模拟登陆并爬取Github
1、准备工作
- 以Github为例实现模拟登陆过程
- 安装好requests库,lxml库
- 完整代码,实现登陆并爬取,简易的见页面末尾
2、分析登陆过程
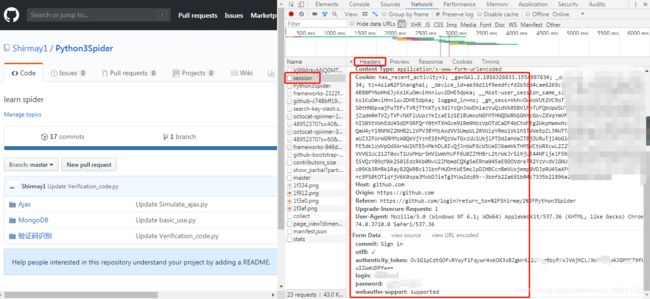
- 分析登陆应该请求的URL为:https://github.com/session ,请求方式为POST
- RequestHeaders包含:Cookies,Host,Origin,Refer,User-Agent等
- FormData包含:commit,utf8,authenticity_token,login,password
- 无法直接构造的内容为Cookies和authenticity_token
3、代码实现方法
- (1)解决Cookies问题,维持一个会话;使用requests中Session对象,可以做到模拟同一个会话不用担心Cookies的问题。
import requests
headers = {
'Host': "github.com",
'Referer': "https://github.com/login?return_to=%2Fjoin",
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3710.0 Safari/537.36"
}
session = requests.Session()
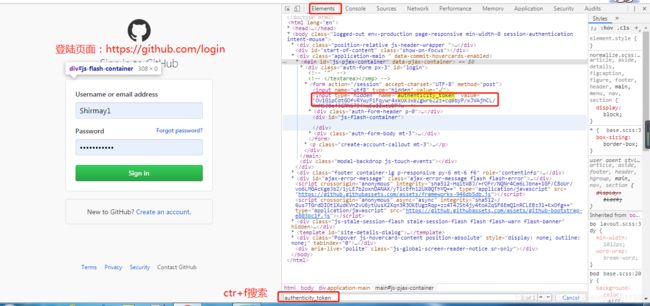
- (2)解决authenticity_token问题,使用Session对象的get()方法访问Github的登陆页面,用Xpath解析网页提取authenticity_token信息, https://github.com/login
import requests
from lxml import etree
headers = {
'Host': "github.com",
'Referer': "https://github.com/login?return_to=%2Fjoin",
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3710.0 Safari/537.36"
}
session = requests.Session()
login_url = 'https://github.com/login'
response = session.get(login_url, headers=headers)
selector = etree.HTML(response.text)
token = selector.xpath('//div//input[2]/@value')[0]
print(token)
import requests
from lxml import etree
headers = {
'Host': "github.com",
'Referer': "https://github.com/login?return_to=%2Fjoin",
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3710.0 Safari/537.36"
}
session = requests.Session()
login_url = 'https://github.com/login'
response = session.get(login_url, headers=headers)
selector = etree.HTML(response.text)
token = selector.xpath('//div//input[2]/@value')[0]
print('authenticity_token为:',token)
post_data = {
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': token,
'login': '你的登陆名称',
'password': '你的密码'
}
post_url = 'https://github.com/session'
response = session.post(post_url, data=post_data, headers=headers)
if response.status_code == 200:
print('登陆成功')
response = session.get('https://github.com/settings/profile', headers=headers)
if response.status_code == 200:
print('访问成功')
selector = etree.HTML(response.text)
name = selector.xpath('//input[@id="user_profile_name"]/@value')
print('我的名称为:',name)
运行结果
authenticity_token为: 1JdIJwLZ9WicKJKDR2SgyAD4O7517bCl3GIqmF/RUArjad1anYrANEu6V2ogmR4wqUzwB5WPBXQr+A==
登陆成功
访问成功
我的名称为: ['Shirmay1']