进程简介及相关API
一个运行的系统通常会有多个进程并行其中。对进程来说许多时间发生都无法预期。执行中的进程不清楚自己对CPU的占用何时到期,系统随之又会调度哪个进程来使用CPU 也不知道自己何时会再次获得对CPU的使用。
对于进程而言,自己并不清楚自己在RAM中的哪个位置,也不知自己的所访问的文件居于磁盘驱动器的何处,只是通过名称来引用文件而已,进程运作的方式堪称与世隔绝,进程彼此之间不能直接通信。
进程也无法创建出新的进程,哪怕自行了断都不行,进程也不能与计算机外接的输入输出设备直接通信。
例如:某进程可以创建另一个进程、某进程可以创建管道、某进程可以将数据写入文件,以及调用exit()以终止进程。以上这些说法,不过是:某进程可以请求内核创建另一个进程,以此类推。
进程可以使用系统调用fork()来创建一个新进程。调用fork()的进程被称为父进程,新创建的进程则被称为子进程。内核通过对父进程的复制来创建子进程。子进程从父进程那儿集成数据段、栈段、以及堆段的副本后,可以修改这些内容,不会影响到父进程原来的内容(在内存中被标记为只读的程序文本段则由父子进程共享)。由此才会产生一些竞争条件,对此在后期会采用同步与互斥技术。
然后,子进程要么去执行与父进程共享代码段中的另一组不同的函数,或者更为常见的是使用系统调用execve()去加载并执行一个全新的程序。execve()将会销毁现有的文本段、数据段、栈段以及堆段。并根据程序的代码,创建新段来代替他们。这些将在下面的例子中体现出来。一步一步地来。
进程ID和父进程ID:
每个进程都有一个唯一的整数型进程标识符(PID),此外,每个进程还具有一个父进程标识符(PPID)属性,用以标识请求内核创建自己的进程。
Init进程:
系统引导时,内核会创建一个名为init的特殊进程,即“所有进程之父”,该进程对应的文件为:/sbin/init。系统的所有进程都是由init创建就是由其后代进程创建的。init进程号始终为1,且总是以超级用户权限运行。谁(哪怕是超级用户)都无法杀死init进程。只有当关闭系统时才能终止该进程。
Daemon进程:
daemon 守护进程或者叫精灵进程指的是具有特殊用途的进程,系统创建和处理此类进程 的方式与其他进程相同;但他独有的是:
-
“长生不老”,直至系统关闭前一直存在,当然用户创建的守护进程,可以用kill命令杀死。
-
后台运行,且无控制终端供其读取或写入数据。
由fork()创建的新进程,会继承其父进程对资源限制的设置。
进程通信与同步:
包含了6种通信方式:
-
管道:有名管道pipe和无名管道fifo用于在两条进程间传递数据(有阻塞性)
-
信号:用来表示事件的发生
-
消息队列:用于在多个进程间传递消息(有阻塞性)
-
共享内存:两个及以上的进程之间通信(共享同一块内存)当某一个进程修改了共享内存的内容时,其他所有进程会立即了解到这一变化。
-
信号量:用来同步进程的动作
-
套接字:不同主机之间多个进程之间的通信,遵循了很多通信协议。
将在后期整理出单独模块,这里仅介绍。
会话、控制终端和控制进程:
会话指的是一组进程组(任务)。会话中的所有进程都具有相同的会话标识符。
会话首进程:指创建会话的进程,其进程ID会成为会话ID。使用会话最多的是支持任务控制的shell,由shell创建的所有进程组与shell自身隶属于同一会话,shell是此会话组的首进程(组长)。
进程相关API:
系统调用fork()允许一进程(父进程)来创建一新进程(子进程)。具体做法是新的子进程几乎近于父进程的翻版:子进程获得父进程的栈段、数据段、堆段和执行文本段的靠背,可将此视为把父进程一分为二,彼此之间互不影响。

#include
pid_t fork(void); 调用fork()之后,系统将率先“垂青”于哪个进程(即调度其使用CPU)是无法确定的。
用下面三个看以简单却很地道的例子来阐述fork()的作用:
1.问:一共打印多少个hello world

答:打印8次helloworld

2.

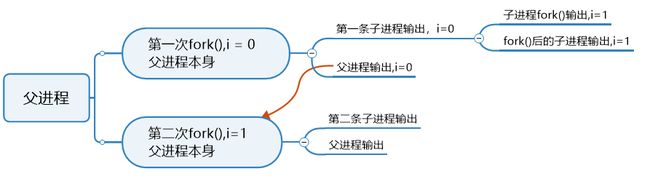
3.面试题(且看思维导图)

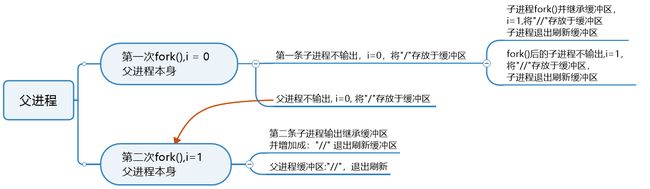
系统调用vfork():
vfork()因具有两个特性而更具有效率,这也是其与fork()的区别所在。
1.无需为子进程复制或虚拟内存页或页表。相反,子进程共享父进程内存,直至成功执行了exec()或exit()退出。
2.在子进程调用exec()或exit()之前,将暂停执行父进程。
由于子进程使用父进程内存,因此子进程对数据段、堆段和栈段的任何改变将在父进程恢复执行时为其所见。此外,如果子进程在vfork()与后续exec()或exit()之间执行了函数返回,同样会影响到父进程。因为系统是在内核空间中为每个进程维护文件描述符表,且在vfork()调用期间将复制该表,所以子进程对文件描述符的操作不会影响到父进程。
#include
pid_t vfork(void); 子进程共享父进程内存,父进程会一直挂起直至子进程终止或调用exec()。
获取进程ID:
Linux系统提供了2个系统调用用于获取进程的标识符和父进程的标识符。
#include
/* Get the process ID of the calling process. */
extern __pid_t getpid (void) __THROW;
/* Get the process ID of the calling process's parent. */
extern __pid_t getppid (void) __THROW; getpid()返回调用进程的进程ID。它经常被用来生成唯一的临时文件名。
getppid()返回调用进程的父进程的进程ID。
getpid()和getppid()系统调用不返回错误。
监控子进程:
在很多应用程序中,父进程需要知道某个子进程于何时改变了状态---子进程终止或因收到信号而停止。Unix/Linux提供系统调用wait()(以及变体)和SIGCHLD信号。
系统调用wait()等待调用进程的任一子进程终止,同时在参数status所指向的缓冲区中返回该子进程的终止状态。
#include
pid_t wait(int *status); 1.如果调用进程并无之前未被等待的子进程终止,调用讲一直阻塞,直至某个子进程终止。如果调用时已有子进程终止,wait()立即返回,
2.如果staus为非空,那么关于子进程如何终止的信息则会通过ststus指向的整形变量返回。
3.内核将会为父进程下所有子进程的运行总量追加进程访问CPU时间以及资源使用。
4.将终止子进程的ID作为wait()的结果返回。
出错时,wait()将返回-1.可能的原因之一:是调用进程并无之前未被等待的子进程,此时会将errno置为EXHILD。换言之,可用以下代码循环来等待调用进程的所有子进程退出。
1.如果父进程已经创建了多个子进程。使用wait()将无法等待某个特定子进程的完成。
2.如果没有子进程退出,wait()总是保持阻塞,有时希望执行非阻塞式的等待:是否有子进程退出,立刻得知。
3.使用wait()只能发现那些已经终止了的子进程。对于子进程因为某个信号(SIGSTOP或者SIGTTIN)而停止,或是已经停止子进程收到SIGCONT信号后恢复执行的情况便无能为力了。
while((childpid = wait()) !=-1)
continue;
if(errno != ECHILD)
exit(0);系统调用wait()存在很多限制,因而采用waitpid()来代替;
#include
pid_t waitpid(pid_t pid, int *status, int options); waitpid()和wait()的返回值以及参数status的意义相同:
1.pid > 0,表示等待进程ID为pid的子进程。
2.pid = 0,则等待调用进程(父进程)同一个进程组的所有子进程。
3.pid < 0, 等待进程组标识符与pid绝对值相等的所有子进程。
4.pid = -1, 等待任意子进程, wait(&status)的调用与waitpid(-1, &status, 0);等价。
options:权限掩码 WUTRACED WCONTINUED WNOHANG
孤儿进程与僵尸进程:
细见相关资料。
exec()家族:

代码演示,因为所有的家族都有execve()遗传而来:且execve()使用最为灵活简便:
threaderr.c
这是被execv()替换的代码, 且与exec.c存在同一目录下
下面将单独运行这个代码:
/*****************************************************
copyright (C), 2014-2015, Lighting Studio. Co., Ltd.
File name:
Author:Jerey_Jobs Version:0.1 Date:
Description:
Funcion List:
*****************************************************/
#include
#include
#include
int val = 0;
pthread_mutex_t mtx;
static void *thread_fun(void *);
int main(int ac, char *av[])
{
int ret;
pthread_t thid1, thid2;
int loops;
if(ac != 2)
{
printf("参数太多或太少\n");
return (-1);
}
else{
loops = atoi(av[1]);
}
if((ret = pthread_create(&thid1, NULL, thread_fun, &loops)) != 0)
{
perror("线程1创建失败");
exit(-1);
}
if((ret = pthread_create(&thid2, NULL, thread_fun, &loops)) != 0)
{
perror("线程2创建失败");
exit(-1);
}
if((ret = pthread_join(thid1, NULL)) != 0)
{
perror("等待线程1失败");
exit(-1);
}
if((ret = pthread_join(thid2, NULL)) != 0)
{
perror("等待线程2失败");
exit(-1);
}
printf("全局变量的值为:%d\n", val);
return 0;
}
static void *thread_fun(void *arg)
{
int i, loops = *(int *)arg;
int loc;
printf("我的线程ID是%lu\n", pthread_self());
for(i = 0 ; i < loops; i++)
{
pthread_mutex_lock(&mtx);
loc = val;
loc++;
val = loc;
pthread_mutex_unlock(&mtx);
}
return NULL;
}

以上代码说明这个是可以被运行的,我们在execve.c中系统调用execve()来看看效果如何
exec.c
/*****************************************************
copyright (C), 2014-2015, Lighting Studio. Co., Ltd.
File name:
Author:Jerey_Jobs Version:0.1 Date:
Description:
Funcion List:
*****************************************************/
#include
#include
#include
#include
#include
#include
int main(int ac, char *av[])
{
pid_t pid;
char *argv[3];
if(ac != 2)
{
printf("参数太少,请退出重试\n");
exit(-1);
}
strcpy(argv[1], av[1]);
argv[0] = "threaderr"; argv[2] = NULL;
if((pid = fork()) < 0)
{
perror("fork");
return (-1);
}
else if(pid)
{
printf("我是父进程ID是:%u\n", getpid());
printf("父进程等待子进程执行完毕!\n\n");
sleep(2);
waitpid(pid, NULL, WNOHANG);
}
else
{
printf("我是子进程\n");
printf("子进程ID是:%u, 我的父进程ID是%u\n", getpid(), getppid());
printf("我的用户识别ID是:%u, 我的用户组识别ID是%u\n", getuid(), getgid());
printf("子进程即将执行其他程序:threaderr程序\n\n");
//sleep(2);
execve("./threaderr", argv, NULL);
printf("我永远都不会执行到这句话\n");
}
return 0;
}
运行结果如下:

可以看到 并作证exec()函数调用惯例:将新程序加载到某一个进程的内存空间。在这一个操作中将丢弃旧的所有文本段,而进程的栈段、数据段、堆段会被行的程序的相应部件所替换。有fork()生成的子进程对execve()的调用最为频繁,不以fork()调用为先导而单独调用execve()的做法较为罕见。
参考书籍:《The Linux Programming Interface》