Word转html实现在线预览
word转html,可以同时支持doc和docx两种格式,非常好用
开发工具:idea
项目管理工具:maven
不多说,直接撸代码
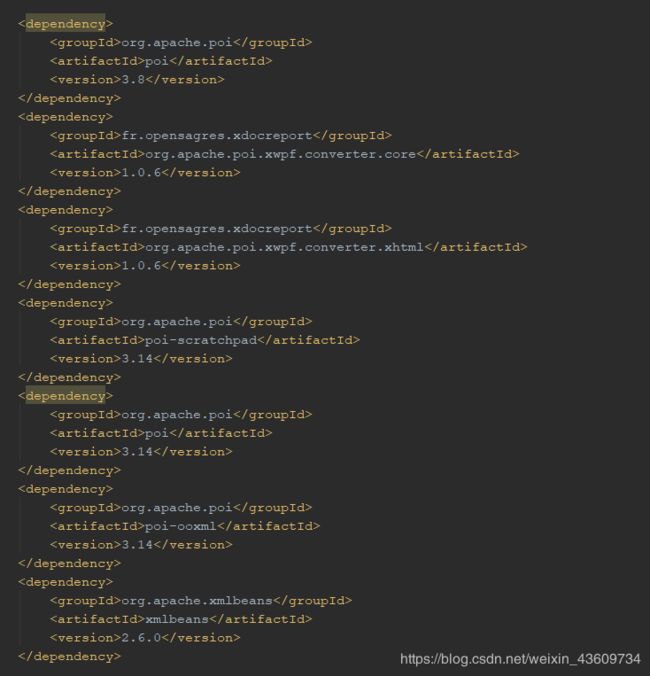
1、首先配置pom.xml文件,具体配置如下
2、工具类的开发
/**
* WORD转HTML docx格式
* POI版本: 3.10-FINAL
* */
import java.io.*;
import java.util.List;
import org.apache.poi.xwpf.usermodel.IBodyElement;
import org.apache.poi.xwpf.usermodel.ParagraphAlignment;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.apache.poi.xwpf.usermodel.XWPFPicture;
import org.apache.poi.xwpf.usermodel.XWPFPictureData;
import org.apache.poi.xwpf.usermodel.XWPFRun;
import org.apache.poi.xwpf.usermodel.XWPFTable;
import org.apache.poi.xwpf.usermodel.XWPFTableCell;
import org.apache.poi.xwpf.usermodel.XWPFTableRow;
public class Docx2Html {
/**
* 解析DOC
*
* @param fileName 文件名
* @param isAllHtml 全部为HMTL
* @param tmpImgDir 临时目录,不包含文件名
* @param tmpImgUrl 临时链接,图片 链接不包含文件名,通常这个参数可以传一个相对路径
* @throws Exception
*/
public static String analysisDocument(String fileName,boolean isAllHtml,String tmpImgDir,String tmpImgUrl) throws Exception{
InputStream in = new FileInputStream(new File(fileName));
return analysisDocument(in, isAllHtml, tmpImgDir, tmpImgUrl);
}
/**
* 解析DOC
*/
public static String analysisDocument(InputStream in,boolean isAllHtml,String tmpImgDir,String tmpImgUrl) throws Exception {
XWPFDocument doc = new XWPFDocument(in);
StringBuffer buffer=new StringBuffer();
List eles= doc.getBodyElements();
for(IBodyElement el:eles){
String name=el.getElementType().name();
if(name.equals("表格")){//表格
XWPFTable table=(XWPFTable)el;
buffer.append(analysisTable(table));
}else {//文本
XWPFParagraph graph=(XWPFParagraph)el;
List runs=graph.getRuns();
ParagraphAlignment alignment=graph.getAlignment();
String align="left";
if(alignment.equals(ParagraphAlignment.CENTER)){
align="center";
}else if(alignment.equals(ParagraphAlignment.RIGHT)){
align="right";
}
buffer.append("");
}
}
String text=run.getText(run.getTextPosition());
if(null!=text){
String color=null==run.getColor()?"000":run.getColor();
int fontsize=run.getFontSize()==-1?15:run.getFontSize();
pBuffer.append("");
pBuffer.append(text).append("");
}
}
buffer.append(";'>").append(pBuffer.toString()).append("");
}
}
return buffer.toString();
}
/**
* 解析表格
* @param tb 表格 对象
* @return String
* @throws Exception
*/
static String analysisTable(XWPFTable tb)
throws Exception {
StringBuffer htmlTextTbl = new StringBuffer();
htmlTextTbl .append("");
List rows=tb.getRows();
int rowCount=rows.size();
for (int i = 0; i < rowCount; i++) {
XWPFTableRow tr = rows.get(i);
String trCls=(i%2==1)?"odd":"even";
htmlTextTbl .append("");
List cells=tr.getTableCells();
int cellCount=cells.size();
for (int j = 0; j < cellCount; j++) {
XWPFTableCell td = tr.getCell(j);
List cellGraphs= td.getParagraphs();
for (int k = 0; k < cellGraphs.size(); k++) {
XWPFParagraph para = cellGraphs.get(k);
String s =para.getText()==null?"": para.getText().trim();
if (s == "") {
s = " ";
}
if(i==0){
htmlTextTbl.append("").append(s).append(" ");
}else{
htmlTextTbl.append("").append(s).append(" ");
}
}
}
htmlTextTbl.append(" ");
}
htmlTextTbl.append("
");
return htmlTextTbl.toString();
}
public static void main(String args[]) {
try {
String htmlDoc=analysisDocument("d:/uploadtemp/mysql.docx", true, "d:/uploadtemp/","d:/uploadtemp/");
File file=new File("d:/uploadtemp/text.html");
if (file.exists()){
file.createNewFile();
}
FileWriter fileWriter=new FileWriter(file);
BufferedWriter bufferedWriter=new BufferedWriter(fileWriter);
bufferedWriter.write(htmlDoc,0,htmlDoc.length()-1);
bufferedWriter.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* WORD转HTML doc格式
* POI版本: 3.10-FINAL
* */
import java.io.*;
import org.apache.poi.hpsf.SummaryInformation;
import org.apache.poi.hwpf.HWPFDocument;
import org.apache.poi.hwpf.model.PicturesTable;
import org.apache.poi.hwpf.usermodel.CharacterRun;
import org.apache.poi.hwpf.usermodel.Picture;
import org.apache.poi.hwpf.usermodel.Range;
import org.apache.poi.hwpf.usermodel.Paragraph;
import org.apache.poi.hwpf.usermodel.Table;
import org.apache.poi.hwpf.usermodel.TableCell;
import org.apache.poi.hwpf.usermodel.TableIterator;
import org.apache.poi.hwpf.usermodel.TableRow;
public class Doc2Html {
private static final short ENTER_ASCII = 13; //回车
private static final short SPACE_ASCII = 32; // 空格
private static final short TABULATION_ASCII = 9; // TAB
public static int beginPosi = 0;
public static int endPosi = 0;
public static int beginArray[];
public static int endArray[];
public static String htmlTextArray[];
public static boolean tblExist = false;
/**
* 解析DOC
*
* @param fileName 文件名
* @param isAllHtml 全部为HMTL
* @param tmpImgDir 临时目录,图片
* @param tmpImgUrl 临时链接,图片
* @throws Exception
*/
public static String analysisDocument(String fileName,boolean isAllHtml,String tmpImgDir,String tmpImgUrl) throws Exception{
InputStream in = new FileInputStream(new File(fileName));
return analysisDocument(in, isAllHtml, tmpImgDir, tmpImgUrl);
}
/**
* 解析DOC
*/
public static String analysisDocument(InputStream in,boolean isAllHtml,String tmpImgDir,String tmpImgUrl) throws Exception {
HWPFDocument doc = new HWPFDocument(in);
Range rangetbl = doc.getRange();
TableIterator it = new TableIterator(rangetbl);
int num = 100;
beginArray = new int[num];
endArray = new int[num];
htmlTextArray = new String[num];
int length = doc.characterLength();
if(length==0)return "";
PicturesTable pTable = doc.getPicturesTable();
SummaryInformation sif = doc.getSummaryInformation();
String title = "DOC文件预览";
if (null != sif) {
title = doc.getSummaryInformation().getTitle();
}
StringBuffer htmlText=new StringBuffer("");
if(isAllHtml){
htmlText.append("").append(title).append(" ");
}
if (it.hasNext()) {
analysisTables(it, rangetbl);
}
int cur = 0;
String tempString = "";
int index=0;
for (int i = 0; i < length - 1; i++) {
Range range = new Range(i, i + 1, doc);
CharacterRun cr = range.getCharacterRun(0);
if (tblExist) {
if (i == beginArray[cur]) {
htmlText.append(tempString).append(htmlTextArray[cur]);
tempString = "";
i = endArray[cur] - 1;
cur++;
continue;
}
}
if (pTable.hasPicture(cr)) {
htmlText.append(tempString);
String picFileName=analysisPicture(pTable, cr,tmpImgDir,index++);
htmlText.append(".append(tmpImgUrl.endsWith("/")?tmpImgUrl:(tmpImgUrl+"/")).append(picFileName).append("\") ");
tempString = "";
} else {
Range range2 = new Range(i + 1, i + 2, doc);
CharacterRun cr2 = range2.getCharacterRun(0);
char c = cr.text().charAt(0);
if (c == ENTER_ASCII) {
tempString += "
");
tempString = "";
} else {
Range range2 = new Range(i + 1, i + 2, doc);
CharacterRun cr2 = range2.getCharacterRun(0);
char c = cr.text().charAt(0);
if (c == ENTER_ASCII) {
tempString += "
";
}
else if (c == SPACE_ASCII)
tempString += " ";
else if (c == TABULATION_ASCII)
tempString += " ";
boolean flag = compareCharStyle(cr, cr2);
if (flag)
tempString += cr.text();
else {
StringBuffer fontStyle1 = new StringBuffer("") .append(tempString).append(cr.text()).append("");
fontStyle1.delete(0,fontStyle1.length());
tempString = "";
}
}
}
htmlText .append(tempString);
if(isAllHtml){htmlText .append("");}
return htmlText.toString();
}
/**
* 解析表格
* @param it
* @param rangetbl DOC段
* @throws Exception
*/
static void analysisTables(TableIterator it, Range rangetbl)
throws Exception {
int counter=0;
while (it.hasNext()) {
tblExist = true;
StringBuffer htmlTextTbl = new StringBuffer();
Table tb = (Table) it.next();
beginPosi = tb.getStartOffset();
endPosi = tb.getEndOffset();
beginArray[counter] = beginPosi;
endArray[counter] = endPosi;
htmlTextTbl .append("");
for (int i = 0; i < tb.numRows(); i++) {
TableRow tr = tb.getRow(i);
String trCls=(i%2==1)?"odd":"even";
htmlTextTbl .append("");
for (int j = 0; j < tr.numCells(); j++) {
TableCell td = tr.getCell(j);
int cellWidth = td.getWidth();
for (int k = 0; k < td.numParagraphs(); k++) {
Paragraph para = td.getParagraph(k);
String s = para.text().toString().trim();
if (s == "") {
s = " ";
}
if(i==0){
htmlTextTbl.append("").append(s).append(" ");
}else{
htmlTextTbl.append("").append(s).append(" ");
}
}
}
htmlTextTbl.append(" ");
}
htmlTextTbl.append("
");
htmlTextArray[counter++] = htmlTextTbl.toString();
}
}
/**
* 图片解析
*
* @param pTable WORD中的图片域
* @param cr
* @param path 临时路径
* @return String 图片文件名
* @throws Exception
*/
static String analysisPicture(PicturesTable pTable, CharacterRun cr, String path, int index)
throws Exception {
// 图片对象
Picture pic = pTable.extractPicture(cr, false);
// 图片文件名
String afileName = "dzpic_"+System.currentTimeMillis()+"_"+index+".jpg";
OutputStream out = new FileOutputStream(new File((path.endsWith("/")?path:(path+ "/")) + afileName));
pic.writeImageContent(out);
out.close();
return afileName;
}
/**
* 切换文字样式
* @param cr1
* @param cr2
* @return boolean
* */
static boolean compareCharStyle(CharacterRun cr1, CharacterRun cr2) {
boolean flag = false;
if (cr1.isBold() == cr2.isBold() && cr1.isItalic() == cr2.isItalic()
&& cr1.getFontName().equals(cr2.getFontName())
&& cr1.getFontSize() == cr2.getFontSize()) {
flag = true;
}
return flag;
}
/**
* 测试
* */
public static void main(String args[]) {
try {
String htmlDoc=analysisDocument("d:/uploadtemp/监造流程.doc", true, "d:/uploadtemp/","d:/uploadtemp/");
File file=new File("d:/uploadtemp/监造流程.html");
if (file.exists()){
file.createNewFile();
}
FileWriter fileWriter=new FileWriter(file);
BufferedWriter bufferedWriter=new BufferedWriter(fileWriter);
bufferedWriter.write(htmlDoc,0,htmlDoc.length()-1);
bufferedWriter.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
import javax.servlet.http.HttpServletRequest;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
/**
* 分析文档的格式是doc还是docx
* */
public class AnaliysisDom {
public static String analiysisDom(String path,String filename,HttpServletRequest request){
String uri=null;
String realPath=null;
String inputpath=path+filename;
String outputname=(filename.substring(0,filename.lastIndexOf('.')))+".html";
String outputpath=path+outputname;
File imgfile=new File(path+filename.substring(0,filename.lastIndexOf('.')));
String string=imgfile.getPath();
if (!imgfile.exists()){
imgfile.mkdirs();
}
File outputFile = new File(outputpath);
if (outputFile.exists()){
}else {
if (inputpath.endsWith(".doc") || inputpath.endsWith(".DOC")){
try {
String s = Doc2Html.analysisDocument(inputpath, true, imgfile.getPath(), imgfile.getPath());
File file=new File(outputpath);
if (file.exists()){
file.createNewFile();
}
FileWriter fileWriter=new FileWriter(file);
BufferedWriter bufferedWriter=new BufferedWriter(fileWriter);
bufferedWriter.write(s,0,s.length()-1);
bufferedWriter.close();
} catch (Exception e) {
e.printStackTrace();
}
}
if (inputpath.endsWith(".docx") || inputpath.endsWith("DOCX")){
try {
String s = Docx2Html.analysisDocument(inputpath, true, imgfile.getPath()+"/", imgfile.getPath()+"/");
File file=new File(outputpath);
if (file.exists()){
file.createNewFile();
}
FileWriter fileWriter=new FileWriter(file);
BufferedWriter bufferedWriter=new BufferedWriter(fileWriter);
bufferedWriter.write(s,0,s.length()-1);
bufferedWriter.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
realPath = request.getSession().getServletContext().getRealPath(outputname);
System.out.println(realPath);
uri=request.getScheme() + "://" + request.getServerName() + ":" +
request.getServerPort() +"/"+ request.getContextPath() +outputname;
return uri;
}
}
controller层代码实例
@RequestMapping("/readFile")
@ResponseBody
public String readFile(String templateattachpath,HttpServletRequest request){
String uri="";
try {
uri=AnaliysisDom.analiysisDom(path,templateattachpath,request);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return uri;
}
这样word转html就转换成功了,超简单,开撸吧!!!!