HBASE优化
硬件和操作系统调优
1)配置内存
HBase对于内存的消耗是非常大的,主要是其LSM树状结构、缓存机制和日志记录机制决定的,所以物理内存当然是越大越好,并且现在内存的价格已经降到可以批量配置的程度,例如一条三星DDR3、DDR4的16GB内存,价格大约在1000元左右。在互联网领域,服务器内存方面的主流配置已经是64GB,所以一定要根据实际的需求和预算配备服务器内存。如果资源很紧张,推荐内存最小在32GB,如果再小会严重影响HBase集群性能。
2)配置CPU
HBase给使用者的印象可能更偏向于“内存型”NoSQL数据库,从而忽略了CPU方面的需求,其实HBase在某些应
用上对CPU的消耗非常大,例如频繁使用过滤器,因为在过滤器中包含很多匹配、搜索和过滤的操作;多条件组合扫描的场景也是CPU密集型的;压缩操作很频繁等。如果服务器CPU不够强悍,会导致整个集群的负载非常高,很多线程都在阻塞状态(非网络阻塞和死锁的情况)。
一般CPU的品牌有Intel、AMD、IBM,Intel是主流。
现在的服务器支持1、2、3、4、6、8、10路CPU,而每路CPU的核心有双核、四核、六核、八核、十二核。CPU数量和核心数之间可以互相搭配,当然值越大相应的价格越高。建议每台物理节点至少使用双路四核CPU(2×4),主流是2~8路,一般单颗CPU至少四核。一颗四核心CPU,便宜的,价格在1500元左右,还是可以接受的。所以,对于CPU密集型的集群,当然是越多越好。
3)磁盘的配置
如果是机械盘,主要看转速,一般的是7000转。可以考虑用SSD固态硬盘,底层是通过电阻器原件构架的,速度接近于内存。
4)垃圾回收器(GC)的选择
对于运行HBase相关进程JVM的垃圾回收器,不仅仅关注吞吐量,还关注停顿时间,而且两者之间停顿时间更为重要,因为HBase设计的初衷就是解决大规模数据集下实时访问的问题。那么排首位的应该是停顿时间短,从这个方面CMS和G1有着非常大的优势。
而CMS作为JDK1.5就已经出现的垃圾收集器,已经成熟应用在互联网等各个行业。所以,选用CMS作为老年代的垃圾回收器。与CMS搭配的新生代收集器有Serial和ParNew,而对比这两个收集器,明显ParNew具有更好的性能,所以新生代选用ParNew作为垃圾收集器。那么,最终选用的垃圾收集器搭配组合是CMS+ParNew。而且很多成熟应用已经验证了这种组合搭配的优势。
与CMS收集器相关的几个重要参数的具体含义、默认值和相关说明详见下表:
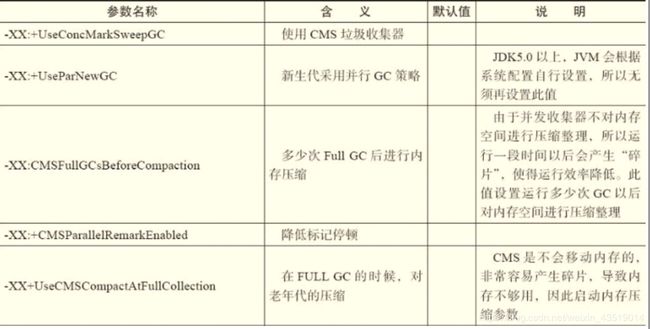
置方式:在hbase-env.sh文件中添加如下参数
export HBASE_OPTS="-XX:+UseConcMarkSweepGC" -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSCompactAtFullCollection
5)JVM堆大小设置
堆内存大小参数也在hbase-env.sh文件中设置,设置的参数如下:
export HBASE_HEAPSIZE=16384
在上面代码中指定堆内存大小是16284,单位是MB,即16GB。当然,这个值需要根据节点实际的物理内存来决
定。一般不要超过实际物理内存的一半(1/2)。
- 服务器内存的分配,比如服务器内存64GB,为操作系统预留出8G-16GB。此外给Yarn留出8G~16GB,如果没有其他框架,把剩余的留给HBase。
Hbase调优
1)调节数据块(data block)的大小
HFile数据块大小可以在列族层次设置。这个数据块不同于之前谈到的HDFS数据块,其默认值是65536字节,或
64KB。数据块索引存储每个HFile数据块的起始键。数据块大小的设置影响数据块索引的大小。数据块越小,索引越大,从而占用更大内存空间。同时加载进内存的数据块越小,随机查找性能更好。但是,如果需要更好的序列扫描性能,那么一次能够加载更多HFile数据进入内存更为合理,这意味着应该将数据块设置为更大的值。相应地,索引变小,将在随机读性能上付出更多的代价。可以在表实例化时设置数据块大小,代码如下:
hbase(main):002:0> create ‘mytable’,{NAME => ‘colfam1’, BLOCKSIZE => ‘65536’}如果mytable表在实际业务中,随机查找业务多,就调小。如果范围查询(顺序扫描)业务多,就调大。
2)适当时机关闭数据块缓存
把数据放进读缓存,并不是一定能够提升性能。如果一个表或表的列族只被顺序化扫描访问或很少被访问,
则Get或Scan操作花费时间长一点是可以接受的。在这种情况下,可以选择关闭列族的缓存。关闭缓存的原因在于:如果只是执行很多顺序化扫描,会多次使用缓存,并且可能会滥用缓存,从而把应该放进缓存获得性能提升的数据给排挤出去。所以如果关闭缓存,不仅可以避免上述情况发生,而且可以让出更多缓存给其他表和同一表的其他列族使用,数据块缓存默认是打开的。
可以在新建表或更改表时关闭数据块缓存属性:
hbase(main):002:0> create ‘mytable’, {NAME => ‘colfam1’, BLOCKCACHE => ‘false’}
如果预见到mytable的范围查询(顺序查找)业务较多,
这种场景可以将mytable的读缓存机制关掉。
如果不关掉,会导致此表大量的范围数据都会加载到BlockCache里,会挤掉其他表有用的随机查找数据。
3)开启布隆过滤器
数据块索引提供了一个有效的方法getDataBlockIndexReader(),在访问某个特定的行时用来查找应该读取的HFile的数据块。但是该方法的作用有限。HFile数据块的默认大小是64KB,一般情况下不能调整太多。
如果要查找一个很短的行,只在整个数据块的起始行键上建立索引是无法给出更细粒度的索引信息的。例如,某行占用100字节存储空间,一个64KB的数据块包含(64×1024)/100=655.53,约700行,只能把起始行放在索引位上。要查找的行可能落在特定数据块上的行区间,但也不能肯定存放在那个数据块上,这就导致多种可能性:该行在表中不存在,或者存放在另一个HFile中,甚至在MemStore中。这些情况下,从硬盘读取数据块会带来I/O开销,也会滥用数据块缓存,这会影响性能,尤其是当面对一个巨大的数据集且有很多并发读用户时。
布隆过滤器(Bloom Filter)允许对存储在每个数据块的数据做一个反向测验。当查询某行时,先检查布隆过滤
器,看看该行是否不在这个数据块。布隆过滤器要么确定回答该行不在,要么回答不知道。因此称之为反向测验。布隆过滤器也可以应用到行内的单元格上,当访问某列标识符时先使用同样的反向测验。
使用布隆过滤器也不是没有代价,相反,存储这个额外的索引层次占用额外的空间。布隆过滤器的占用空间大小随着它们的索引对象数据增长而增长,所以行级布隆过滤器比列标识符级布隆过滤器占用空间要少。当空间不是问题时,它们可以压榨整个系统的性能潜力。
可以在列族上打开布隆过滤器,代码如下:
hbase(main):007:0> create ‘mytable’, {NAME => ‘colfam1’, BLOOMFILTER => ‘ROWCOL’}
布隆过滤器参数的默认值是NONE。另外,还有两个值:ROW表示行级布隆过滤器;ROWCOL表示列标识符级布隆过滤器。行级布隆过滤器在数据块中检查特定行键是否不存在,列标识符级布隆过滤器检查行和列标识符联合体是否不存在。ROWCOL布隆过滤器的空间开销高于ROW布隆过滤器。
4)开启数据压缩
HFile可以被压缩并存放在HDFS上,这有助于节省硬盘I/O,此外,可以节省带宽。
但是读写数据时压缩和解压缩会抬高CPU利用率。压缩是表定义的一部分,可以在建表或模式改变时设定。除非确定压缩不会提升系统的性能,否则推荐打开表的压缩。只有在数据不能被压缩,或者因为某些原因服务器的CPU利用率有限制要求的情况下,有可能需要关闭压缩特性。
HBase可以使用多种压缩编码,包括LZO、SNAPPY和GZIP,LZO和SNAPPY是其中最流行的两种。
当建表时可以在列族上打开压缩,代码如下:
hbase(main):002:0>
create ‘mytable’, {NAME => ‘colfam1’, COMPRESSION => ‘SNAPPY’}
注意,数据只在硬盘上是压缩的,在内存中(MemStore或BlockCache)或在网络传输时是没有压缩的。
5)设置Scan缓存
HBase的Scan查询中可以设置缓存,定义一次交互从服务器端传输到客户端的行数,设置方法是使用Scan类中
setCaching()方法,这样能有效地减少服务器端和客户端的交互,更好地提升扫描查询的性能。下面的代码展示了如何使用setCaching()方法。
代码示例:
HTable table = new HTable(config, Bytes.toBytes(tableName));
Scan scanner = new Scan();
/* batch and caching */
scanner.setBatch(0);
scanner.setCaching(10000);
ResultScanner rsScanner = table.getScanner(scanner);
for (Result res : rsScanner) {
final List list = res.list();
String rk = null;
StringBuilder sb = new StringBuilder();
for (final KeyValue kv : list) {
sb.append(Bytes.toStringBinary(kv.getValue()) + “,”);
rk = getRealRowKey(kv);
}
if (sb.toString().length() > 0)
sb.setLength(sb.toString().length() - 1);
System.out.println(rk + “\t” + sb.toString());
}
rsScanner.close();
6)显式地指定列
当使用Scan或Get来处理大量的行时,最好确定一下所需要的列。因为服务器端处理完的结果,需要通过网络传输到客户端,而且此时,传输的数据量成为瓶颈,如果能有效地过滤部分数据,使用更精确的需求,能够很大程度上减少网络I/O的花费,否则会造成很大的资源浪费。如果在查询中指定某列或者某几列,能够有效地减少网络传输量,在一定程度上提升查询性能。下面代码是使用Scan类中指定列的addColumn()方法。
代码示例:
HTable table = new HTable(config, Bytes.toBytes(tableName));
Scan scanner = new Scan();
/* 指定列 */
scanner.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column));
ResultScanner rsScanner = table.getScanner(scanner);
for (Result res : rsScanner) {
final List list = res.list();
String rk = null;
StringBuilder sb = new StringBuilder();
for (final KeyValue kv : list) {
sb.append(Bytes.toStringBinary(kv.getValue()) + “,”);
rk = getRealRowKey(kv);
}
if (sb.toString().length() > 0)
sb.setLength(sb.toString().length() - 1);
System.out.println(rk + “\t” + sb.toString());
}
rsScanner.close();
7)关闭ResultScanner
ResultScanner类用于存储服务端扫描的最终结果,可以通过遍历该类获取查询结果。但是,如果不关闭该类,可能会出现服务端在一段时间内一直保存连接,资源无法释放,从而导致服务器端某些资源的不可用,还有可能引发RegionServer的其他问题。所以在使用完该类之后,需要执行关闭操作。这一点与JDBC操作MySQL类似,需要关闭连接。代码的最后一行rsScanner.close()就是执行关闭ResultScanner。
8)使用批量读
通过调用HTable.get(Get)方法可以根据一个指定的行键获取HBase表中的一行记录。同样HBase提供了另一个方法,通过调用HTable.get(List)方法可以根据一个指定的行键列表,批量获取多行记录。使用该方法可以在服务器端执行完批量查询后返回结果,降低网络传输的速度,节省网络I/O开销,对于数据实时性要求高且网络传输RTT高的场景,能带来明显的性能提升。
代码示例:
HTable table = new HTable(config, Bytes.toBytes(tableName));
Get get1 = new Get(ROW1);
Get get2 = new Get(ROW2);
Get get3 = new Get(ROW3);
List gets = new ArrayList();
gets.add(get1);
gets.add(get2);
gets.add(get3);
try {
Result[] result = table.get(gets);
return result;
} catch (IOException e) {
e.printStackTrace();
return null;
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
9)使用批量写
通过调用HTable.put(Put)方法可以将一个指定的行键记录写入HBase,同样HBase提供了另一个方法,通过调用HTable.put(List)方法可以将指定的多个行键批量写入。这样做的好处是批量执行,减少网络I/O开销。对于批量写入方法的使用见下面代码:
HTable table = new HTable(config, Bytes.toBytes(tableName));
Put put1 = new Put(ROW1);
put.add(Bytes.toBytes(“cf1”),Bytes.toBytes(“mid”),Bytes.toBytes(123456));
Put put2 = new Put(ROW2);
put.add(Bytes.toBytes(“cf1”),Bytes.toBytes(“mid”),Bytes.toBytes(123456));
Put put3 = new Put(ROW3);
put.add(Bytes.toBytes(“cf1”),Bytes.toBytes(“mid”),Bytes.toBytes(123456));
List puts = new ArrayList();
puts.add(put1);
puts.add(put2);
puts.add(put3);
try {
table.put(puts);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
10)关闭写WAL日志
在默认情况下,为了保证系统的高可用性,写WAL日志是开启状态。写WAL开启或者关闭,在一定程度上确实会对系统性能产生很大影响,根据HBase内部设计,WAL是规避数据丢失风险的一种补偿机制,如果应用可以容忍一定的数据丢失的风险,可以尝试在更新数据时,关闭写WAL。该方法存在的风险是,vRegionServer宕机时,可能写入的数据会出现丢失的情况,且无法恢复。关闭写WAL操作通过Put类中的writeToWAL()设置。
具体的设置方法如下面代码所示:
long st = System.currentTimeMillis();
Put put = new Put(Bytes.toBytes(“r1”));
put.add(Bytes.toBytes(“cf1”), Bytes.toBytes(“mid”),
Bytes.toBytes(123111));
put.add(Bytes.toBytes(“cf1”), Bytes.toBytes(“stat_hour”),
Bytes.toBytes(“20”));
put.add(Bytes.toBytes(“cf1”), Bytes.toBytes(“logdate”),
Bytes.toBytes(“20181226”));
put.add(Bytes.toBytes(“cf1”), Bytes.toBytes(“ditch”),
Bytes.toBytes(“2”));
put.add(Bytes.toBytes(“cf1”), Bytes.toBytes(“version”),
Bytes.toBytes(“3.2.2.2”));
put.add(Bytes.toBytes(“cf1”), Bytes.toBytes(“type”),
Bytes.toBytes(“2”));
put.setWriteToWAL(false);
table.put(put);
table.close();
long en = System.currentTimeMillis();
System.out.println(“time: " + (en - st) + “… ms”);
11)设置AutoFlush
HTable有一个属性是AutoFlush,该属性用于支持客户端的批量更新。该属性默认值是true,即客户端每收到一条数据,立刻发送到服务端。如果将该属性设置为false,当客户端提交Put请求时,将该请求在客户端缓存,直到数据达到某个阈值的容量时(该容量由参数hbase.client.write.buffer决定)或执行hbase.flushcommits()时,才向RegionServer提交请求。这种方式避免了每次跟服务端交互,采用批量提交的方式,所以更高效。
但是,如果还没有达到该缓存而客户端崩溃,该部分数据将由于未发送到RegionServer而丢失。这对于有些零容忍的在线服务是不可接受的。所以,设置该参数的时候要慎重。
HTable设置AutoFlush的示例代码如下:
public static final boolean AUTO_FLUSH = false;
public static final int WRITE_BUFFER_SIZE = 12 * 1024 * 1024;
public void put() throws IOException {
table.setAutoFlush(AUTO_FLUSH);
table.setWriteBufferSize(WRITE_BUFFER_SIZE);
long st = System.currentTimeMillis();
Put put = null;
for (int i = 0; i < 100000; i++) {
put = new Put(Bytes.toBytes(“row1”),10L);
put.add(Bytes.toBytes(“cf1”), Bytes.toBytes(“mid”),
Bytes.toBytes(123111));
put.add(Bytes.toBytes(“cf1”), Bytes.toBytes(“stat_hour”),
Bytes.toBytes(“20”));
put.add(Bytes.toBytes(“cf1”), Bytes.toBytes(“logdate”),
Bytes.toBytes(“20121126”));
put.add(Bytes.toBytes(“cf1”), Bytes.toBytes(“ditch”),
Bytes.toBytes(“2”));
put.add(Bytes.toBytes(“cf1”), Bytes.toBytes(“version”),
Bytes.toBytes(“3.2.2.2”));
put.add(Bytes.toBytes(“cf1”), Bytes.toBytes(“type”),
Bytes.toBytes(“2”));
put.setWriteToWAL(true);
table.put(put);
if ((i % 1000) == 0) {
System.out.println(i + " DOCUMENTS done!”);
}
}
table.flushCommits();
table.close();
long en = System.currentTimeMillis();
System.out.println("time: " + (en - st) + “… ms”);
}
12)预创建Region
在HBase中创建表时,该表开始只有一个Region,插入该表的所有数据会保存在该Region中。随着数据量不断增加,当该Region大小达到一定阈值时,就会发生分裂(Region Splitting)操作。并且在这个表创建后相当长的一段时间内,针对该表的所有写操作总是集中在某一台或者少数几台机器上,这不仅仅造成局部磁盘和网络资源紧张,同时也是对整个集群资源的浪费。这个问题在初始化表,即批量导入原始数据的时候,特别明显。为了解决这个问题,可以使用预创建Region的方法。
Hbase内部提供了RegionSplitter工具,使用命令如下:
${HBASE_HOME}/bin/hbase org.apache.hadoop.hbase.util.RegionSplitter test2 HexStringSplit -c 10 -f cf1
其中,test2是表名,HexStringSplit表示划分的算法,参数-c 10表示预创建10个Region,-f cf1表示创建一个名字为cf1的列族。
13)调整ZooKeeper Session的有效时长
参数zookeeper.session.timeout用于定义连接ZooKeeper的Session的有效时长,这个默认值是180秒。这意味着一旦某个RegionServer宕机,HMaster至少需要180秒才能察觉到宕机,然后开始恢复。或者客户端读写过程中,如果服务端不能提供服务,客户端直到180秒后才能觉察到。在某些场景中,这样的时长可能对生产线业务来讲是不能容忍的,需要调整这个值。
此参数也可以在HBase-site.xml中设置。
好了,HBASE优化的问题暂且说到这里,如果有误说的地方请各位看到的大神指教。