Python实战案例:我们对共享单车的需求有多大?
现如今,共享单车在生活中可谓处处可见,那么它的租赁需求是多少呢?今天我们就基于美国华盛顿共享单车的租赁数据,利用Python和可视化对租赁需求进行预测。
01
数据来源及背景
该数据集是美国华盛顿共享单车租赁数据, 其中有训练集和测试集, 在训练集中包含10886个样本以及12个字段, 通过训练集上自行车租赁数据对美国华盛顿共享单车租赁需求进行预测。数据集是笔者在外网爬取的,为了方便大家使用,可以在文末添加职场老师免费领取。
02
数据探索分析
1. 读取数据

通过以上可以得知数据维度10886行X12列, 除了第一列其它均显示为数值, 具体的格式还要进一步查看, 对于各列的解释也放入下一环节。
2. 查看数据整体信息
df.info()RangeIndex: 10886 entries, 0 to 10885Data columns (total 12 columns):datetime 10886 non-null object #时间和日期season 10886 non-null int64 #季节, 1 =春季,2 =夏季,3 =秋季,4 =冬季 holiday 10886 non-null int64 #是否是假期, 1=是, 0=否workingday 10886 non-null int64 #是否是工作日, 1=是, 0=否weather 10886 non-null int64 #天气,1:晴朗,很少有云,部分多云,部分多云; 2:雾+多云,雾+碎云,雾+少云,雾; 3:小雪,小雨+雷雨+散云,小雨+散云; 4:大雨+冰块+雷暴+雾,雪+雾temp 10886 non-null float64 #温度atemp 10886 non-null float64 #体感温度humidity 10886 non-null int64 #相对湿度windspeed 10886 non-null float64 #风速casual 10886 non-null int64 #未注册用户租赁数量registered 10886 non-null int64 #注册用户租赁数量count 10886 non-null int64 #所有用户租赁总数dtypes: float64(3), int64(8), object(1)memory usage: 1020.6+ KB
除了datetime为字符串型, 其他均为数值型, 且无缺失值。
3. 描述性统计
df.describe()
温度, 体表温度, 相对湿度, 风速均近似对称分布, 而非注册用户, 注册用户,以及总数均右偏分布。

4. 偏态, 峰态
for i in range(5, 12): name = df.columns[i] print('{0}偏态系数为 {1}, 峰态系数为 {2}'.format(name, df[name].skew(), df[name].kurt()))temp偏态系数为 0.003690844422472008, 峰态系数为 -0.9145302637630794atemp偏态系数为 -0.10255951346908665, 峰态系数为 -0.8500756471754651humidity偏态系数为 -0.08633518364548581, 峰态系数为 -0.7598175375208864windspeed偏态系数为 0.5887665265853944, 峰态系数为 0.6301328693364932casual偏态系数为 2.4957483979812567, 峰态系数为 7.551629305632764registered偏态系数为 1.5248045868182296, 峰态系数为 2.6260809999210672count偏态系数为 1.2420662117180776, 峰态系数为 1.3000929518398334
- temp, atemp, humidity低度偏态
- windspeed中度偏态
- casual, registered, count高度偏态
- temp, atemp, humidity为平峰分布
- windspeed,casual, registered, count为尖峰分布
03
数据预处理
由于没有缺失值, 不用处理缺失值, 看看有没有重复值。
1. 检查重复值
print('未去重: ', df.shape)print('去重: ', df.drop_duplicates().shape)未去重: (10886, 12)去重: (10886, 12)
没有重复项, 看看异常值。
2. 异常值
通过箱线图查看异常值
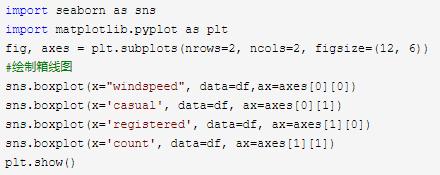
租赁数量会受小时的影响, 比如说上班高峰期等, 故在这里先不处理异常值。

3. 数据加工
转换"时间和日期"的格式, 并提取出小时, 日, 月, 年。


04
可视化分析
1. 日期和总租赁数量

2012年相比2011年租赁数量有所增长, 且波动幅度相类似。
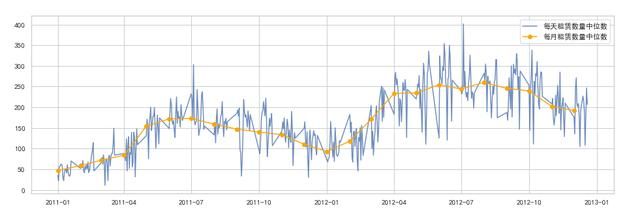
2. 月份和总租赁数量

与上图的波动幅度基本一致, 另外每个月均有不同程度的离群值。

3. 季节和总租赁数量
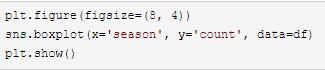
就中位数来说, 秋季是最多的, 春季最少且离群值较多。
4. 星期几和租赁数量
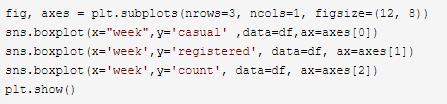
就中位数来说, 未注册用户周六和周日较多, 而注册用户则周内较多, 对应的总数也是周内较多, 且周内在总数的离群值较多(0代表周一, 6代表周日)

5. 节假日, 工作日和总租赁数量
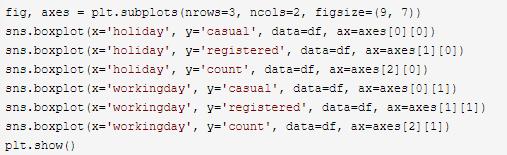
- 未注册用户: 在节假日较多, 在工作日较少
- 注册用户: 在节假日较少, 在工作日较多
总的来说, 节假日租赁较少, 工作日租赁较多, 初步猜测多数未注册用户租赁自行车是用来非工作日出游, 而多数注册用户则是工作日用来上班或者上学。
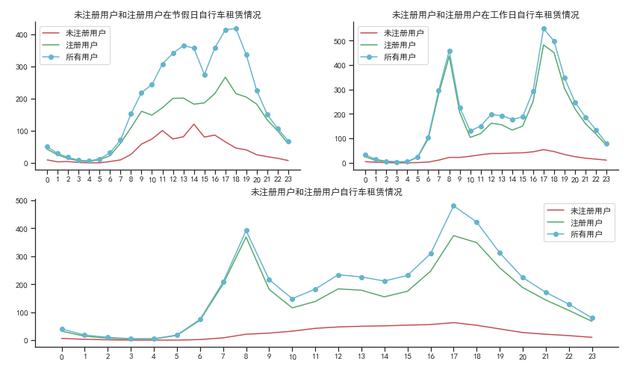
6. 小时和总租赁数量的关系

- 在节假日, 未注册用户和注册用户走势相接近, 不过未注册用户最高峰在14点, 而注册用户则是17点
- 在工作日, 注册用户呈现出双峰走势, 在8点和17点均为用车高峰期, 而这正是上下班或者上下学高峰期
- 对于注册用户来说, 17点在节假日和工作日均为高峰期, 说明部分用户在节假日可能未必休假
7. 天气和总租赁数量

就中位数而言未注册用户和注册用户均表现为: 在工作日和非工作日租赁数量均随着天气的恶劣而减少, 特别地, 当天气为大雨大雪天(4)且非工作日均没有自行车租赁。
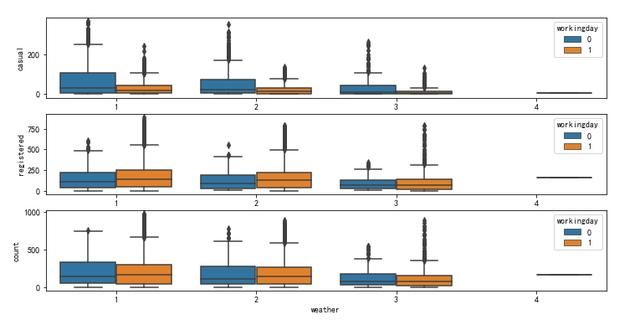
从图上可以看出, 大雨大雪天只有一个数据, 我们看看原数据。
df[df.weather==4]
只有在2012年1月9日18时为大雨大雪天, 说明天气是突然变化的, 部分用户可能因为没有看天气预报而租赁自行车, 当然也有其他原因。
![]()
另外, 发现1月份是春季, 看看它的季节划分规则。
sns.boxplot(x='season', y='month',data=df)
123为春季, 456为夏季, 789为秋季...
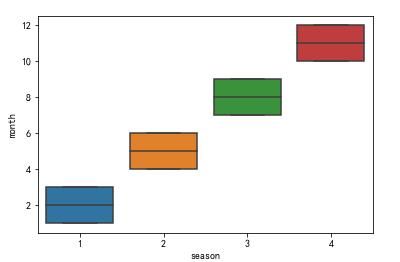
季节的划分通常和纬度相关, 而这份数据是用来预测美国华盛顿的租赁数量, 且美国和我国的纬度基本一样, 故按照345春节, 678夏季..这个规则来重新划分。

- 第一个图是调整之前的, 就中位数来说, 春季气温最低, 秋季气温最高
- 第二个图是调整之后的, 就中位数来说, 冬季气温最低, 夏季气温最高

显然第二张的图的结果较符合常理, 故删除另外那一列。
df.drop('season', axis=1, inplace=True)df.shape(10886, 16)
8. 其他变量和总租赁数量的关系
这里我直接使用利用seaborn的pairplot绘制剩余的温度, 体感温度, 相对湿度, 风速这四个连续变量与未注册用户和注册用户的关系在一张图上。
sns.pairplot(df[['temp', 'atemp', 'humidity', 'windspeed', 'casual', 'registered', 'count']])
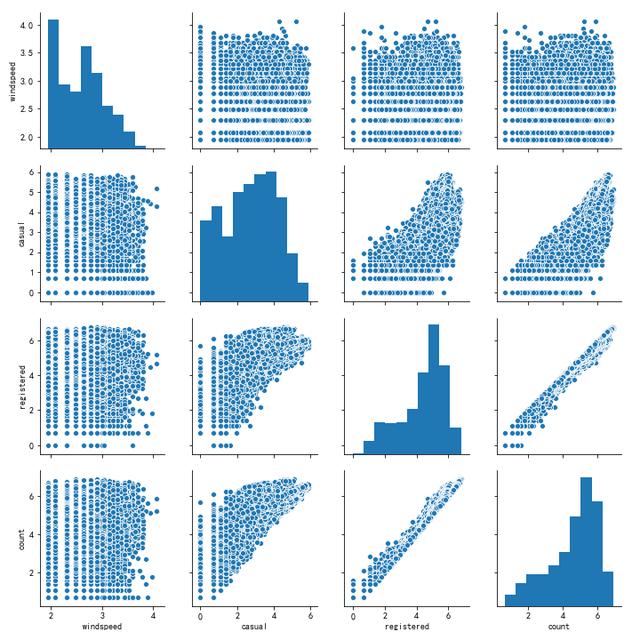
为了方便纵览全局, 我将图片尺寸缩小, 如下图所示. 纵轴从上往下依次是温度, 体感温度, 相对湿度, 风速, 未注册用户, 注册用户, 所有用户, 横轴从左往右是同样的顺序。

从图上可以看出, 温度和体感温度分别与未注册用户, 注册用户, 所有用户均有一定程度的正相关, 而相对湿度和风速与之呈现一定程度的负相关。另外, 其他变量之间也有不同程度的相关关系。
另外, 第四列(风速)在散点图中间有明显的间隙. 需要揪出这一块来看看。
df['windspeed']0 0.00001 0.00002 0.0000 ... 10883 15.001310884 6.003210885 8.9981Name: windspeed, Length: 10886, dtype: float64
风速为0, 这明显不合理, 把其当成缺失值来处理。我这里选择的是向后填充。
df.loc[df.windspeed == 0, 'windspeed'] = np.nandf.fillna(method='bfill', inplace=True)df.windspeed.isnull().sum()0
9. 相关矩阵
由于多个变量不满足正态分布, 对其进行对数变换。

经过对数变换之后, 注册用户和所有用户的租赁数量和正态还是相差较大, 故在计算相关系数时选择spearman相关系数。

均有不同程度的相关程度, 其中, temp和atemp高度相关, count和registered高度相关, 数值均达到0.99。

05
回归分析
岭回归和Lasso回归是加了正则化项的线性回归, 下面将分别构造三个模型:岭回归、Lasso回归和线性回归。
1. 岭回归
(1)划分数据集

(2)模型训练
from sklearn.linear_model import Ridge#这里的alpha指的是正则化项参数, 初始先设置为1.rd = Ridge(alpha=1)rd.fit(X_train, y_train)print(rd.coef_)print(rd.intercept_)[ 0.00770067 -0.00034301 0.0039196 0.00818243 0.03635549 -0.01558927 0.09080788 0.0971406 0.02791812 0.06114358 -0.00099811]2.6840271343740754
通过前面我们知道, 正则化项参数对结果的影响较大, 下一步我们就通过岭迹图来选择正则化参数。

通过图像可以看出, 当alpha为107时所有变量岭迹趋于稳定。按照岭迹法应当取alpha=107。

由于是通过肉眼观察的, 其不一定是最佳, 采用另外一种方式: 交叉验证的岭回归。
from sklearn.linear_model import RidgeCVfrom sklearn import metricsrd_cv = RidgeCV(alphas=alphas, cv=10, scoring='r2')rd_cv.fit(X_train, y_train)rd_cv.alpha_805.0291812295973
最后选出的最佳正则化项参数为805.03, 然后用这个参数进行模型训练
rd = Ridge(alpha=805.0291812295973) #, fit_intercept=Falserd.fit(X_train, y_train)print(rd.coef_)print(rd.intercept_)[ 0.00074612 -0.00382265 0.00532093 0.01100823 0.03375475 -0.01582157 0.0584206 0.09708992 0.02639369 0.0604242 -0.00116086]2.7977274604845856
(3)模型预测

- 训练集RMSE: 1.0348076524200298评分: 0.46691272323469246
- 测试集RMSE: 1.0508046977499312评分: 0.45801571689420706
2. Lasso回归
(1)模型训练

通过Lasso回归曲线, 可以看出大致在10附近所有变量趋于稳定

同样采用交叉验证选择Lasso回归最优正则化项参数

用这个参数重新训练模型
Las = Lasso(alpha=0.005074705239490466) #, fit_intercept=FalseLas.fit(X_train, y_train)print(Las.coef_)print(Las.intercept_)[ 0. -0. 0. 0.01001827 0.03467474 -0.01570339 0.06202352 0.09721864 0.02632133 0.06032038 -0. ]2.7808303982442952
对比岭回归可以发现, 这里的回归系数中有0存在, 也就是舍弃了holiday, workingday, weather和group_season这四个自变量。

- 训练集RMSE: 1.0347988070045209评分: 0.4669218367318746
- 测试集RMSE: 1.050818996520012评分: 0.45800096674816204
(2)线性回归
最后,再用传统的线性回归进行预测, 从而对比三者之间的差异。
from sklearn.linear_model import LinearRegression#训练线性回归模型LR = LinearRegression()LR.fit(X_train, y_train)print(LR.coef_)print(LR.intercept_)#分别预测训练集和测试集, 并计算均方根误差和拟合优度y_train_pred = LR.predict(X_train)y_test_pred = LR.predict(X_test)y_train_rmse = sqrt(metrics.mean_squared_error(y_train, y_train_pred))y_train_score = LR.score(X_train, y_train)y_test_rmse = sqrt(metrics.mean_squared_error(y_test, y_test_pred))y_test_score = LR.score(X_test, y_test)print('训练集RMSE: {0}, 评分: {1}'.format(y_train_rmse, y_train_score))print('测试集RMSE: {0}, 评分: {1}'.format(y_test_rmse, y_test_score))[ 0.00775915 -0.00032048 0.00391537 0.00817703 0.03636054 -0.01558878 0.09087069 0.09714058 0.02792397 0.06114454 -0.00099731]2.6837869701964014
- 训练集RMSE: 1.0347173340121176评分: 0.46700577529675036
- 测试集RMSE: 1.0510323073614725评分: 0.45778089839236114
06
总结
就测试集和训练集均方根误差之差来说, 线性回归最大, 岭回归最小, 另外回归在测试集的拟合优度最大, 总体来说, 岭回归在此数据集上表现略优。
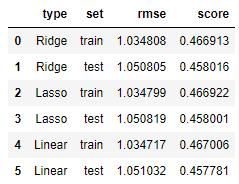
就这个评分来说, 以上模型还不是很好, 还需要学习其他模型, 比如决策树, 随机森林, 神经网络等。
源码获取私信小编01哈!