使用scrapy爬取小说网站的所有小说内容,并且使用简易的flask框架显示所有书和章节与内容
一、爬小说
scrapy startproject demo
cd demo
scrapy genspider novel
设计mysql表结构如下:
1.存放书的表
create table novels_item(
novel_id int auto_increment primary key,
novel_name varchar(20));
2.存放章节和章节内容的表
create table novels(
chapter_id int primary key auto_increment,
novel_id int,
chapter_name varchar(50),
chapter_content text(50000),
foreign key (novel_id) references novels_item(novel_id));
在novel.py文件中做一下操作:
# -*- coding: utf-8 -*-
import scrapy
from demo.items import NocelContentItem
from selenium import webdriver
from demo.items import NovelItem
class NovelSpider(scrapy.Spider):
name = 'novel'
allowed_domains = ['jinyongwang.com']
start_urls = ['http://www.jinyongwang.com/book/']
baseurl = "http://www.jinyongwang.com"
def start_requests(self):
for url in self.start_urls:
req=scrapy.Request(url,callback=self.novel)
yield req
def novel(self,response):
allurls = []
tags_li=response.xpath('//ul[@class="list"]/li/p/a/@href')
#这个方法for循环是循环返回书
# for li in tags_li:
# url=li.extract_first()
# # allurls.append(url)
# req=self.baseurl+url.strip()
# yield scrapy.Request(url=req,callback=self.novelName)
#这里做测试,只抓取一本书
url = tags_li.extract_first()
req = self.baseurl + url.strip()
#req是单本书的href路径
yield scrapy.Request(url=req, callback=self.novelName)
def novelName(self, response):
"""
:param response: 单本书的信息页面,里面需要获取书的标题和该书章节
:return: 返回打开的各个章节页面url,并带着返回一个item对象
"""
#获取书名标签
novel_name_tag=response.xpath('//h1[@class="title"]/span/text()')
#提取书名
novel_name=novel_name_tag.extract_first().strip()
#获取所有章节标签
tags_li=response.xpath('//ul[@class="mlist"]/li/a')
"""
返回一本书的对象,这个对象继承NovelItem
NovelItem包含的属性有:novel_name = scrapy.Field()
"""
novelitem=NovelItem()
novelitem["novel_name"]=novel_name
yield novelitem
#遍历所有章节
for li in tags_li:
"""
定义一个章节,字段如下:
书名:novel_name=scrapy.Field()
章节名: chapter_name = scrapy.Field()
章节内容: chapter_content = scrapy.Field()
"""
item = NocelContentItem()
item["novel_name"]=novel_name
href=li.xpath('./@href').extract_first().strip()
item["chapter_name"]=li.xpath('./text()').extract_first().strip()
#返回每个章节的url,并且返回一个章节的对象,还需要进一步打开网页获取里面具体内容
yield scrapy.Request(url=self.baseurl+href,callback=self.content,meta={"item":item})
def content(self,response):
"""
:param response: 打开的章节页面
:return: 返回一个item,即一个章节格式数据
"""
#接收传递过来的章节对象
item=response.meta.get("item")
#获取章节内容
chapter_content=response.xpath('//*[@id="vcon"]/p/text()').extract()
content="\n".join(chapter_content)
#存入章节内容的数据
item["chapter_content"]=content
#返回一个章节对象
yield item
在setting中打开pipelines
piplelines.py文件中做如下操作:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
from demo.items import NocelContentItem, NovelItem
class DemoPipeline(object):
def open_spider(self,spider):
print("打开爬虫",spider)
self.connect=pymysql.Connect(host="127.0.0.1",port=3306,user="zx",password="123456",database="spider",charset='utf8')
self.cursor=self.connect.cursor()
def process_item(self, item, spider):
#插入章节内容
if isinstance(item,NocelContentItem):
try:
"""
"开始插入章节内容!!"
id 要根据查找书的结果与书结合用
chapter_name = scrapy.Field()
chapter_content = scrapy.Field()
"""
#根据小说的名字匹配小说的id用于后面作为参数写入小说章节的novel_id字段
find_novel_id_sql='select novel_id from novels_item where novel_name=%s;'
self.cursor.execute(find_novel_id_sql, (item["novel_name"]))
a=self.cursor.fetchone()
item_id=a[0]
#写入章节内容,只需要item["chapter_name"], item["chapter_content"]两个字段内容
sql = 'insert into novels (novel_id,chapter_name ,chapter_content) values(%s,%s,%s);'
self.cursor.execute(sql, (item_id, item["chapter_name"], item["chapter_content"]))
self.connect.commit()
except:
self.connect.rollback()
#插入一本小说
elif isinstance(item,NovelItem):
try:
"""
开始插入书,只需要书名即可,书的id自动生成
"""
sql = 'insert into novels_item (novel_name) values(%s);'
self.cursor.execute(sql, (item["novel_name"]))
self.connect.commit()
except:
self.connect.rollback()
def close_spider(self,spider):
print("关闭爬虫")
self.cursor.close()
self.connect.close()
items的设计如下:
class NocelContentItem(scrapy.Item):
novel_name=scrapy.Field()
chapter_name = scrapy.Field()
chapter_content = scrapy.Field()
class NovelItem(scrapy.Item):
novel_name = scrapy.Field()
数据库中获取到所有的数据之后我利用flask做了简易的展示:
flask做了充分的架构,这里做了一个蓝本mainshow:
import pymysql
from flask import Blueprint, render_template, request
mainshow=Blueprint("mainshow",__name__)
@mainshow.route('/')
def index():
connect = pymysql.Connect(port=3306, host="127.0.0.1", user="zx", password="123456", database="spider")
cursor=connect.cursor()
#获取所有小说
find_all_novel="select * from novels_item"
cursor.execute(find_all_novel)
itemres=cursor.fetchall()
#获取所有的章节
find_all_chapter = "select * from novels order by novel_id,chapter_name"
cursor.execute(find_all_chapter)
novelres = cursor.fetchall()
cursor.close()
connect.close()
return render_template('mainshow.html',itemres=itemres,novelres=novelres)
@mainshow.route('/novle/')
def ownpage(page):
connect = pymysql.Connect(port=3306, host="127.0.0.1", user="zx", password="123456", database="spider")
cursor = connect.cursor()
#获取传入的章节id,找到章节内容
find_novel_content = "select * from novels where chapter_id="+str(page)+" ;"
cursor.execute(find_novel_content)
novel_content=cursor.fetchone()
#根据章节的novel_id字段找到小说的名字
get_novel_name='select novel_name from novels_item where novel_id='+str(novel_content[1])+';'
cursor.execute(get_novel_name)
novel_name = cursor.fetchone()[0]
cursor.close()
connect.close()
# 返回章节名和小说名
return render_template('pageshow.html', res=novel_content,novel_name=novel_name)
mainshow页面如下:
{% extends 'common/base.html' %}
{% block pagecontent %}
---爬过来的小说---
{% for res in itemres %}
{{ res.1 }}
{% for chapter in novelres %}
{% if chapter.1 == res.0 %}
{{ chapter.2 }}
{% if loop.index %5 ==0 %}
{% endif %}
{% endif %}
{% endfor %}
{% endfor %}
{% endblock %}
pageshow页面如下:
{% extends 'common/base.html' %}
{% block pagecontent %}
{{ novel_name }}
{{ res.2 }}
{{ res.3 }}
{% endblock %}
图片展示:
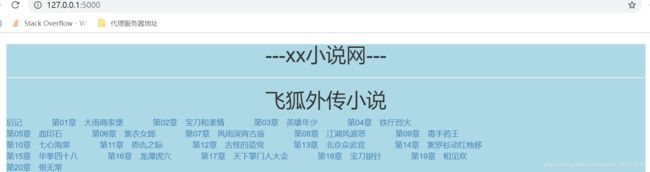
章节内容展示:
