python爬虫--自定义爬取网站数据并进行可视化分析
今天写了一个爬虫,爬取了豆瓣网和腾讯网上一些信息,然后又用python自带的tkinter库制作了一个图形化界面,下面时代码和思路。
**代码下载地址:**https://download.csdn.net/download/weixin_43866709/11049544
思路
(1)为了用户更好的操作,先用pythonGUI编程设计出一个界面。
(2)编写爬虫代码,以豆瓣网为例,思考自己所需要的数据资源,并以此为基础设计自己的爬虫程序。
(3)分析网页前端代码,找出数据所在的标签,并通过正则表达式或者Xpath匹配出想要的数据。
(4)应用python第三方库Request,伪装成浏览器发送请求,获取豆瓣网页面。
(5)用提前编写好的匹配规则代码匹配出想要爬取的数据,并将这些数据保存起来。
(6)通过jieba分词库对数据进行处理,再通过scipy库对数据进行分析,最后在使用matplotlib,wordcloud库对处理结果进行展示。
设计方案:
1.界面设计:
这个界面使用python自带的tkinter库绘制,考虑到要让用户可以自定义输入想要爬取的网站,还要让用户看到爬取日志以及数据处理结果,使用到该库中的自定义输入框,文本框和画布,自定义输入框用于用户输入网址,文本框用于同步爬取日志,画布用来展示词云图。除此之外,还要添加几个必要的按钮,包括爬虫开始按钮,生成图片按钮,还有退出程序按钮。
具体代码如下:
# 创建空白窗口,作为主载体
# root = tkinter.Tk()
self.root.title('爬虫工具')
# 窗口的大小,后面的加号是窗口在整个屏幕的位置
self.root.geometry('1068x715+10+10')
# 创建菜单
menubar = tkinter.Menu(self.root)
fmenu = tkinter.Menu(menubar)
# for each in ['新建', '打开', '保存', '另存为', '退出']:
fmenu.add_command(label='新建')
fmenu.add_command(label='打开')
fmenu.add_command(label='保存')
fmenu.add_command(label='另存为')
fmenu.add_command(label='退出', command=self.root.quit, accelerator='(Ctrl+Q)')
rmenu = tkinter.Menu(menubar)
# for each in ['运行爬虫', '生成图片']:
rmenu.add_command(label='运行爬虫', command=self.douban_comments, accelerator='(F11)')
rmenu.add_command(label='生成图片', command=self.make_image, accelerator='(F12)')
amenu = tkinter.Menu(menubar)
for each in ['版权信息', '联系我们']:
amenu.add_command(label=each)
menubar.add_cascade(label='文件', menu=fmenu)
menubar.add_cascade(label='运行', menu=rmenu)
menubar.add_cascade(label='关于', menu=amenu)
self.root['menu'] = menubar
# 标签控件,窗口中放置文本组件
tkinter.Label(self.root, text='请输入url:', font=("华文行楷", 20), fg='black').grid(row=0, column=0)
# 定位 pack包 place位置 grid是网格式的布局
tkinter.Label(self.root, text='输出结果:', font=("宋体", 20), fg='black').grid(row=1, column=12)
tkinter.Label(self.root, text='爬取日志:', font=("宋体", 20), fg='black').grid(row=2, column=0)
# Entry是可输入文本框
# url_input = tkinter.Entry(self.root, font=("微软雅黑", 15))
# url_input.grid(row=0, column=1)
# 下拉框
# StringVar是Tk库内部定义的字符串变量类型,在这里用于管理部件上面的字符;不过一般用在按钮button上。改变StringVar,按钮上的文字也随之改变。
number = tkinter.StringVar()
url_input = tkinter.ttk.Combobox(self.root, width=26, textvariable=number)
# 设置下拉列表的值
url_input['values'] = ('https://hr.tencent.com', 'https://book.douban.com')
url_input.grid(column=1, row=0)
# tkinter.Label(self.root, text='腾讯网url: https://hr.tencent.com', font=("微软雅黑", 10), fg='black').grid(row=2, column=1)
# tkinter.Label(self.root, text='豆瓣网url: https://book.douban.com', font=("微软雅黑", 10), fg='black').grid(row=1, column=1)
# 文本控件,打印日志
log_text = tkinter.Text(self.root, font=('微软雅黑', 15), width=35, height=20)
# columnspan组件所跨越的列数
log_text.grid(row=4, column=0, rowspan=9, columnspan=10)
# result_text = tkinter.Canvas(self.root, width=45, height=22)
result_text = tkinter.Canvas(self.root, bg='white', width=550, height=600)
result_text.grid(row=2, column=12, rowspan=15, columnspan=10)
# 设置按钮 sticky对齐方式,N S W E
tkinter.button = tkinter.Button(self.root, text='开始', font=("微软雅黑", 15), command=self.douban_comments).grid(row=13, column=0, sticky=tkinter.W)
tkinter.button = tkinter.Button(self.root, text='退出', font=("微软雅黑", 15), command=self.root.quit).grid(row=13, column=10, sticky=tkinter.E)
# 创建滚动条
log_text_scrollbar_y = tkinter.Scrollbar(self.root)
log_text_scrollbar_y.config(command=log_text.yview)
log_text.config(yscrollcommand=log_text_scrollbar_y.set)
log_text_scrollbar_y.grid(row=3, column=10, rowspan=9, sticky='NS')
# 使得窗口一直存在
tkinter.mainloop()
运行效果:
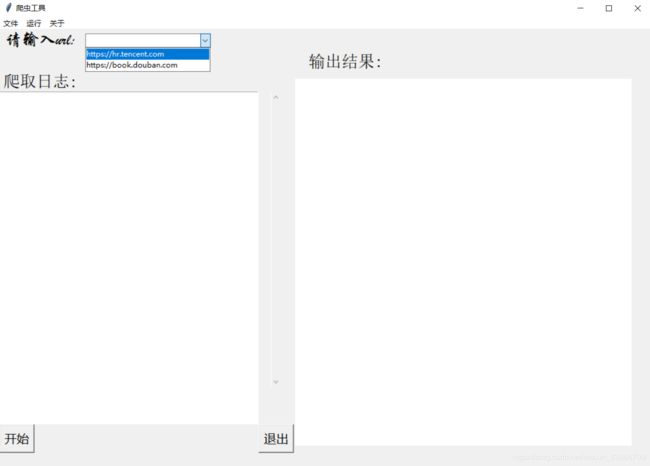
2.爬取数据
爬虫最主要的处理对象就是URL,它根据URI地址取得所需要的文件内容,然后对它进行进一步的处理。因此,准确地理解URL对理解网络爬虫至关重要。
URL是URI的一个子集。它是Uni form Resource Locator的缩写,译为“统一资源定位符”。通俗地说,URL是Internet.上描述信息资源的字符串,主要用在各种WW客户程序和服务器程序上。采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。URL的格式由三部分组成:
①第一部分是协议(或称为服务方式)。
②第二部分是存有该资源的主机IP地址(有时也包括端口号)。③第三部分是主机资源的具体地址,如目录和文件名等。第一部分和第二部分用“//”符号隔开,第二部分和第三部分用“/”符号隔开。
第一部分和第二部分是不可缺少的,第三部分有时可以省略。
发送请求获取响应文件我们使用的是request库,requests库是一个简洁且简单的HTTP请求的第三方库,它的优点是程序编写过程更接近正常URL访问过程。
具体代码如下:
headers = {'User-Agent': Spider.ua.random}
# proxies = main()
# 豆瓣网top250书籍首页
# url = "https://book.douban.com"
url = url_input.get()
if url == 'https://book.douban.com':
for i in range(0, 1):
urls = url + '/top250?start=' + 'str(i*25)'
html = requests.get(urls, headers=headers).text
3.解析网页(本文使用Xpath,也可使用正则表达式,bs4等)
XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作为一个通用的、介于XPointer与XSL间的语法模型。但是XPath很快的被开发者采用来当作小型查询语言,XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。路径表达式是从一个XML节点(当前的上下文节点)到另一个节点、或一组节点的书面步骤顺序。这些步骤以“/”字符分开,每一步有三个构成成分:
轴描述(用最直接的方式接近目标节点)
节点测试(用于筛选节点位置和名称)
节点描述(用于筛选节点的属性和子节点特征)
一般情况下,我们使用简写后的语法。虽然完整的轴描述是一种更加贴近人类语言,利用自然语言的单词和语法来书写的描述方式,但是相比之下也更加啰嗦。
具体代码如下:
page = etree.HTML(html)
book_urls_list = page.xpath('//tr[@class="item"]/td/div/a/@href')
book_name_list = page.xpath('//tr[@class="item"]/td/div/a/@title')
4.数据处理
(1)首先将爬取下来的数据存储成json文件,代码如下:
with open('douban.txt', 'a+', encoding='utf-8') as f:
for s in pattern:
# print(s, type(s))
f.write(str(s))
(2)使用jieba库对数据进行分词,在分词时对一些字符串忽略掉,代码如下:
stop_words = set(line.strip() for line in open('stopwords.txt', encoding='utf-8'))
commentlist = []
for subject in comment_subjects:
if subject.isspace():
continue
# segment words line by line
word_list = pseg.cut(subject)
for word, flag in word_list:
if word not in stop_words and flag == 'n':
commentlist.append(word)
(3)使用科学计算库scipy,2D绘图库matploylib和wordcloud库生成词云图,直观的向用户展示出热门的词汇,代码如下:
d = path.dirname(__file__)
timg_image = imread(path.join(d, "timg.png"))
content = ' '.join(commentlist)
wordcloud = WordCloud(font_path='simhei.ttf', background_color="grey", mask=timg_image, max_words=40).generate(content)
# Display the generated image:
plt.imshow(wordcloud)
plt.axis("off")
wordcloud.to_file('wordcloud.gif')
# plt.show()
# wordcloud_image = Image.open('wordcloud.gif')
wordcloud_images = tkinter.PhotoImage(file='wordcloud.gif')
result_text.create_image(50, 50, anchor=tkinter.NW, image=wordcloud_images)
源代码
import jieba.posseg as pseg
import matplotlib.pyplot as plt
from os import path
import requests
from scipy.misc import imread
from wordcloud import WordCloud
from bs4 import BeautifulSoup
import time
from lxml import etree
import random
from fake_useragent import UserAgent
import tkinter
from tkinter import ttk
# from PIL import Image
class Spider:
ua = UserAgent(verify_ssl=False)
def __init__(self):
self.root = tkinter.Tk()
def douban_comments(self):
headers = {'User-Agent': Spider.ua.random}
# proxies = main()
# 豆瓣网top250书籍首页
# url = "https://book.douban.com"
url = url_input.get()
if url == 'https://book.douban.com':
for i in range(0, 1):
urls = url + '/top250?start=' + 'str(i*25)'
html = requests.get(urls, headers=headers).text
page = etree.HTML(html)
book_urls_list = page.xpath('//tr[@class="item"]/td/div/a/@href')
book_name_list = page.xpath('//tr[@class="item"]/td/div/a/@title')
for book_name in book_name_list:
log_msg1 = '匹配到《' + str(book_name) + '》' + '\n'
log_text.insert(tkinter.END, log_msg1)
log_text.see(tkinter.END)
log_text.update()
print(book_urls_list)
# 得到每一本书对应的评论url
for book_urls in book_urls_list:
comments_urls = book_urls + 'comments/hot?p='
print(comments_urls)
# 获取每一本书前一百页的评论url
for j in range(1, 2):
comments_url = comments_urls + 'str(j)'
comments = requests.get(comments_url, headers=headers)
# print('开始爬取第{}页评论.'.format(j))
log_msg2 = '开始爬取第{}页评论.'.format(j) + '\n'
log_text.insert(tkinter.END, log_msg2)
log_text.see(tkinter.END)
log_text.update()
comments_soup = BeautifulSoup(comments.text, 'lxml')
pattern = comments_soup.find_all('p', 'comment-content')
with open('douban.txt', 'a+', encoding='utf-8') as f:
for s in pattern:
# print(s, type(s))
f.write(str(s))
j = j + 1
time.sleep(1)
i = i + 1
time.sleep(1)
spi_end = '--------爬取完成--------' + '\n'
log_text.insert(tkinter.END, spi_end)
log_text.see(tkinter.END)
log_text.update()
elif url == 'https://hr.tencent.com':
self.tencent_position()
else:
self.error_msg()
@staticmethod
def tencent_position():
headers = {'User-Agent': Spider.ua.random}
url = url_input.get()
for i in range(0, 20):
urls = url + '/position.php?&start=' + 'str(i*10)'
html = requests.get(urls, headers=headers).text
log_msg2 = '开始爬取第{}页职位.'.format(i) + '\n'
log_text.insert(tkinter.END, log_msg2)
log_text.see(tkinter.END)
log_text.update()
page = etree.HTML(html)
for position in page.xpath('//tr[@class="even"]/td[1]/a/text() | //tr[@class="odd"]/td[1]/a/text()'):
with open('tencent.txt', 'a+', encoding='utf-8') as f:
f.write(str(position))
i = i + 1
time.sleep(1)
spi_end = '--------爬取完成--------' + '\n'
log_text.insert(tkinter.END, spi_end)
log_text.see(tkinter.END)
log_text.update()
@staticmethod
def error_msg():
msg = '请先输入正确的url~' + '\n'
log_text.insert(tkinter.END, msg)
log_text.see(tkinter.END)
log_text.update()
def make_image(self):
make_image_text = '============================' + '\n' + '正在生成图片...请稍等...' + '\n'
log_text.insert(tkinter.END, make_image_text)
log_text.see(tkinter.END)
log_text.update()
global wordcloud_images
url = url_input.get()
if url == 'https://book.douban.com':
with open('douban.txt', 'r', encoding='utf-8') as f:
comment_subjects = f.readlines()
stop_words = set(line.strip() for line in open('stopwords.txt', encoding='utf-8'))
commentlist = []
for subject in comment_subjects:
if subject.isspace():
continue
# segment words line by line
word_list = pseg.cut(subject)
for word, flag in word_list:
if word not in stop_words and flag == 'n':
commentlist.append(word)
d = path.dirname(__file__)
timg_image = imread(path.join(d, "timg.png"))
content = ' '.join(commentlist)
wordcloud = ontWordCloud(f_path='simhei.ttf', background_color="grey", mask=timg_image, max_words=40).generate(content)
# Display the generated image:
plt.imshow(wordcloud)
plt.axis("off")
wordcloud.to_file('wordcloud.gif')
# plt.show()
# wordcloud_image = Image.open('wordcloud.gif')
wordcloud_images = tkinter.PhotoImage(file='wordcloud.gif')
result_text.create_image(50, 50, anchor=tkinter.NW, image=wordcloud_images)
elif url == 'https://hr.tencent.com':
with open('tencent.txt', 'r', encoding='utf-8') as f:
comment_subjects = f.readlines()
stop_words = set(line.strip() for line in open('stopwords.txt', encoding='utf-8'))
commentlist = []
for subject in comment_subjects:
if subject.isspace():
continue
# segment words line by line
word_list = pseg.cut(subject)
for word, flag in word_list:
if word not in stop_words and flag == 'n':
commentlist.append(word)
d = path.dirname(__file__)
timg_image = imread(path.join(d, "timg.png"))
content = ' '.join(commentlist)
wordcloud = WordCloud(font_path='simhei.ttf', background_color="grey", mask=timg_image, max_words=40).generate(content)
# Display the generated image:
plt.imshow(wordcloud)
plt.axis("off")
wordcloud.to_file('wordcloud_tencent.gif')
# plt.show()
# wordcloud_image = Image.open('wordcloud_tencent.gif')
wordcloud_images = tkinter.PhotoImage(file='wordcloud_tencent.gif')
result_text.create_image(50, 50, anchor=tkinter.NW, image=wordcloud_images)
else:
self.error_msg()
def main(self):
global url_input, log_text, result_text
# 创建空白窗口,作为主载体
# root = tkinter.Tk()
self.root.title('爬虫工具')
# 窗口的大小,后面的加号是窗口在整个屏幕的位置
self.root.geometry('1068x715+10+10')
# 创建菜单
menubar = tkinter.Menu(self.root)
fmenu = tkinter.Menu(menubar)
# for each in ['新建', '打开', '保存', '另存为', '退出']:
fmenu.add_command(label='新建')
fmenu.add_command(label='打开')
fmenu.add_command(label='保存')
fmenu.add_command(label='另存为')
fmenu.add_command(label='退出', command=self.root.quit, accelerator='(Ctrl+Q)')
rmenu = tkinter.Menu(menubar)
# for each in ['运行爬虫', '生成图片']:
rmenu.add_command(label='运行爬虫', command=self.douban_comments, accelerator='(F11)')
rmenu.add_command(label='生成图片', command=self.make_image, accelerator='(F12)')
amenu = tkinter.Menu(menubar)
for each in ['版权信息', '联系我们']:
amenu.add_command(label=each)
menubar.add_cascade(label='文件', menu=fmenu)
menubar.add_cascade(label='运行', menu=rmenu)
menubar.add_cascade(label='关于', menu=amenu)
self.root['menu'] = menubar
# 标签控件,窗口中放置文本组件
tkinter.Label(self.root, text='请输入url:', font=("华文行楷", 20), fg='black').grid(row=0, column=0)
# 定位 pack包 place位置 grid是网格式的布局
tkinter.Label(self.root, text='输出结果:', font=("宋体", 20), fg='black').grid(row=1, column=12)
tkinter.Label(self.root, text='爬取日志:', font=("宋体", 20), fg='black').grid(row=2, column=0)
# Entry是可输入文本框
# url_input = tkinter.Entry(self.root, font=("微软雅黑", 15))
# url_input.grid(row=0, column=1)
# 下拉框
# StringVar是Tk库内部定义的字符串变量类型,在这里用于管理部件上面的字符;不过一般用在按钮button上。改变StringVar,按钮上的文字也随之改变。
number = tkinter.StringVar()
url_input = tkinter.ttk.Combobox(self.root, width=26, textvariable=number)
# 设置下拉列表的值
url_input['values'] = ('https://hr.tencent.com', 'https://book.douban.com')
url_input.grid(column=1, row=0)
# tkinter.Label(self.root, text='腾讯网url: https://hr.tencent.com', font=("微软雅黑", 10), fg='black').grid(row=2, column=1)
# tkinter.Label(self.root, text='豆瓣网url: https://book.douban.com', font=("微软雅黑", 10), fg='black').grid(row=1, column=1)
# 文本控件,打印日志
log_text = tkinter.Text(self.root, font=('微软雅黑', 15), width=35, height=20)
# columnspan组件所跨越的列数
log_text.grid(row=4, column=0, rowspan=9, columnspan=10)
# result_text = tkinter.Canvas(self.root, width=45, height=22)
result_text = tkinter.Canvas(self.root, bg='white', width=550, height=600)
result_text.grid(row=2, column=12, rowspan=15, columnspan=10)
# 设置按钮 sticky对齐方式,N S W E
tkinter.button = tkinter.Button(self.root, text='开始', font=("微软雅黑", 15), command=self.douban_comments).grid(row=13, column=0, sticky=tkinter.W)
tkinter.button = tkinter.Button(self.root, text='退出', font=("微软雅黑", 15), command=self.root.quit).grid(row=13, column=10, sticky=tkinter.E)
# 创建滚动条
log_text_scrollbar_y = tkinter.Scrollbar(self.root)
log_text_scrollbar_y.config(command=log_text.yview)
log_text.config(yscrollcommand=log_text_scrollbar_y.set)
log_text_scrollbar_y.grid(row=3, column=10, rowspan=9, sticky='NS')
# 使得窗口一直存在
tkinter.mainloop()
if __name__ == "__main__":
spider = Spider()
spider.main()
运行效果
