mydict#返回字典
#数据整理
def get_result():
for i in range(1572698708166, 1572698708168):
url = 'http://career.hdu.edu.cn/module/getcareers?start_page=1&k=&panel_name=&type=inner&day=&count=15&start={}&_={}'.format(i-1572698708165,i)
text = start_requests(url)
list_id= get_id(text) # 解析一级页面,获取二级页面的career_talk_id
for career_id in list_id: # 解析二级页面
url_2='http://career.hdu.edu.cn/detail/career?id={}'.format(career_id)
page = start_requests(url_2)
mydict= parse_page(page)#dict的信息
result_list.append(mydict)
return result_list#返回列表
#运行,可视化+写入excel
if __name__ == '__main__':
result_list=[]
result_list=get_result()
df=pd.DataFrame(result_list)
df['宣讲时间'].value_counts().plot(kind='bar')
df.to_excel('data.xlsx')
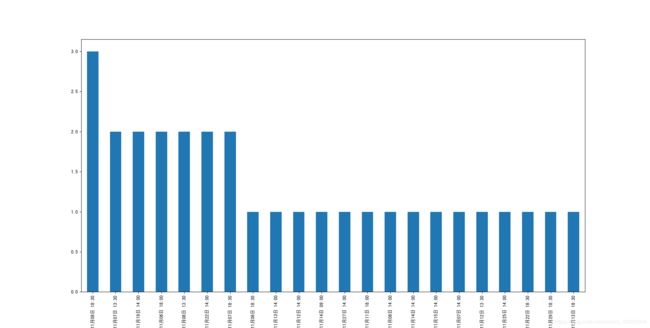
最终得到data.xlsx和一个宣讲时间数量统计图(属实无聊,但是作业要做hhhhh):
五、宣讲会信息统计——groupby
现有数据如下格式:

我们需要根据日期统计日点击量,画出日点击量图
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 7 18:39:18 2019
@author: 1
"""
import pandas as pd
from matplotlib import pyplot as plt
df=pd.read_excel('test.xls',header=None)
df.columns=['公司','时间','地点','学校','地点','点击量']
df['time']=df['时间'].str.extract(r'(\d+年\d+月\d+日)', expand=False)
df_new=df.iloc[:,[5,6]]
df_sum=df_new['点击量'].groupby(df_new['time']).sum()
plt.figure(1)
df_sum.plot(kind='bar')
plt.xlabel('日期')
plt.ylabel('点击量')
df.groupby会生成GroupBy的对象,可以调用mean(), count(), sum()等方法产生一个Series,其中索引为‘id’中的唯一值,去除重复值。格式:df.groupby(df[‘含重复值的列’]).计算函数()
得出结果如下:
