【JAVA高薪之路 面试题精选】Map类面试题
知识结构及题目分析
一般而言,Map 的面试题可分为四类:
1、HashMap 的数据结构,面试官考察的是对 Map 内部的存储结构了解;
2、HashMap 的增删查改操作,面试官考察的是对 map 内部操作流程的熟悉程度,既要知其然,还要知其所以然;
3、HashMap 的的应用,面试官考察的是灵活运用 HashMap 的能力;
4、其他 Map 类面试题,面试官考察的是系统掌握 Map 类的能力。
典型例题及思路分析
问题 1:"那你知道 HashMap 内部的数据结构吗?"
参考答案:
各个版本的实现略有不同。JDK1.7 及以前的 HashMap 采用数组 + 链表的结构来存储数据; JDK8 中的 HashMap 采用了数组 + 链表+红黑树来存储数据。
问题 2:"Hashmap的内部结构,1.7和1.8有哪些区别?”
参考答案:
(1)JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法,那么他们为什么要这样做呢?因为JDK1.7是用单链表进行的纵向延伸,当采用头插法时会容易出现逆序且环形链表死循环问题。但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。具体可参考:https://coolshell.cn/articles/9606.html
(2)扩容后数据存储位置的计算方式也不一样:
在JDK1.7的时候是直接用hash值和需要扩容的二进制数进行&(这里就是为什么扩容的时候为啥一定必须是2的多少次幂的原因所在,因为如果只有2的n次幂的情况时最后一位二进制数才一定是1,这样能最大程度减少hash碰撞)(hash值 & length-1)
而在JDK1.8的时候直接用了JDK1.7的时候计算的规律,也就是扩容前的原始位置+扩容的大小值=JDK1.8的计算方式,而不再是JDK1.7的那种异或的方法。但是这种方式就相当于只需要判断Hash值的新增参与运算的位是0还是1就直接迅速计算出了扩容后的储存方式。
具体流程:https://blog.csdn.net/qq_36520235/article/details/82417949
(3)JDK1.7的时候使用的是数组+ 单链表的数据结构。但是在JDK1.8及之后时,使用的是数组+链表+红黑树的数据结构(当链表的深度达到8的时候,也就是默认阈值,就会自动扩容把链表转成红黑树的数据结构来把时间复杂度从O(n)变成O(logN)提高了效率)
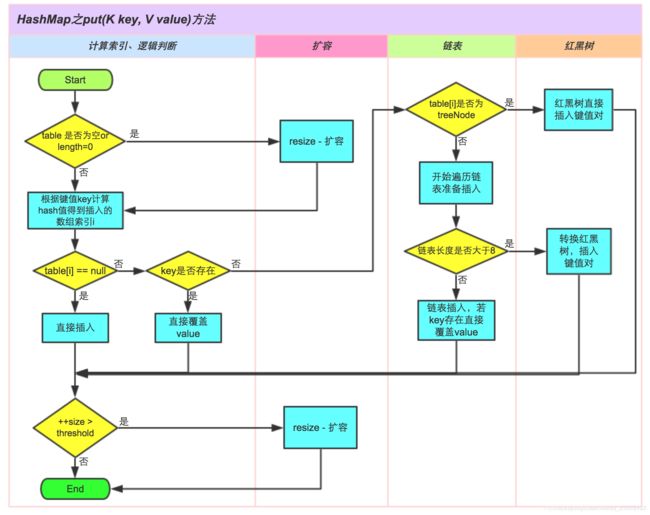
问题 3:“HashMap 的存储数据的过程是什么样的?”
参考答案:
不同的 JDK 版本版本的存储过程略有差异。在 JDK1.8 中,HashMap 存储数据的过程可以分为以下几步:
-
通过 key 的 hashCode ()经过扰动函数处理过后得到 hash 值;
-
对当前数组是否为NULL做判断,若为空,则进行容量初始化,初始容量为16
-
若不为空,通过 (n - 1) & hash 计算对应数组索引,如果 hash 计算后没有碰撞,直接放到对应数组下标里;
-
若 hash 计算后发生碰撞且Key已经存在,则覆盖原来的value;
-
若 hash 计算后发生碰撞且节点已经是红黑树,则直接插入红黑树。
6 . 若hash 计算后发生碰撞且节点是链表结构,遍历链表,判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
. 插入成功后,判断实际存在的键值对数量size是否超多了最大键值对容量threshold,如果超过,进行扩容。
而在 1.7 的版本中,5/6 是合在一起的,即如果发生哈希碰撞且节点是链表结构,则放在链表头
问题 4:"如果 hashCode 相同,如何获取对象呢?"
参考答案:
hashCode 相同,说明这些对象的数据都在同一个数组下标对应的链表或者树上。get 方法的签名是 V get (Object key) ,入参只有一个 key,因此通过遍链表或者树,取出每一个节点对比 hash 值是否相等且 key 是否相等 (= 或者 equals)。
问题 5:HashMap 和 HashTable 有什么区别?
参考答案:
1.HashMap 是线程不安全的,HashTable 是线程安全的。
2.HashMap 的键需要重新计算对象的 hash 值,而 HashTable 直接使用对象的 hashCode。
3.HashMap 的值和键都可以为 null,HashTable 的值和键都不能为 null。
4.HashMap 的数组的默认初始化大小为 16,HashTable 为 11;HashMap 扩容时会扩大两倍,HashTable 扩大两倍 + 1.
问题6:HashMap 的长度为什么是2的幂次方?
参考答案:
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀,我们首先可能会想到采用%取余的操作来实现。但是,重点来了:“取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)。” 并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是2的幂次方
问题7:HashMap 初始容量设置为 10000 时,放入 10000 条数据是否需要扩容;如果初始容量设置为 1000 时,放入 1000 条数据是否需要扩容?
参考答案:
初始容量设置为10000时,hashMap会将容量调整至16384(2的n次方),由于hashMap默认的加载因子为0.75,放入10000条数据时并没有达到需要扩容的阈值,所以不会扩容。 同理初始容量为1000时,hashMap会将容量调整到1024,当插入到第768条数据即到达扩容阈值,此时hashMap会进行扩容,容量为原先的两倍即2048
问题 8:“HashMap 和 ConcurrentHashMap 的区别?”
参考答案:
基础特性不同:
HashMap 的 key 和 value 可以为 null,ConcurrentHashMap 的 key 和 value 不能为 nul
内部数据结构不同:
HashMap 在 JDK1.7 中采用的数据结构是数组 + 链表,在 JDK1.8 中采用的数据结构是数组 + 链表 + 红黑二叉树;
ConcurrentHashMap 在 JDK1.7 中采用的数据结构是分段的数组 + 链表,JDK1.8 的内部数据结构采用的数据结构是数组 + 链表 +红黑二叉树(同 HashMap 一致)。
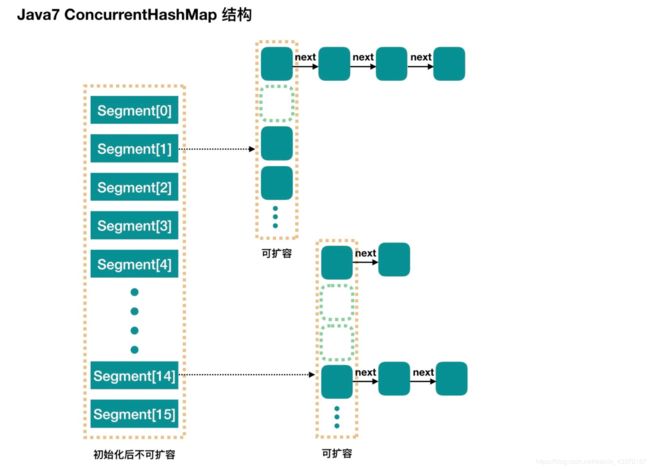
图 1 JDK1.7 中 ConcurrentHashMap 的结构
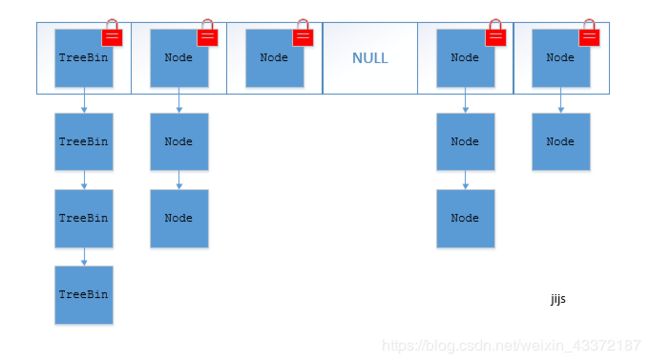
图 2 JDK1.8 中 ConcurrentHashMap 的结构
线程安全不同:
HashMap 是非线程安全的;
ConcurrentHashMap 是线程安全的
问题9:ConcurrentHashMap 和 Hashtable 的区别?
底层数据结构上: JDK1.7的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表+红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
实现线程安全的方式(重要):
① 在JDK1.7的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;
② Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。

问题10:ConcurrentHashMap的put方法怎样实现?
参考答案:
不同的版本put方法实现不同。
JDK1.7:当执行put方法插入数据时,根据key的hash值,在Segment数组中找到相应的位置,如果相应位置的Segment还未初始化,则通过CAS进行赋值,接着执行Segment对象的put方法通过加锁机制插入数据,实现如下:
场景:线程A和线程B同时执行相同Segment对象的put方法
1、线程A执行tryLock()方法成功获取锁,则把HashEntry对象插入到相应的位置;
2、线程B获取锁失败,则执行scanAndLockForPut()方法,在scanAndLockForPut方法中,会通过重复执行tryLock()方法尝试获取锁,在多处理器环境下,重复次数为64,单处理器重复次数为1,当执行tryLock()方法的次数超过上限时,则执行lock()方法挂起线程B;
3、当线程A执行完插入操作时,会通过unlock()方法释放锁,接着唤醒线程B继续执行;
JDK1.8:
1.key或value是否为空,是的话,抛异常new NullPointerException();
2.table是否为空或length==0;是的话,初始化table;
3.根据key算出的hash值,从table中拿出table[hash]值,为空则添加,否则判断此值的hash值,如果table[hash].hash=-1,说明此时有线程扩容此链表,你需要去帮忙扩容。
4.table[hash].hash>=0,锁住table[hash],表示锁住此索引的所有链表或红黑树。判断是key是否重复,重复的话就更新value,判断是不是红黑树,是的话树插入,否者链表尾插入法,更新。
5.最后,插入后判断链表的节点数是否大于8,是的话,转换为红黑树,
6.最后判断concurrentHashMap容量,大于扩容值,就进行扩容。
参考链接:https://www.jianshu.com/p/e694f1e868ec