价值十个亿的淘宝搜索功能
看到这标题,是不是有小伙伴忍不住点进来看看?
标题党~~ 不不不,咱还是来点干货

先来看看淘宝搜索的分类
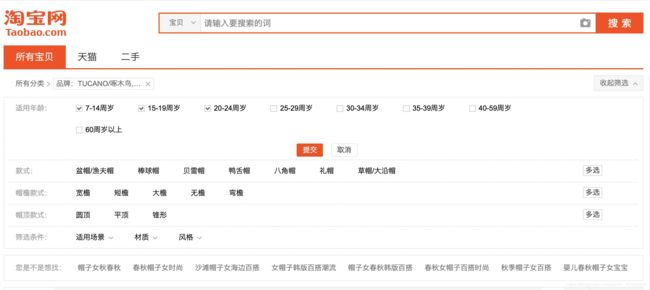
可以支持分类多选,即如下报文格式:
{
"品牌":[
"啄木鸟",
"南极人"
],
"适用年龄":[
"7-14周岁",
"15-19周岁",
"20-24周岁"
]
}
再想一下,搜索的结果是什么,需要满足如下条件:
1. 必须同时属于两大分类,即交集 ---- “品牌”和“适用年龄”必须同时拥有的
2. 每个分类里面的标签又必须同时满足,即并集 ---- “啄木鸟”和“南极人”至少有一个即可
带着这些问题和总结,我们来做一些测试…
先模拟建一个物品及分类标签关系表goods_tag
CREATE TABLE `goods_tag` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`goods` varchar(64) NOT NULL COMMENT '商品',
`tag` varchar(64) NOT NULL COMMENT '标签',
`classify` varchar(64) NOT NULL COMMENT '分类',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='测试表';
模拟测试数据:
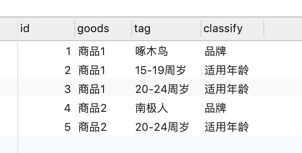
按照这个思路,我们写下我们的最常规脚本
select goods from goods_tag where classify = '品牌' and tag in ('啄木鸟', '南极人')
union
select goods from goods_tag where classify = '适用年龄' and tag in ('7-14周岁', '15-19周岁', '20-24周岁');
运行结果也达到预期效果:
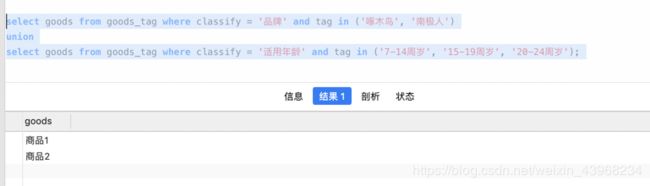

感觉貌似ok,但是我们来分析这个脚本
问题:如果给的条件较多,那是不是要拼接一个超级长的sql?
那么,是否有另外的更优解决办法呢?
分组查询!
但是分组查询也很讲究,首先我们可以对全部标签数据进行查询,然后对商品和分类进行分组
有没有聪明对小伙伴想到为啥要这样做?我们看下sql和结果
select goods, classify, count(1) from goods_tag
where tag in ('啄木鸟', '南极人', '7-14周岁', '15-19周岁', '20-24周岁')
group by goods, classify;
运行结果
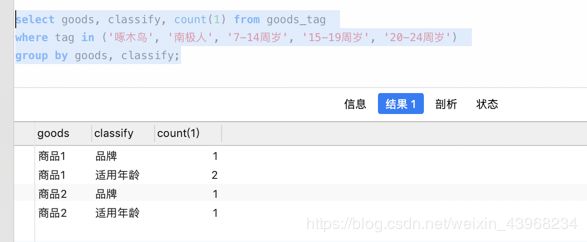
为什么要商品和分类分组?
就是因为我们要取得每个分类里面必须同时有这个商品!!!
带着这个目的,我们再做一次处理,得到如下sql
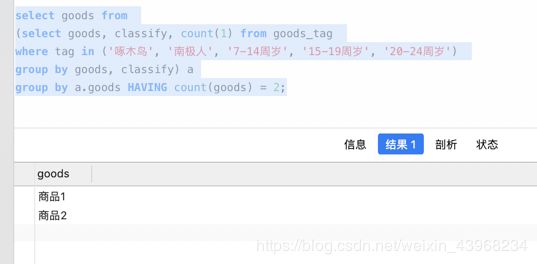
select goods from
(select goods, classify, count(1) from goods_tag
where tag in ('啄木鸟', '南极人', '7-14周岁', '15-19周岁', '20-24周岁')
group by goods, classify) a
group by a.goods HAVING count(goods) = 2;
运行结果
总结一下:
- 先对商品、分类进行分组
- 取得必须每个分类里面都有这个商品
- 大前提把所有标签的数据查出来(不用担心数据过大,因为最终会进行分页操作,想要学习如何进行大批量数据高效分页操作,可见如何将过亿订单数据实现毫秒级分页查询)
- 最后的等于2是动态参数, 这个是依赖传入了几个分类,这里就是等于多少
到了此处,基本核心sql就成型了,这个sql本身不复杂,但是想到这个也并不容易,还需要sql的一定基本功
可能会有小伙伴怀疑sql的准确性,大家可以多造一些测试数据去验证一下,各种场景都模拟一下
好了,价值十个亿的淘宝搜索功能就送给大家了,十亿能拿多少,还得看你们自己?