【论文翻译】PSENet:Shape Robust Text Detection with Progressive Scale Expansion Network
Shape Robust Text Detection with Progressive Scale Expansion Network
基于渐进式尺寸可扩展网络的形状鲁棒文本检测
论文链接:https://arxiv.org/pdf/1806.02559.pdf
论文代码:https://github.com/whai362/psenet
【摘要】 形状鲁棒性文本检测面临的挑战主要有两个方面:1)现有的基于四边形边界盒的文本检测方法很难找到任意形状的文本,很难完全封闭在矩形中;2)大多数基于像素的分割检测器可能不会将彼此非常接近的文本实例分开。为了解决这些问题,我们提出了一种新的渐进尺度扩展网络(PSEnet),它是一种基于分割的检测器,对每个文本实例都有多个预测。这些预测对应于通过将原始文本实例缩小到不同的尺度而产生的不同的“内核”。因此,最终的检测可以通过我们的渐进尺度扩展算法进行,该算法将最小尺度的核逐步扩展到最大和完全形状的文本实例。由于这些极小核间存在较大的几何边缘,因此我们的方法能够有效地区分相邻文本实例,并且对任意形状具有鲁棒性。最新的结果是ICDAR 2015和ICDAR 2017,MLT基准进一步证实了PSEnet的巨大有效性。值得注意的是,在曲线文本数据集SCUT-CTW1500上,PSEnet以绝对6.37%的优势超过了之前最好的记录。代码将在https://github.com/whai362/psenet中提供。
【补充1】ICDAR 国际文档分析和识别大会
ICDAR是一个专注于文本识别、基于视频的文本分析的国际性的会议,自2003年开始,ICDAR设立了和会议同名的竞赛,该竞赛成了评测和检测自然场景、负责视频等场景识别技术的最最重要的国际赛事和标准。此竞赛挑战是为了涵盖广泛的现实世界情况,每一项挑战都围绕着不同的任务展开。
ICDAR的地址链接:http://rrc.cvc.uab.es/
ICDAR 2019 Robust Reading competitionstia挑战任务如下图
1 Introduction
近年来,自然场景文本检测在场景理解、产品识别、自动驾驶和目标定位等众多应用中得到了广泛的关注。然而,由于前景文本和背景对象的巨大差异,以及各种形状、颜色、字体、方向和尺度的文本变化以及极端的照明和遮挡,自然场景中的文本检测仍然面临着相当大的挑战。
然而,随着卷积神经网络(CNNs) 的飞速发展,近年来取得了很大的进展。基于包围盒回归(Bounding Box Regression) 的方法被提出了一组方法来成功地定位具有特定方向的矩形或四边形形式的文本目标。不幸的是,这些框架无法检测任意形状的文本实例(例如曲线文本),这些文本实例也经常出现在自然场景中(参见图1(B))。自然,基于语义分割的方法可以显式地处理曲线文本的检测问题。 虽然像素分割可以提取任意形状文本实例的区域,但当两个文本实例相对接近时,仍然可能无法将它们分开,因为它们的共享相邻边界可能会将它们合并为一个单一文本实例。
【补充1】语义分割(semantic segmentation)
图像的语义分割,从字面意思上理解就是让计算机根据图像的语义来进行分割;在图像领域,语义指的是图像的内容,对图片意思的理解。目前语义分割的应用领域主要有:地理信息系统、无人车驾驶、医疗影像分析、机器人等领域。具体的语义分割的简介可以看大佬的博客——计算机视觉之语义分割:http://blog.geohey.com/ji-suan-ji-shi-jue-zhi-yu-yi-fen-ge/
【补充2】实例分割(Instance Segmentation)
实例分割就是机器自动从图像中用目标检测方法框出不同实例,再用语义分割方法在不同实例区域内进行逐像素标记,借一个浅显的说法:语义分割不区分属于相同类别的不同实例,而实例分割可以区分出这些像素属于同种类的不同物体。具体的实例分割可以看大佬的博客——实例分割总结 Instance Segmentation Summary:https://blog.csdn.net/qq_39295044/article/details/79796663
为了解决这些问题,本文提出了一种新的实例分割网络,即渐进式扩展网络(PSENet)。PSENet有两方面的优势。 首先,psenet作为一种基于分割的方法,能够对任意形状的文本进行定位.其次,我们提出了一种渐进的尺度扩展算法,该算法可以成功地识别相邻文本实例(见图1(D)。具体地,我们将每个文本实例分配给多个预测的分割区域。为了方便起见,我们将这些分割区域表示为本文中的“核”,并且对于一个文本实例,有几个对应的内核。每个内核与原始的整个文本实例共享相似的形状,并且它们都位于相同的中心点但在比例上不同。为了得到最终的检测结果,我们采用了渐进的尺度扩展算法。 它基于宽度优先搜索(BFS), 由三个步骤组成:1)从具有最小尺度的核开始(在此步骤中可以区分实例);2)通过逐步在较大的核中加入更多的像素来扩展它们的区域;3)完成直到发现最大的核。
【补充】宽度优先搜索算法(Breadth-First-Search,BFS)
宽度优先搜索算法(又称广度优先搜索) 是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。Dijkstra单源最短路径算法和Prim最小生成树算法都采用了和宽度优先搜索类似的思想,属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。换句话说,它并不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为止。(百度百科)
渐进式规模扩张的动因主要有四点。 首先,具有极小尺度的核很容易被分离,因为它们的边界远离彼此。因此,克服了以往基于分割的方法的主要缺点;第二,最大的核或文本实例的完整区域对于实现最终的精确检测是必不可少的;第三,核从小到大逐渐长大,因此平滑的监视将使网络更容易学习;最后,渐进尺度扩展算法确保文本实例的精确位置,因为它们的边界是以谨慎和渐进的方式展开的。
为了展示我们提出的PSENet的高效性,我们在三个竞赛的benchmarks上进行了广泛的实验,包含着 ICDAR 2015, ICDAR 2017 MLT和SCUTCTW 1500。在这些数据集中,SCUTCTW 1500是为曲线文本检测明确设计的,在这个数据集上,我们以绝对6.37%的绝对优势超过了以前的先进水平。此外,与现有的最先进方法相比,我们提出的PSENet在普通四边形文本数据集: ICDAR 2015和 ICDAR 2017 MLT上取得了更好或至少可比较的性能。
本文的主要贡献如下:【划重点!】
- 我们提出了一种新颖的渐进扩展网络(PSENet),它可以精确地检测任意形状的文本实例;
- 我们提出了一种渐进的尺度扩展算法,它能够准确地将文本实例紧密地分开;
- 我们提出的PSENET显著优于现有的曲线文本检测数据集Cut-CtTW1500的方法。此外,它还实现了关于规则四边形文本基准的竞争结果:ICDAR2015和ICDAR2017MLT;
2 Related Work
长期以来,文本检测一直是计算机视觉领域的一个活跃的研究课题。成功地将目标检测管道应用到文本检测中,并在水平文本检测方面取得了良好的性能。之后,考虑到文本行的方向,使得能够检测到任意的文本实例。近期,可以实现利用角点定位为文本实例寻找合适的不规则四边形。检测方式由水平矩形发展到旋转矩形,进一步发展为不规则四边形。然而,在自然场景中,除了四边形外,还有许多文本实例的形状。因此,一些研究开始探索曲线文本的检测,并取得了一定的结果。[18]试图回归14边多边形点的相对位置。通过定位滑动线中的两个端点,即水平和垂直滑动,检测曲线文本。文中提出了一种基于包围盒回归和语义分割的融合检测器。然而,由于它们目前的性能不太理想,在曲线文本检测方面仍有很大的推广空间,对于任意形状文本的检测还需要更多的探索。
3 Proposed Method
在本节中,我们首先介绍了拟议的逐步扩展网络(PSENet)的整个流水线。接下来,我们介绍了渐进扩展算法的细节,并给出了如何有效区分相邻文本实例。此外,还介绍了生成标签的方式和损耗函数的设计。最后,我们对PSENet的实现细节进行了描述。
3.1 Overall Pipeline
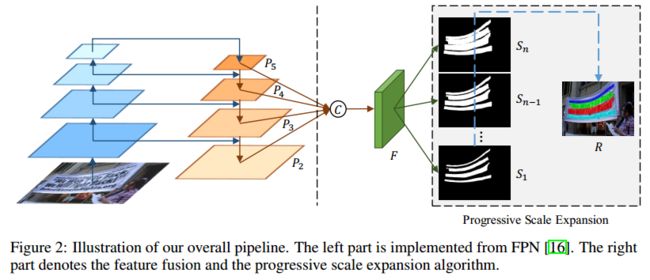
图1.2示出了所提出的PSENET的整个pipeline。在FPN(可以翻看我们的博客)的启发下,我们将低层特征映射与高级特征映射连接起来,从而有四个级联的特征映射。这些映射在f中进一步融合以编码具有各种接受视图的信息。从直觉上看,这种融合很可能促进具有不同尺度的核的世代。然后将特征映射f投影到n个分支中,以产生多个分割结果 S 1 S_1 S1; S 2 S_2 S2;…; S n S_n Sn。每个 S i S_i Si将是所有文本实例在一定范围内的一个分割掩码。不同分割掩模的尺度由将在Sec3.3中讨论的超参数来决定。在这些掩码中, S 1 S_1 S1给出了具有最小标度(即,最小内核)的文本实例的分割结果,而 S n S_n Sn表示原始分割掩码(即,最大内核)。在获得这些分段掩码后,我们使用渐进扩展算法将 S 1 S_1 S1中的所有实例“内核”逐渐扩展到其 S n S_n Sn中的完整形状,并获得最终的检测结果为R。
3.2 Progressive Scale Expansion Algorithm
如图所示1©基于切分的方法很难分离彼此相近的文本实例。为了解决这一问题,我们提出了渐进尺度扩展算法。
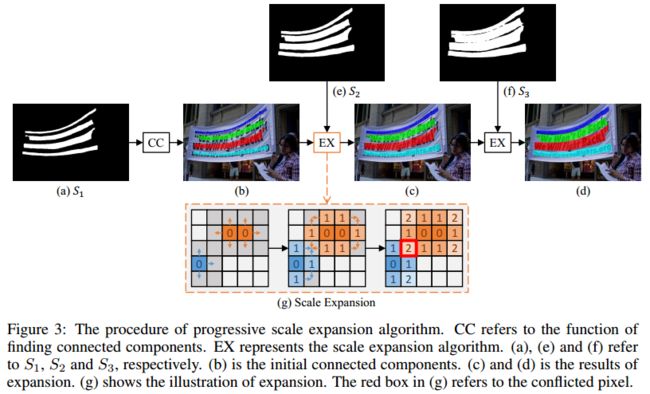
这里是一个生动的例子(见图.3)解释渐进扩展算法的过程,从广度优先搜索(BFS)算法中引入其中心思想。例如,我们有3个分割结果 S = S 1 , S 2 , S 3 S={S_1,S_2,S_3} S=S1,S2,S3(参见图3(a),(e),(f))。首先,基于最小内核特征图的 S 1 S_1 S1(参见图3(a)),4个不同的连接组件 c = c 1 , c 2 , c 3 , c 4 c=c_1,c_2,c_3,c_4 c=c1,c2,c3,c4可以作为初始化。图中不同颜色的区域(参见图3(b))分别表示这些不同的连接部件。到目前为止,我们已经检测到了所有文本实例的中心部分(即最小内核)。然后,我们通过合并 S 2 S_2 S2中的像素,然后在 S 3 S_3 S3中逐步扩展检测到的内核。两个标度扩展的结果在图3中。最后,我们在图中提取标有不同颜色的已连接组件作为文本实例的最终预测(参见图3(d))。
图3(g)中示出了尺度扩展的过程。扩展基于广度搜索算法,该算法从多个核的像素开始,然后迭代地合并相邻的文本像素。注意,在展开过程中可能存在冲突的像素,如图3(g)中的红色框所示。在我们的实践中处理冲突的原则是,混淆的像素只能在先到先得的基础上由一个单一内核合并。 由于“渐进的”扩展过程,这些边界冲突不会影响最终检测和性能。算法1总结了扩展算法的细节。在伪码中,T,P是中间结果。Q是队列。Neighbor(·) 代表了近邻像素p。GroupByLabel(·) 将中间结果按标签分组的功能。“Si[q] =True” 意味着预测的 S i S_i Si中的q的真值是属于这个文本部分的。
【解读】渐进尺度扩展算法
1)基于我们已经得到的 S 1 S_1 S1的最小kernels’ map,我们已经找到了基本的语义分割区块,再从像素分割上来对分割区域进行扩展,所以用的就是EX。
2)假设图3(g)中的橙色区域是我们已经分割出来的区域,我们用扩展四邻域(上下左右)的方法来扩展区域;[备注:图3(g)中的红框为蓝色区域和橙色区域在扩展过程中相冲突的地方,解决办法就是先到先得,哪一个单一内核先扩展到这个像素点就将其划分到自己的区域];
3)经过几次EX的扩展,我们将得到更为准确的分割区域;
3.3 Label Generation
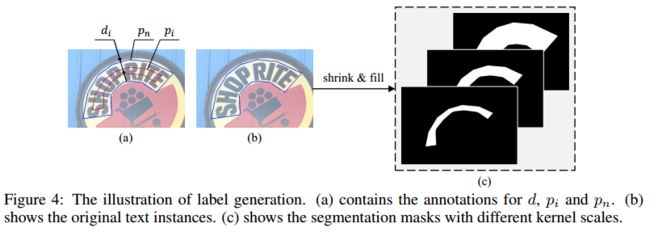
如图2所示,PSENet产生具有不同内核规模的分割结果(例如 S 1 ; S 2 ; . . . ; S N S_1;S_2;...;S_N S1;S2;...;SN)。因此,它需要相应的Ground Truth,在训练过程中也有不同的内核规模。在我们的实践中,可以简单且有效地通过缩减原始文本实例来进行这些Ground Truth标签。图 4 ( b ) 4(b) 4(b)中带有蓝色边框的多边形表示原始文本实例,并且它对应于最大分段标签掩码(参见图 4 ( c ) 4(c) 4(c))。为了依次获得例如图 4 ( c ) 4(c) 4(c)缩小的掩模,我们利用Vatti clipping algorithm来缩小原来的多边形 p n p_n pn的 d i d_i di像素,并得到缩小多边形 p i p_i pi(见图4(a))。随后,每个缩小的多边形 p i p_i pi被转换成一个0/1的二进制掩码,用于分割标签的地面真相。我们将这些Ground Truth分别表示为 G 1 ; G 2 ; . . . ; G n G_1;G_2;...;G_n G1;G2;...;Gn。从数学上讲,如果我们认为比例比是 r i r_i ri,那么 p n p_n pn和 p i p_i pi之间的范围 d i d_i di 可以计算为:
(1) d i = A r e a ( p n ) ∗ ( 1 − r i 2 ) P e r i m e t e r ( p n ) d_i = \frac {Area(p_n) * (1-r_i^2)}{Perimeter(p_n)} \tag{1} di=Perimeter(pn)Area(pn)∗(1−ri2)(1)
其中,Area(·)是计算多边形区域的函数,Perimeter(·) 是计算多边形周长的函数。此外,我们还定义了对于Ground Truth map G i G_i Gi范围比例 r i r_i ri:
(2) r i = 1 − ( 1 − m ) ∗ ( n − i ) n − 1 r_i = 1 - \frac {(1-m)*(n-i)}{n-1} \tag{2} ri=1−n−1(1−m)∗(n−i)(2)
其中,m为小小的尺寸比例,取值为 ( 0 , 1 ] (0,1] (0,1]。基于(2)式,尺度比例 ( r 1 ; r 2 ; . . . ; r n ) (r_1;r_2;...;r_n) (r1;r2;...;rn)的值由两个超参数n和m决定,它们从m线性增加到1。
【补充】Vatti clipping algorithm
Vatti clipping algorithm用于计算机图形学。它允许任意数量任意形状的主题多边形裁剪任意数量任意形状的剪辑多边形。该算法不限制可用作主体或剪辑的多边形类型,即使是复杂的(自交)多边形和有孔的多边形也可以被处理。该算法一般只适用于二维空间。
3.4 Loss Function
对于学习PSENet,损失函数可以定义为下式:
(3) L = λ L c + ( 1 − λ ) L s L = \lambda L_c + (1-\lambda) L_s \tag{3} L=λLc+(1−λ)Ls(3)
其中 L c L_c Lc和 L s L_s Ls分别表示完整文本实例和收缩实例的损失, λ \lambda λ平衡 L c L_c Lc和 L s L_s Ls之间的重要性。
在自然图像中,文本实例通常只占据极小的区域,这使得当使用二值交叉熵时网络偏向于非文本区域。受论文[20]的影响,我们在实验中采用了dice coefficient。 dice coefficient的定义如(4)式:
(4) D ( S i , G i ) = 2 ∑ x , y ( S i , x , y ∗ G i , x , y ) ∑ x , y S i , x , y 2 + ∑ x , y G i , x , y 2 D(S_i,G_i)= \frac{2\sum_{x,y}(S_{i,x,y}*G_{i,x,y})}{\sum_{x,y}S_{i,x,y}^2 +\sum_{x,y}G_{i,x,y}^2 } \tag{4} D(Si,Gi)=∑x,ySi,x,y2+∑x,yGi,x,y22∑x,y(Si,x,y∗Gi,x,y)(4)
其中, S i , x , y S_{i,x,y} Si,x,y和 G i , x , y G_{i,x,y} Gi,x,y是像素 ( x , y ) (x,y) (x,y)的分割结果 S i S_i Si和Ground Truth G i G_i Gi。
此外,还有许多类似于文字笔画的模式,如栅栏、格等。因此,我们在训练中采用在线难例挖掘(OHEM) 到 L c L_c Lc,以便更好地区分这些模式。
L c L_c Lc的重点是分割文本和非文本区域。 让我们考虑OHEM给出的训练mask为M,因此 L c L_c Lc可以写为:
(5) L c = 1 − D ( S n ⋅ M , G n ⋅ M ) L_c = 1-D(S_n·M,G_n·M) \tag{5} Lc=1−D(Sn⋅M,Gn⋅M)(5)
L s L_s Ls是收缩文本实例的损失。 由于它们被完整文本实例的原始区域包围,因此在分割结果 S n S_n Sn中忽略了非文本区域的像素,以避免一定的冗余。因此, L s L_s Ls可以定义为:
(6) L s = 1 − ∑ i = 1 n − 1 D ( S i ⋅ M , G i ⋅ M ) n − 1 , W x , y = { 1 i f S n , x , y > = 0.5 ; 0 o t h e r w i s e . L_s= 1-\frac{\sum^{n-1}_{i=1} D(S_i·M,G_i·M)}{n-1} , W{x,y}=\begin{cases} 1 & if S_{n,x,y} >= 0.5;\\ 0 & otherwise. \end{cases} \tag{6} Ls=1−n−1∑i=1n−1D(Si⋅M,Gi⋅M),Wx,y={10ifSn,x,y>=0.5;otherwise.(6)
其中,W是一个掩码,它忽略 S n S_n Sn中非文本区域的像素, S n , x , y S_{n,x,y} Sn,x,y指 S n S_n Sn中像素(x,y)的值。
【补充】在线难例挖掘(online hard example miniing,OHEM)
OHEM算法的核心思想是根据输入样本的损失进行筛选,筛选出难例,表示对分类和检测影响较大的样本,然后将筛选得到的这些样本应用在随机梯度下降中训练。在实际操作中是将原来的一个ROI Network扩充为两个ROI Network,这两个ROI Network共享参数。其中前面一个ROI Network只有前向操作,主要用于计算损失;后面一个ROI Network包括前向和后向操作,以hard example作为输入,计算损失并回传梯度。具体的关于OHEM的内容请参见大佬的博客——OHEM算法及Caffe代码详解:https://blog.csdn.net/u014380165/article/details/73148073