版本说明
es:2.4.3
ik:1.10.3
下载ik分词
github地址
不同的es有不同的ik版本对应,可在releases找到对应的版本,直接下载zip文件即可。
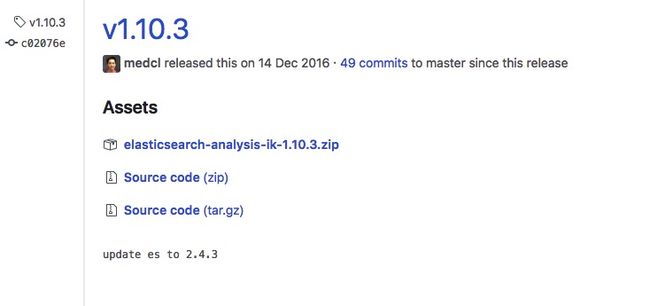
35BEA297310349159539040922996A6E.jpg
解压
在es目录下的plugins在创建ik目录,把下载ik的zip包所有文件解压进去。
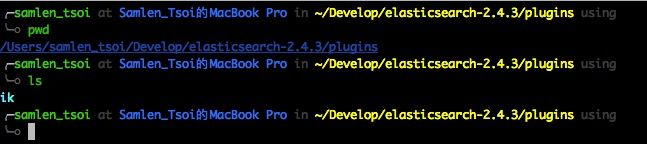
41A182BB45C65C4C113064ECF27C09A3.jpg
配置成默认分词器
进去es的config目录,编辑elasticsearch.yml,在空白地方加上index.analysis.analyzer.default.type : "ik"即可。
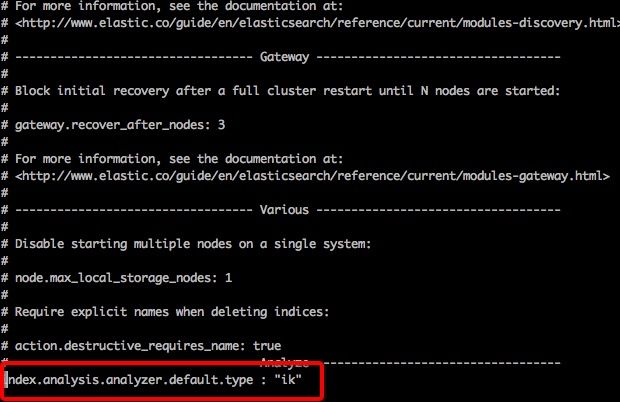
10B4F689F9A0870E5D5499D486ED9E4E.jpg
测试
首先创建索引、类型,对应string类型的field不指定分词器
{
"properties": {
"content": {
"type": "string"
},
"createTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"headImg": {
"type": "string",
"index": "not_analyzed"
},
"isClient": {
"type": "integer"
},
"length": {
"type": "integer"
},
"msgType": {
"type": "integer"
},
"nickname": {
"type": "string"
},
"roomId": {
"type": "string",
"index": "not_analyzed"
},
"shareMsg": {
"properties": {
"appid": {
"type": "string",
"index": "not_analyzed"
},
"coverUrl": {
"type": "string",
"index": "not_analyzed"
},
"des": {
"type": "string"
},
"sourceId": {
"type": "string",
"index": "not_analyzed"
},
"sourceName": {
"type": "string"
},
"title": {
"type": "string"
},
"type": {
"type": "integer"
},
"url": {
"type": "string",
"index": "not_analyzed"
}
}
},
"wxUserId": {
"type": "string",
"index": "not_analyzed"
}
}
}
请求localhost:9200/xxx/_analyze?field=nickname&text=我爱中国,xxx为index的名称,field为任意类型为string的字段,text为希望分词的内容,得到
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "爱",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
}
]
}
去掉elasticsearch.yml中的index.analysis.analyzer.default.type : "ik",重启,在此请求localhost:9200/xxx/_analyze?field=nickname&text=我爱中国,得到
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "",
"position": 0
},
{
"token": "爱",
"start_offset": 1,
"end_offset": 2,
"type": "",
"position": 1
},
{
"token": "中",
"start_offset": 2,
"end_offset": 3,
"type": "",
"position": 2
},
{
"token": "国",
"start_offset": 3,
"end_offset": 4,
"type": "",
"position": 3
}
]
}
结果分析:es自带的默认分词器对中文支持不友好,只是简单的分割成单个汉字,ik则更友好,在elasticsearch.yml配置index.analysis.analyzer.default.type : "ik",可把ik配置成默认的分词器。