语音合成 | FastSpeech:Fast,Robust and Controllable Text to Speech论文阅读
文章目录
- 一、简介
- 目前TTS系统中,面临的问题:
- FastSpeech解决的问题:
- 二、Transformer介绍
- 三、FastSpeech网络结构图
- 四、实验
- 数据集
- 声音质量
- 合成速度
- 耗时比较
- 鲁棒性(错误计数)
- 语速调节
- 韵律控制
- 五、小结
联系邮箱:[email protected]

论文地址:https:/arxiv.org/abs/1905.09263
开源代码:https:/github.com/xcmyz/FastSpeech
论文作者及研究团队概述:
作者主要来自浙江大学和微软亚洲研究院机器学习组和微软(亚洲)互联网工程院语音团队。
一、简介
目前TTS系统中,面临的问题:
1、由于是自回归,生成Mel频谱图的速度慢。端到端模型主要是使用因果卷积,所有的模型都会生成以先前生成的Mel频谱图为条件的Mel频谱图,以自回归的方式生成Mel频谱图之后再通过声码器合成语音,而一段语音的Mel频谱图通常能到几百上千帧,导致合成速度较慢。
2、合成的语音不健壮。端到端模型通常采用编码器-注意力-解码器机制进行自回归生成,由于序列生成的错误传播以及注意力对齐不准,导致出现重复和跳过。
3、合成语音缺乏可控性。自回归的神经网络会自动逐个生成Mel频谱图,而不会明确地利用文本和语音之间的对齐。因此,通常很难直接控制生成语音的速度或者韵律停顿等。
FastSpeech解决的问题:
Fast:通过并行生成Mel频谱图,加快合成过程。
Robust:音素持续时间预测器确保音素与Mel频谱图之间的对齐,减少重大错误(跳过单词,重复单词)。
Controllable:加入长度调节器,通过延长或缩短音素持续时间来调节语音速度。通过在相邻音素之间添加间隔来控制部分韵律。
二、Transformer介绍
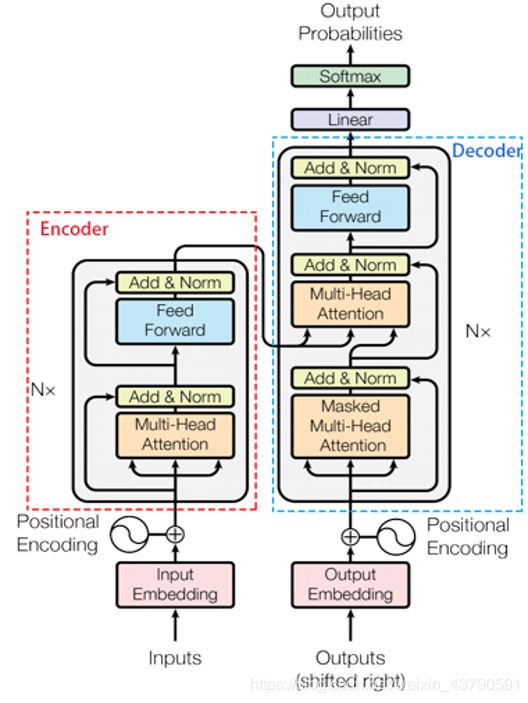
Transformer由Encoder-Decoder模型组成,Transfoormer模型是谷歌在2016年在《Attention is all you need》一文中推出的模型,其主要的创新就是其中的Attention机制。
位置编码如下:

其中self-attention的处理过程可分为7步:
(1)embedding操作。
(2)计算得出q,k,v三个向量。
(3)为每一个向量计算一个score.(score为q与k的点乘)
(4)score归一化,除以一个常数。(tranformer文中的常数为8)
(5)对score施以激活函数,得到的结果为每个词对于当前位置的词的相关性大小。
(6)softmax得到的结果点乘Value值v,得到最终评分。
Multi-Head-Attention,相当于h个不同的self-attention的集成,在《Attention Is All You Need》一文中,h=8。然后将所有的self-attention所有节点的值相加并进行归一化。
三、FastSpeech网络结构图


图(a),FastSpeech是基于Transformer中self-attention和1D卷积的一种前馈结构。这种结构本文称之为FFT块。音素序列作为输入。
图(b)为FFT Block的内部结构,采用Attention机制、1D卷积和归一化。
图(c)是长度调节器用于解决前馈变压器中音素和频谱图序列之间的长度不匹配问题,以及控制语音速度和部分韵律。音素序列的长度通常小于mel声谱图序列的长度,并且每个音素对应于几个mel声谱图。我们将与音素相对应的mel声谱图的长度称为音素持续时间(我们将在下一部分中描述如何预测音素持续时间)。基于音素持续时间d,长度调节器将音素序列的隐藏状态扩展d倍,然后隐藏状态的总长度等于Mel声谱图的长度。其实现过程如下:
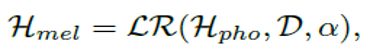
α是是一个超参数,用于确定Hmel的长度,从而控制语速,α=1(norm),α=1.3(slow),α=0.5(fast)。还可以通过调整句子中的空格字符的持续时间来调整韵律。
图(d)是音素持续时间预测器,包括两层1D卷积和一个线性输出层。在持续时间预测器生成的音素持续时间序列与教师模型的时间预测使用均方误差(MSE)作为损失函数。
MSEloss:

四、实验
数据集
作者团队选用LJSpeech数据集进行实验,其中包含13100个英语片段和对应的文字,总音频长度约24小时。将数据集随机分成3组:12500个样本用于训练,300个样本用于验证,300个样本作为测试集。
声音质量

此处的MOS为20个母语为英语的测评者打出的分数。从图中可以看出,FastSpeech的语音质量较Tacotron和Transformer的没有多大退化。
合成速度
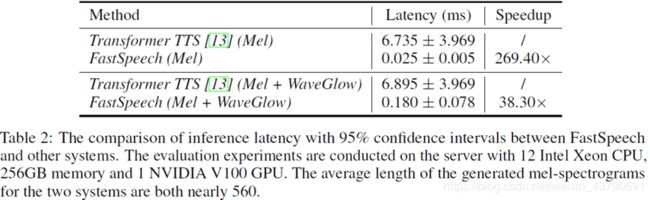
从图中可以看出,FastSpeech合成mel频谱图的速度是Transformer的将近270倍。加上声码器的总体速度是Transformer的36.3倍。
耗时比较
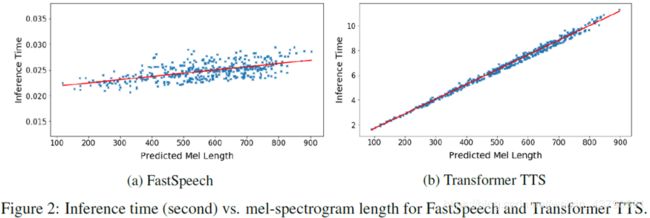
可以看出(两个图的纵坐标不同),随着生成语音长度的增大,FastSpeech的生成耗时并没有发生较大变化,而Transformer TTS的速度对长度非常敏感。
鲁棒性(错误计数)

使用50个对TTS系统特别难的句子。可以看出,FastSpeech出现的重大错误为0。
较难的50个句子节选:

语速调节
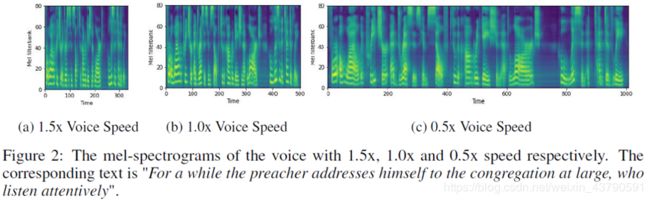
语速通过延长或缩短音素持续时间,如上图所示,FastSpeech可以顺畅地将语速从0.5x调整到1.5x,并且音调稳定且几乎不变。
韵律控制

可以通过延长句子中空格字符地持续时间来增加相邻单词之间的中断,这可以改善语音的韵律。
五、小结
1、长度调节器,解决了音素和Mel频谱图序列之间长度不匹配的问题。
2、持续时间预测器,确保了音素与其对应的Mel频谱图之间的对齐。
3、与Transformer TTS相比,FastSpeech在生成Mel频谱图时获得了270倍的加速。
4、在都使用WaveGlow声码器的情况下,FastSpeech的语音合成速度是Transformer TTS的38倍。