nginx 是现代 Web 服务栈中最重要的组件之一,绝大部分互联网公司都会通过分析监控 nginx 日志来定位业务性能瓶颈和故障诊断等。

通常,如果想构建一套具有实时数据监控、日志搜索和分析功能的大数据平台:首先需要选择数据收集工具,如目前比较流行的 logstash(filebeat)、fluntd、flume 等;然后依托 Prometheus 或 InfluxDB 实现数据的实时监控,并结合可视化工具(如 Grafana )实现数据的可视化展示;与此同时,为了达到高效日志搜索的目的,还需要运用 Elasticsearch 技术搭建搜索和分析引擎,并结合 Kibana 进行页面展示。而实现以上功能不仅需要有资深大数据背景的技术团队和漫长的开发周期,上线后还要投入精力持续维护迭代。当数据量持续上升时,还需要考虑横向扩展能力,否则就不得不面对众多开源组件崩盘的风险。
七牛大数据平台 Pandora 是一套面向海量数据,能够让基础技术人员轻松管理大数据传输、计算、存储和分析的大数据 PaaS 平台,核心服务及功能包括大数据工作流引擎、时序数据库、日志检索服务、Spark 服务、报表工作室。
基于七牛大数据平台 Pandora,不到 10 分钟就可以完全实现一套可承载海量数据的 nginx 日志分析与报警平台,无需考虑部署运维难题,更有海量离线数据分析等众多大数据分析工具支持。
以下是操作详情
系统功能要求
- 海量数据支撑
- 快速接入,无侵入式配置,快速部署使用
- 多种类型分析、分词、加工、变换
- 实时监控,数据可视化( Grafana 用户无障碍迁移)
- 离线分析,发现数据更大价值
- 计算结果导出到用户自身,快速回流
监控内容
nginx 的访问日志( access.log )
快速开始
1、数据接入
根据您机器的操作系统版本下载 logkit( logkit 是七牛云推出的一款开源数据收集工具)
下载地址:https://github.com/qiniu/logkit/wiki/Download
解压后您可以看到:
logkit
logkit.conf
confs/default.conf
其中 logkit.conf 为主配置文件,用于配置监听的子配置文件夹,修改主配置文件需要重启 logkit。
您需要将其中的 confs_path 地址设置要监听的子配置文件夹路径。confs 文 件夹就是一个示例的子配置文件夹,子配置文件的更新无需重启 logkit,会被 logkit 实时监听,我们在子配置文件中设置实际要收集的各种配置文件。
下面我们将为您介绍如何配置子配置文件以收集 nginx 的日志。
明确本机的 nginx 配置文件 log_format 位置如图 1

假设该配置文件路径为: /opt/nginx_logs/logs/access.log
明确服务使用的 nginx 日志样式,如图 2
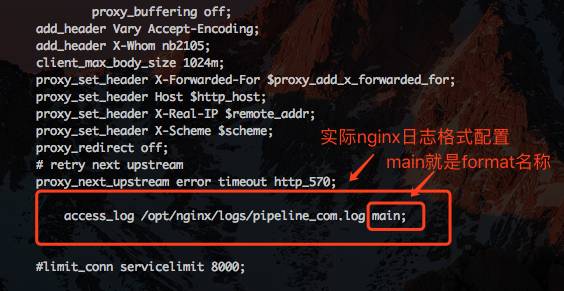
假设我们使用的 nginx 日志样式为 main
根据我们明确的 nginx 配置文件,填写 nginx 日志收集的 logkit 配置文件,如图 3,填写内容覆盖到 confs/default.conf 即可
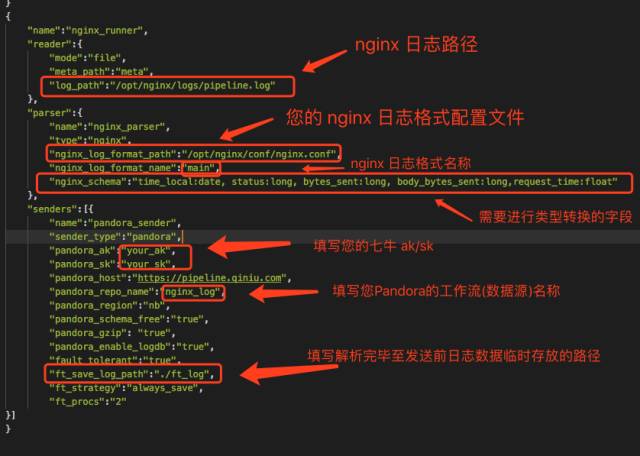
{
"name":"nginx_runner",
"reader":{
"mode":"file",
"meta_path":"meta",
"log_path":"/opt/nginx_logs/logs/access.log"
},
"parser":{
"name":"nginx_parser",
"type":"nginx",
"nginx_log_format_path":"/opt/nginx/conf/nginx.conf",
"nginx_log_format_name":"main",
"nginx_schema":"time_local date,bytes_sent long,request_timefloat,body_bytes_sent long",
"labels":"machine {machineNumber},team {opTeam}"
},
"senders":[{
"name":"pandora_sender",
"sender_type":"pandora",
"pandora_ak":"your_ak",
"pandora_sk":"your_sk",
"pandora_host":"https://pipeline.qiniu.com",
"pandora_repo_name":"my_nginx_log",
"pandora_region":"nb",
"pandora_schema_free":"true",
"pandora_gzip": "true",
"pandora_enable_logdb":"true",
"fault_tolerant":"true",
"ft_save_log_path":"./ft_log",
"ft_strategy":"always_save",
"ft_procs":"2"
}]
}
除了 nginx 日志,logkit 还支持收集其他日志,更多 logkit 的高级用法,参见 logkit wiki文档
运行 logkit
nohup ./logkit -f logkit.conf > logkit.log 2>&1
2、数据加工
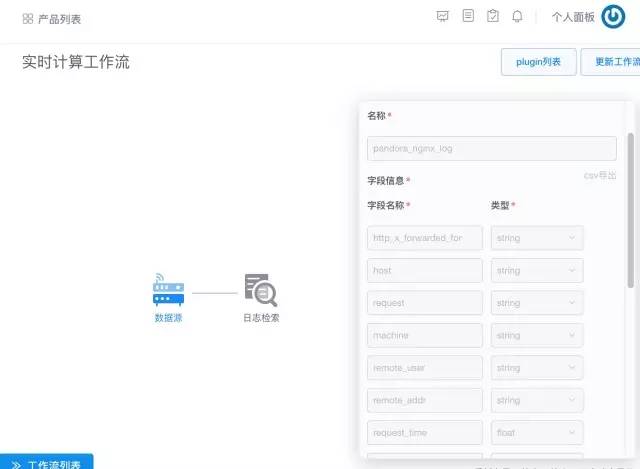
登录七牛官方网站,在大数据工作流引擎中即可看到已经创建的数据传输通道,如图 4
在日志检索界面查询数据,如图 5-1 所示

至此,您已经可以通过搜索玩转您本地的数据啦。
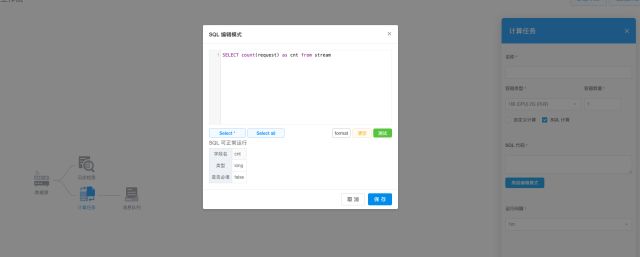
除了默认导出一份到日志检索之外,您也可以回到大数据工作流引擎,根据您的需要任意创建针对实时数据流的自定义计算并导出,如图 5-2 所示。
经过多种实时计算变换的数据,除了导出到 Pandora 已有的日志检索、时序数据库以及对象存储以外,还可以根据需要,导出到您本地假设的 http 服务器上,即在 Pandora 进行数据计算后将结果回流到您的平台落地,如图 5-3 所示。

当然,导出到对象存储的数据,还可以在工作流引擎中创建离线计算工作流,再次进行数据加工聚合计算并导出,如图 5-4 所示。

在离线计算的工作流引擎,你可以根据需要周期性的运行您的计算任务,如定时分析一天的数据、一周的数据,出一份日报、周报等。
3、实时数据展示与监控
我们提供创建并配置 Grafana 进行监控。
创建 Grafana App,如图 6 所示
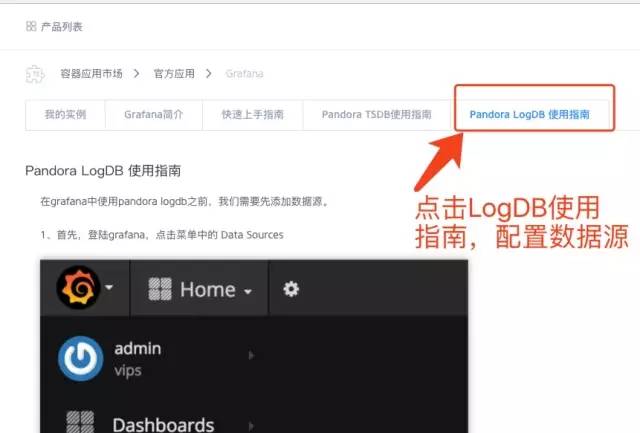
配置 Grafana LogDB 数据源,如图 7 所示,点击 logdb 使用指南,可以按照使用指南的指导在 Grafana 配置数据源。
注意事项
Default Query Settings中, Group by interval 填写时间 10s,注意单位为 s, m 等,不能漏掉,必须小写。
Time Field Name 处填写您的 logdb 时间字段, 填您 nginx 配置的命名,在上述的截图示例中,是 time_local , 没有默认的 $ 符号
Index name中,模式固定为 Daily , 串固定为 [reponame-]YYYY.MM.DD , 将reponame 字符串改为您的数据源名称即可。
Version 固定为 2.x
载入现成的 Grafana 配置
下载 json http://op26gaeek.bkt.clouddn.com/logdbgrafana.json在 Grafana 界面导入 json,并选择数据源。最终您将看到的效果,如图 8-1 所示
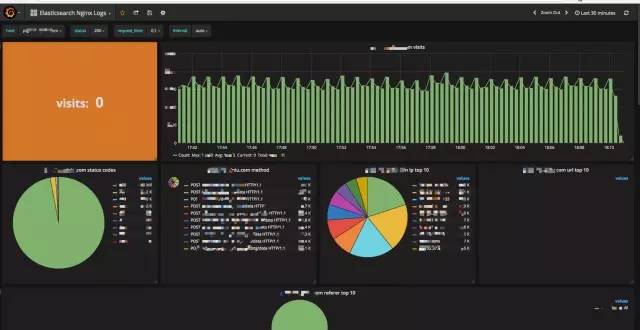
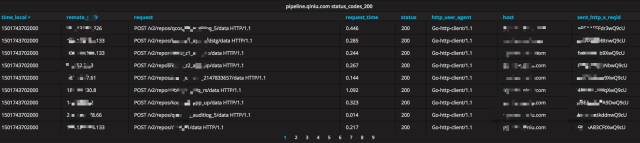
仅仅以 nginx 日志为例,您可以看到哪些十分有价值的数据呢?实时总用户访问量(请求数统计),如图 8-2 所示

机器请求数随时间变化趋势,如图 8-3 所示

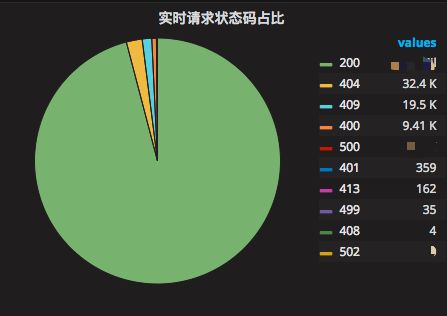
实时请求状态码占比,如图 8-4 所示
实时请求 TOP 排名,如图 8-5 所示

实时请求来源 IP TOP 排名,如图 8-6 所示

响应时间随时间变化趋势图,如图 8-7 所示

实时用户请求的客户端 TOP 排名,如图 8-8 所示

实时根据不同情况进行具体数据的查询,包括状态码、响应时间范围进行筛选等,如图 8-9 所示
其他更多自定义配置...自定义的 Grafana DashBoard 配置示例,如图 9 所示
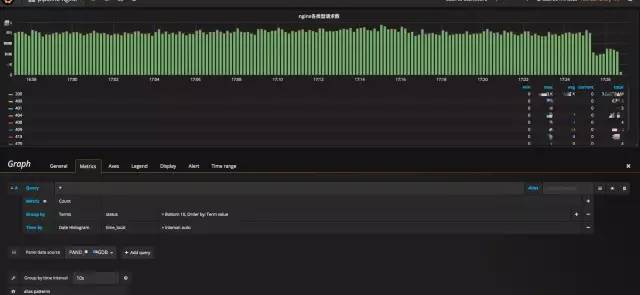
在此,您可以通过 Grafana,通过您的 nginx 日志完整而详尽地了解您业务的流量入口的各类情况。
报警
除此之外,我们还为您创建的 Grafana 提供了完善多样的报警功能。
首先设置下 Grafana 报警的 Channel,如图 10 所示。

点击 New Channel 按钮,您可以在 Type 那边选择包括 Slack, Email 邮箱,Webhook 等十来种报警方式。
设置好报警的 Channel 以后,回到 Dashboard 界面,您就可以愉快的设置报警啦。比如说如图 11,我们设置了一个响应时间大于 1000ms 的报警
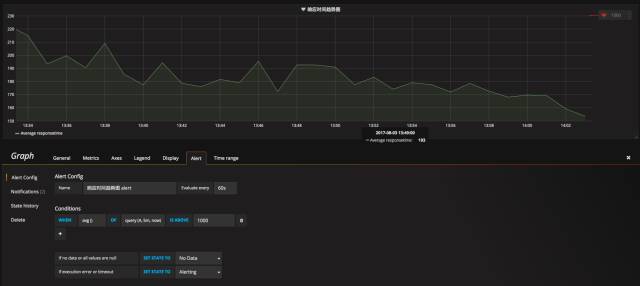
LogDB 采用的是基于 Elasticsearch 协议的报警,这个 Grafana 的功能是七牛独家哦!
那么您可以看到报警形式是怎么样的呢?

看到图 12 Slack 上的报警了吗?除了基本的文字,还会带上酷炫的报警图片!图片都会被存储到您七牛云存储的 bucket( grafana-alert-images ) 里面!

邮件报警内容也一样酷炫!
离线分析
除了实时的分析外,您还可以创建离线的XSpark,分析更多更久的海量数据,详见 [XSpark使用入门](https://qiniu.github.io/pandora-docs/#/quickstart/xspark)。
目前七牛大数据平台 Pandora 处于有限开放阶段,点击「阅读原文」,提交表单即可申请试用。