Python_Pyspider使用
目录
- Pyspider
- 1、Pyspider特点
- 2、Pyspider架构
- (1)Scheduler (调度器)、 Fetcher (抓取器)、 Processer (处理器) 、Monitor (监控器)、Result Worker (结果处理器)
- 3、Pyspider使用
- (1)启动页面使用
- (2)示例代码
- (3)crawl使用
- (5)全局配置
- (6)定时爬取
- (7)项目状态
- (8)删除项目
Pyspider
- 官方文档
- 安装与启动
1、Pyspider特点
- (1)用Python编写脚本,可视化地编写和调试爬虫,不用额外的IDE
- (2)功能强大的WebUI,包括脚本编辑器,任务监视器,项目管理器和结果查看器
- (3)支持MySQL,MongoDB,Redis,SQLite,Elasticsearch ; PostgreSQL使用SQLAlchemy作为数据库后端
- (4)支持RabbitMQ,Beanstalk,Redis和Kombu作为消息队列
- (5)提供任务优先级,失败重试,定时定期重新抓取等…
- (6)分布式架构,对接了PhantomJS,可抓取Javascript渲染的页面
- (7)支持单机和分布式部署,支持Docker部署
2、Pyspider架构
(1)Scheduler (调度器)、 Fetcher (抓取器)、 Processer (处理器) 、Monitor (监控器)、Result Worker (结果处理器)
-
pyspider的架构主要分为 Scheduler (调度器)、 Fetcher (抓取器)、 Processer (处理器) 三个部分,整个爬取过程受到 Monitor (监控器)的监控,抓取的结果被 Result Worker (结果处理器)处理。
-
A、Scheduler 发起任务调度, Fetcher 负责抓取网页内容, Processer 负责解析网页内容,然后将新生成的 Request发给 Scheduler进行调度,将生成的提取结果输出保存。
-
B、每个pyspider 的项目对应一 Python脚本,该脚本中定义了一个 Handler 类,它有一个on_start()方法。 爬取首先调用 on_start()方法生成最初的抓取任务,然后发送给 Scheduler进行调度 。
-
C、Scheduler将抓取任务分发给 Fetcher进行抓取, Fetcher执行并得到响应,随后将响应发送给Processer。
-
D、Processer 处理响应并提取 H-’,新的 URL 生成新的抓取任务,然后通过消息队列的方式通知Schduler 当前抓取任务执行情况,并将新生成的抓取任务发送给 Scheduler。 如果生成了新的提取结果,则将其发送到结果队列等待 ResultWorker理。
-
E、Scheduler 接收到新的抓取任务,然后查询数据库,判断其如果是新的抓取任务或者是需要重试的任务就继续进行调度,然后将其发送回 Fetcher进行抓取。
-
F、不断重复以上工作,直到所有的任务都执行完毕,抓取结束 。
-
G、抓取结束后,程序会回调 on_finished()方法,这里可以定义后处理过程。
-
(2)启动界面:http://localhost:5000/
-
(3)创建项目后案例操作介绍
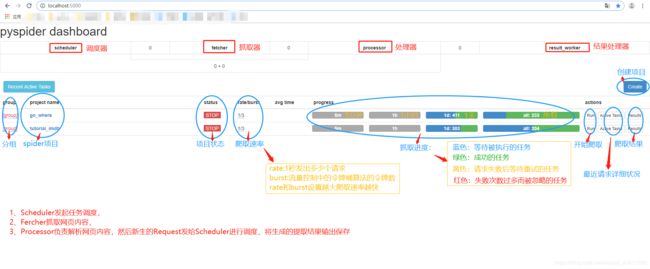
3、Pyspider使用
(1)启动页面使用
- 启动页面使用
(2)示例代码
- 这里的 Handler 就是 pyspider 爬虫的主类,我们可以在此处定义爬取、解析、存储的逻辑。整个爬虫的功能只需要一个 Handler 即可完成。
- 接下来我们可以看到一个 crawl_config 属性。我们可以将本项目的所有爬取配置统一定义到这里,如定义 Headers、设置代理等,配置之后全局生效。
- 然后,on_start() 方法是爬取入口,初始的爬取请求会在这里产生,该方法通过调用 crawl() 方法即可新建一个爬取请求,第一个参数是爬取的 URL,这里自动替换成我们定义的 URL。crawl() 方法还有一个 callback,它指定了这个页面爬取成功后用哪个方法进行解析,代码中指定为 index_page() 方法,即如果这个 URL 对应的页面爬取成功了,那 Response 将交给 index_page() 方法解析。
- index_page() 方法恰好接收这个 Response 参数,Response 对接了 pyquery。我们直接调用 doc() 方法传入相应的 CSS 选择器,就可以像 pyquery 一样解析此页面,代码中默认是 a[href^=“http”],也就是说该方法解析了页面的所有链接,然后将链接遍历,再次调用了 crawl() 方法生成了新的爬取请求,同时再指定了 callback 为 detail_page,意思是说这些页面爬取成功了就调用 detail_page() 方法解析。这里,index_page() 实现了两个功能,一是将爬取的结果进行解析,二是生成新的爬取请求。
- detail_page() 同样接收 Response 作为参数。detail_page() 抓取的就是详情页的信息,就不会生成新的请求,只对 Response 对象做解析,解析之后将结果以字典的形式返回。当然我们也可以进行后续处理,如将结果保存到数据库。
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://scrapy.org/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
(3)crawl使用
- crawl使用
| 参数 | 解释 | 例子 |
|---|---|---|
| url | 爬取时的 URL,可以定义为单个 URL字符串,也可以定义成 URL列表 | self.crawl(‘http://scrapy.org/’, callback=self.index_page) |
| callback | 回调函数,指定了该 URL对应的响应内容用哪个方法来解析 | self.crawl(‘http://scrapy.org/’, callback=self.index_page) |
| age | 任务的有效时间 。 如果某个任务在有效时间内且已经被执行,则它不会重复执行 | @config(age=10 * 24 * 60 * 60) |
| priority | priority 是爬取任务的优先级,其值默认是 0,priority 的数值越大,对应的请求会越优先被调度 | self.crawl(‘http://www.example.org/233.html’, callback=self.detail_page,priority=1) |
| exetime | exetime参数可以设置定时任务,其值是时间戳,默认是 0,即代表立即执行 | self.crawl(‘http://www.example.org/’, callback=self.callback,exetime=time.time()+30*60) |
| retries | retries 可以定义重试次数,其值默认是 3 | |
| itag | itag 参数设置判定网页是存发生变化的节点值,在爬取时会判定次当前节点是否和上次爬取到的节点相同 。 如果节点相同,则证明页面没有更新,就不会重复爬取 | self.crawl(item.find(‘a’).attr.url, callback=self.detail_page,itag=item.find(’.update-time’).text()) |
| auto recrawl | 当开启时,爬取任务在过期后会重新执行,循环时间即定义的 age 时间长度 | self.crawl(‘http://www.example.org/’, callback=self.callback,age=56060, auto_recrawl=True) |
| method | method是 HTTP请求方式,它默认是 GET。 如果想发起 POST请求,可以将 method设置为 POST | 略 |
| params | 我们可以方便地使用 params 来定义 GET请求参数 | self.crawl(‘http://httpbin.org/get’, callback=self.callback,params={‘a’: 123, ‘b’: ‘c’}) |
| data | data是 POST表单数据。 当请求方式为 POST时,我们可以通过此参数传递表单数据 | self.crawl(‘http://httpbin.org/post’, callback=self.callback,method=‘POST’, data={‘a’: 123, ‘b’: ‘c’}) |
| files | files 是上传的文件,需要指定文件名 | self.crawl(‘http://httpbin.org/post’, callback=self.callback,method=‘POST’, files={field: {filename: ‘content’}} |
| user_agent | 是爬取时使用的user-agent | 略 |
| cookies | cookies 是爬取时使用的 Cookies,为字典格式 | 略 |
| connect timeout | connect timeout是在初始化连接时的最长等待时间,它默认是 20秒 | 略 |
| timeout | timeout 是抓取网页时的最长等待时间,它默认是 120秒 | 略 |
| allow redirects | allow redirects 确定是否自动处理重定向,它默认是 True | 略 |
| validate_cert | 确定是否验证证书,此选项对HTTPS请求有效,默认未True | 略 |
| proxy | proxy是爬取时使用的代理,它支持用户名密码的配置,格式为 | username:password@hostname:port |
| fetch_type | fetch_type开启 PhantomJS渲染 。如果遇到 JavaScript渲染的页面,指定此字段即可实现 PhantomJS的对接,pyspider将会使用 PhantomJS 进行网页的抓取 | self.crawl(‘http://httpbin.org/post’, callback=self.callback, fetch_type=‘js’ |
| js_script | js script 是页面加载完毕后执行的 JavaScript脚本 | self.crawl(‘http://www.example.org/’, callback=self.callback,fetch_type=‘js’, js_script=’’‘function() {window.scrollTo(0,document.body.scrollHeight);return 123; } ‘’’) |
| js_run_at | JavaScript脚本运行的位置,是在页面节点开头还是结尾 , 默认是结尾, 即 document-end | 略 |
| js_viewport_ | js_viewport_width/js_viewport_height是 JavaScript渲染页面时的窗口大小 | 略 |
| load_images | load_images在加载 JavaScript页面时确定是否加载图片,它默认是否False | 略 |
| save | save 参数非常有用,可以在不同的方法之 间传递参数 | 略 |
| cancel | cancel是取消任务,如果一个任务是 ACTIVE状态的, 则需要将 force_update设置为 True | 略 |
| force_ update | 即使任务处于 ACTIVE状态,那也会强制更新状态 | 略 |
######(4)任务id
- 任务id
- pyspider判断两个任务是否是重复使用的是该任务对应的 URL 的 MD5 值作为任务的唯一ID,如果ID 相 同,那么两个任务就会判定为相同,其中一个就不会爬取了 。 很多情况下请求的链接可能是同一个,但是POST的参数不同。可以通过方法覆盖 def get_taskid(self, task),改变这个ID的计算方式来实现不同任务的区分。
# 默认情况下,只有url是md5 -ed作为taskid,以下代码添加data了POST请求作为taskid的一部分。
import json
from pyspider.libs.utils import md5string
def get_taskid(self, task):
return md5string(task['url']+json.dumps(task['fetch'].get('data', '')))
(5)全局配置
- crawl_config来指定全局的配置,配置中的参数会和crawl()方法创建任务时的参数合并。如果要全局配置一个Headers,可以定义如下
class Handler(BaseHandler):
crawl_config = {
'headers': {
'User-Agent': 'GoogleBot',
}
}
(6)定时爬取
- 通过every属性来设置爬取的时间间隔。
# 设置每天执行一次爬取
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://travel.qunar.com/travelbook/list.htm', callback=self.index_page)
注意:在任务的有效时间内爬取不会重复,所以要把任务有效时间设置的比重复时间更短,才可以实现定时爬取。以下代码无法做到每天爬取,任务过期时间为10天,自动爬取时间间隔为1天。当第二次尝试重新爬取的时候,pyspider会监测到此任务尚未过期,便不会执行爬取,需将age设置小于定时时间。
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://travel.qunar.com/travelbook/list.htm', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
pass
(7)项目状态
- 每个项目都有6个状态:分别是TODO、STOP、CHECKING、DEBUG、RUNNING、PAUSE。
- TODO:它是项目刚刚被创建还未实现时的状态
- STOP:如果想停止某项目的抓取,可以将项目的状态设置为STOP
- CHECKING:正在运行的项目被修改后就会变成CHECKING状态,项目在中途出错需要调整的时候会遇到这种情况
- DEBUG/RUNNING:这两个状态对项目的运行没有影响,状态设置为任意一个,项目都可以运行,但是可以用二者来区分项目是否已经测试通过
- PAUSE:当爬取过程中出现连续多次错误时,项目会自动设置为PAUSE状态,并等待一定时间后继续爬取。
(8)删除项目
- pyspider中没有直接删除项目的选项。如果删除任务,那么将项目的状态设置为STOP,将分组的名称设置为delete,等待24小时,则项目会自动删除