决策树模型结构 信息增益与信息增益率
1.决策树模型结构
决策树算法是一种监督学习算法;
决策树是一个类似流程图的树结构:每个内部节点(分支节点/树枝节点)表示一个特征或属性,每个树叶节点代表一个分类;
构造决策树的基本算法:
(1) ID3算法:使用信息增益进行特征选择。
(2)C4.5算法:使用信息增益率进行特征选择,克服了信息增益选择特征的时候偏向于特征个数较多的不足。
(3)CART算法:分类回归树,既可以用于分类,也可以用于预测。利用 CART 构建回归树用到树的 剪枝技术,用于防止树的过拟合。
2.信息增益与信息增益率
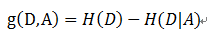 信息增益本质:使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。
信息增益本质:使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。
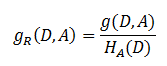 信息增益比本质: 是在信息增益的基础之上乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。
信息增益比本质: 是在信息增益的基础之上乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。
3.ID3算法优缺点
当特征的取值较多时,根据此特征划分更容易得到纯度更高的子集,因此划分之后的熵更低,由于划分前的熵是一定的,因此信息增益更大,因此信息增益比较 偏向取值较多的特征。
4.C4.5算法优缺点
当特征取值较少时HA(D)的值较小,因此其倒数较大,因而信息增益比较大。因而偏向取值较少的特征。
5.C4.5算法在ID3算法上有什么提升
信息增益率改进由于信息增益偏向特征取值较多的不足之处
使用信息增益率进一步划分决策树
6.C4.5算法在连续值上的处理
-
对特征的取值进行升序排序 -
两个特征取值之间的中点作为可能的分裂点,将数据集分成两部分,计算每个可能的分裂点的信息增益(InforGain)。优化算法就是只计算分类属性发生改变的那些特征取值。 -
选择修正后信息增益(InforGain)最大的分裂点作为该特征的最佳分裂点 -
计算最佳分裂点的信息增益率(Gain Ratio)作为特征的Gain Ratio。注意,此处需对最佳分裂点的信息增益进行修正:减去log2(N-1)/|D|(N是连续特征的取值个数,D是训练数据数目,此修正的原因在于:当离散属性和连续属性并存时,C4.5算法倾向于选择连续特征做最佳树分裂点)
7.划分数据集代码
#通过调用sklearn.model_selection.train_test_split按比例划分训练集和测试集
import numpy as np
from sklearn.model_selection import train_test_split
X, Y = np.arange(10).reshape((5, 2)), range(5)
print("X=", X)
print("Y=", Y)
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=0.30, random_state=42)
print("X_train=", X_train)
print("X_test=", X_test)
print("Y_train=", Y_train)
print("Y_test=", Y_test)
#其中test_size=0.30表示T占30%, 那么S占70%。运行结果:
X= [[0 1]
[2 3]
[4 5]
[6 7]
[8 9]]
Y= range(0, 5)
X_train= [[4 5]
[0 1]
[6 7]]
X_test= [[2 3]
[8 9]]
Y_train= [2, 0, 3]
Y_test= [1, 4]
#通过调用sklearn.model_selection.KFold按k折交叉划分训练集和测试集
import numpy as np
from sklearn.model_selection import KFold
X= np.arange(10).reshape((5, 2))
print("X=", X)
kf = KFold(n_splits=2)
for train_index, test_index in kf.split(X):
print('X_train:%s ' % X[train_index])
print('X_test: %s ' % X[test_index])
#其中n_splits=2表示k=2。运行结果:
X= [[0 1]
[2 3]
[4 5]
[6 7]
[8 9]]
X_train:[[6 7]
[8 9]]
X_test: [[0 1]
[2 3]
[4 5]]
X_train:[[0 1]
[2 3]
[4 5]]
X_test: [[6 7]
[8 9]]
8.创建决策树的代码
#导入模块
from math import log
import operator
# 创建简单的数据集
def createDataSet():
dataSet = [[1,1,0,'fight'],[1,0,1,'fight'],[1,0,1,'fight'],
[1,0,1,'fight'],[0,0,1,'run'],[0,1,0,'fight'],
[0,1,1,'run']]
lables = ['weapon','bullet','blood']
return dataSet,lables
#计算数据集的香农熵,分两步,第一步计算频率,第二部根据公式计算香农熵
def calcShannonEnt(dataSet):#输入训练数据集
numEntries = len(dataSet)#计算训练数据集中样例的数量
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]#获取数据集的标签
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1 #当前标签实例数+1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob *log(prob,2)#计算信息熵
return shannonEnt
#按照给定特征划分数据集
def splitDataSet(dataSet,axis,value):#划分属性,获得去掉axis位置的属性value剩下的样本
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value :
reduceFeatVec = featVec[:axis]
reduceFeatVec.extend(featVec[axis+1:])#extend()方法接受一个列表作为参数,并将该参数的每个元素都添加到原有的列表中
retDataSet.append(reduceFeatVec)#append()方法向列表的尾部添加一个新的元素,只接受一个参数。
return retDataSet
#选择最好的数据集划分方式
def chooseBestFeatureToSplit(dataSet):#选择最好的特征
numFeatures = len(dataSet[0])-1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)#将特征值放到一个集合中,消除重复的特征值
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy#计算信息增益
if(infoGain>bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def mahorityCnt(classList):#计算最大所属类别
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCount[vote]+=1
sortedClassCount = sorted(classCount.items(),key=operator.getitem(1),reverse=True)
return sortedClassCount[0][0]
#基于递归构建决策树
def createTree(dataSet,labels):#构建分类树
classList = [example[-1] for example in dataSet]#获得类别列
if classList.count(classList[0]) == len(classList):#所有样本属于同一类别
return classList[0]
if len(dataSet[0])==1:#只有类别列,没有属性列
return mahorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)#获得最优属性下标
bestFeatLabel = labels[bestFeat]#获得最优属性
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])#删除最优属性
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels)#递归计算分类树
return myTree
data,label = createDataSet()
myTree = createTree(data,label)
print myTree