原文地址:https://xilidou.com/2018/03/15/redis-object/
前两篇文章介绍了 Redis 的基本数据结构动态字符串,链表,字典,跳跃表,压缩链表,整数集合,但是使用过 Redis 的同学会发现,平时根本没有使用过这些数据结构。 平时使用的数据结构,包括字符串,列表,哈希,集合,还有有序集合。 其实 Redis 的实现是将底层的一种或者几种数据结构进行结合成我们使用的数据结构。
所以今天这篇文章就是要解释 Redis 是怎么实现符串,列表,哈希,集合,还有有序集合的。
对象
对于 Redis 来说使用了 redisObject 来对所有的对象进行了封装:
typedef struct redisObject {
// 对象类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 对象最后一次被访问的时间
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
// 引用计数
int refcount;
// 指向实际值的指针
void *ptr;
} robj;
我们先关注两个参数
type 和 encoding :
/* Object types */
// 对象类型
#define REDIS_STRING 0
#define REDIS_LIST 1
#define REDIS_SET 2
#define REDIS_ZSET 3
#define REDIS_HASH 4
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
// 对象编码
#define REDIS_ENCODING_RAW 0 /* Raw representation */
#define REDIS_ENCODING_INT 1 /* Encoded as integer */
#define REDIS_ENCODING_HT 2 /* Encoded as hash table */
#define REDIS_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define REDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
#define REDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define REDIS_ENCODING_INTSET 6 /* E dncoded as intset */
#define REDIS_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define REDIS_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
所以通过这段代码我们可以知道 Redis 支持的数据类型如下:
| type | 类型 |
|---|---|
| REDIS_STRING | 字符串 |
| REDIS_LIST | 列表 |
| REDIS_SET | 集合 |
| REDIS_ZSET | 有序集合 |
| REDIS_HASH | 哈希表 |
Redis 的 Object 通过 ptr 指向具体的底层数据。Redis 的底层数据:
| 编码 | 类型 |
|---|---|
| REDIS_ENCODING_RAW | SDS 实现的动态字符串对象 |
| REDIS_ENCODING_INT | 整数实现的动态字符串对象 |
| REDIS_ENCODING_HT | 字典实现的 hash 对象 |
| REDIS_ENCODING_ZIPMAP | 压缩map实现对对象,(3.0)版本未使用 |
| REDIS_ENCODING_LINKEDLIST | 双向链表实现的对象 |
| REDIS_ENCODING_ZIPLIST | 压缩列表实现的对象 |
| REDIS_ENCODING_INTSET | 整数集合实现的对象 |
| REDIS_ENCODING_SKIPLIST | 跳跃表实现的对象 |
| REDIS_ENCODING_EMBSTR | 使用 embstr 实现的动态字符串的对象 |
PS:下文会解释 RAW 和 EMBSTR 的区别。
我就按照类型的顺序看看 Redis 是怎么利用底层的数据结构实现不同的对象类型的。
REDIS_STRING (字符串)
Redis 的字符串 String,主要由 int、raw 和 emstr 底层数据实现的。 Redis 遵循以下的原则来决定使用底层数据结构的使用。
- 如果数据是可以用 long 表示的整数,那就直接使用将ptr 的类型设置为long。将RedisObject 的 encoding 设置为 REDIS_ENCODING_INT。
- 如果是一个字符串,那就需要考察字符串的字节数。如果字节数小于 39 就是使用 emstr,encoding 就使用 REDIS_ENCODING_EMBSTR,底层依然是我们之前介绍的 SDS 。
- 如果字符串的长度超过 39 那就使用 raw,encoding 就是 REDIS_ENCODING_RAW。
问题来了:
- 为什么是 39 个字符?
我们所String对象是由一个 RedisObject 和 sdshdr 组成的。所以我们如下公式在
在64位的系统中,一个 emstr 最大占用 64bite。
RedisObject(16b) + sds header(8b) + emstr + “\0”(1b) <= 64
简单的 四则运算 emstr <= 39。 - 一直都是 39 么?
在 3.2 的版本的时候,作者对 sdshdr 做了修改,从 39 改成了 44。为什么?
之前我们说过一个 sdshdr 包含三个参数,len、free还有buf,在3.2之前 len 和 free 的数据类型都是 unsigned int。 这个就是为什么上面的公式 sds header 是 8个字节了。新版本的 sdshdr 变成了 sdshdr8, sdshdr16 和 sdshdr32还有 sdshdr64。优化的地方就在于如果 buf 小,使用更小位数的数据类型来描述 len 和 free 减少他们占用的内存,同时增加了一个char flags。emstr使用了最小的 sdshdr8。 这个时候 sds header 就变成了(len(1b) + free(1b) + flags(1b)) 3个字节, 比之前的实现少了5个字节。 所以新版本的 emstr 的最大字节变成了 44。 还是那句话 Redis 对内存真是 “斤斤计较” - SDS 是动态的为什么要区分 emstr 和 raw?
区别在于生产 raw 的时候,会有两步操作,分别产生 redisObject 和 sdshdr。而 emstr 一次成型,同时生成 redisObject 和 sdshdr 。就是为了高效。同时注意 emstr 是不可变的。 - 他们之间是什么关系?
如果不能用 long 表示的数据,double 也是使用 raw 或者 emstr 来保存的。
按照 Redis 的套路这三个底层数据在条件满足的是是会发生装换的。REDIS_ENCODING_INT 的数据如果不是整数了,那就会变成 raw 或者 emstr。emstr 发生了变化就会变成 raw。
REDIS_LIST 列表
Reids 的列表,底层是一个 ziplist 或者 linkedlist。
- 当列表对象保存的字符串元素的长度都小于64字节。
- 保存的元素数量小于512个。
两个条件都满足使用ziplist编码,两个条件任意一个不满足时,ziplist会变为linkedlist。
3.2 以后使用 quicklist 保存。这个数据结构之前没有讲解过。
实际上 quicklist 是 ziplist 和双向链表结合的产物。我们这样理解,每个双向链表的节点上是一个ziplist。之所以这么设计,应该是空间和时间之间的取舍或者一个折中的方案。 具体的实现我会在以后的文章里面具体分析。
REDIS_SET (集合)
Redis 的集合底层是一个 intset 或者 一个字典(hashtable)。
这个比较容易理解:
- 当集合都是整数且不超过512个的时候,就使用intset。
- 剩下都是用字典。
使用字典的时候,字典的每一个 key 就是集合的一个元素,对应的 value 就是一个 null。
REDIS_ZSET (有序集合)
Redis 的有序集合使用 ziplist 或者 skiplist 实现的。
- 元素小于 128 个
- 每个元素长度 小于 64 字节。
同时满足以上条件使用ziplist,否则使用skiplist。
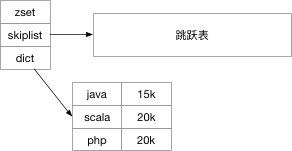
对于 ziplist 的实现,redis 使用相邻的两个 entity 分别保存对象以及对象的排序因子。这样对于插入和查询的复杂度都是 O(n) 的。直接看图:
元素开发工程师,排序的因子就是月薪。(好吧php是世界上最好的语言)。
对于skiplist 的实现:
typedef struct zset{
zskiplist *zsl;
dict *dict
}zset;
skiplist 的有序链表的实现不只是只有一个 skiplist ,还有一个字典存储对象的key 和 排序因子的映射,这个是为了保证按照key 查询的时候时间负责度为 O(1)。同时有序性依赖 skiplist 维护。大家可以看我之前的教程。所以直接看图:
REDIS_HASH (hash表)
Redis 的 hash 表 使用 ziplist 和 字典 实现的。
- 键值对的键和值都小于 64 个字节
- 键值对的数量小于 512。
都满足的时候使用 ziplist,否则使用字典。
ziplist 的实现类似,类似 zset 的实现。两个entity成对出现。一个存储key,另一个存储 velue。
还是可以使用上面使用过的图。这个时候 entity 不用排序。key 是职位名称,velue 是对应的月薪。(好吧php还是世界上最好的语言)。与zset实现的区别就是查询是 O(n) 的,插入直接往tail后面插入就行时间复杂度O(1)。
使用字典实现一个 hash表。好像没有什么可以多说的。
int refcount(引用计数器)
这个参数是引用计数。Redis 自己管理内存,所以就使用了最简单的内存管理方式--引用计数。
- 创建对象的时候计数器为1
- 每被一个地方引用,计数器加一
- 每被取消引用,计数器减一
- 计数器为0的时候,就说明没有地方需要这个对象了。内存就会被 Redis 回收。
unsigned lru:REDIS_LRU_BITS
这个参数记录了对象的最后一次活跃时间。
如果 Redis 开启了淘汰策略,且淘汰的方式是 LRU 的时候,这个参数就派上了用场。Redis 会优先回收 lru 最久的对象。
总结
至此 Redis 的数据结构就介绍完了。
大家可以阅读之前的文章:
Redis 的基础数据结构(一) 可变字符串、链表、字典
Redis 的基础数据结构(二) 整数集合、跳跃表、压缩列表
欢迎关注我的微信公众号:
