数据可视化--Superset使用示例
1.Superset的功能介绍
1、我们可以通过连接数据库,去对数据库中的单个表进行配置,展示出柱状图,折线图,饼图,气泡图,词汇云,数字,环状层次图,有向图,蛇形图,地图,平行坐标,热力图,箱线图,树状图,热力图,水平图等图,官网上是不可以操作多个表的,不过我们可以操作视图,也就是说在数据库建好视图,也可以在superset中给表新增一列进行展示。
2、配置好了我们想要的图表之后我们可以把它添加到仪盘表进行展示,还可以去配置缓存,来加速仪盘表的查询,不必要没次都去查询数据库。
3、我们可以查看进行查询表的sql,也可以把查询导出为json,csv文件。它有自己的sql编辑器,我们可以在里面来编写sql。
2.superset连接数据库
Superset支持多种的数据库连接,如MySQL,Oracle,Hive等,其连接方式如下:
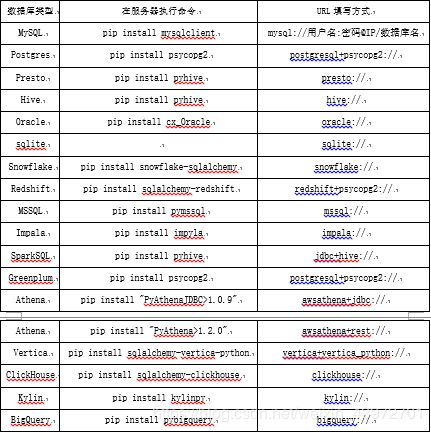
2.1superset连接MySQL
2.1.1安装MySQL客户端依赖
登录到部署superset服务器主机,执行命令:pip install mysqlclient
2.1.2配置mysql
进入superset的Web界面,点击sources下拉选项的Databases,如下图:
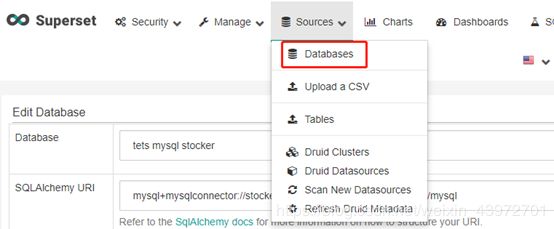
进入数据库界面,点击“+”按钮进入数据库连接界面,填写正确字段后保存,操作如下:

查看已经连接好的数据库

3.Superset操作数据库
经过上边的步骤就连接上了数据库,下边就可以进行数据的可视化操作了。首先点击SQL测试下拉菜单下的SQL编辑器按钮。如下图所示:

SQL语句的执行结果如下:

点击Visualize按钮进入数据可视化编辑窗口:

4.superset图形使用案例
4.1 Distribution – Bar Chart(分布-条形图)
案例需求:统计每个state的总人数,总女生人数,总男生人数。
SELECT state AS state,
SUM(num) AS “SUM(num)”,
SUM(sum_boys) AS “SUM(sum_boys)”,
SUM(sum_girls) AS “SUM(sum_girls)”
FROM birth_names
WHERE ds >= ‘1918-09-13 00:00:00.000000’
AND ds <= ‘2018-09-13 15:01:52.000000’
GROUP BY state
ORDER BY “SUM(num)” DESC
LIMIT 10000
OFFSET 0;
进入可视化界面,可按需求显示图形:
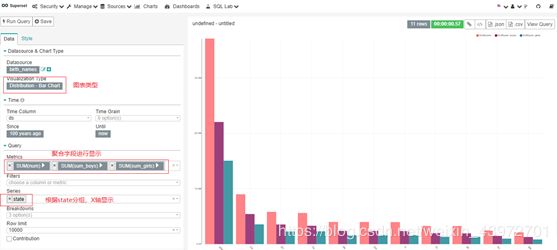
在图形的右上方有对图形的保存等一些操作:

图表的保存:

查看保存的图表:

4.2Table View – 表视图
需求1:根据name,gender分组,统计总人数。
SQL:
SELECT name AS name,
gender AS gender,
SUM(num) AS “SUM(num)”
FROM birth_names
WHERE ds >= ‘1918-09-13 00:00:00.000000’
AND ds <= ‘2018-09-13 15:18:24.000000’
GROUP BY name,gender
ORDER BY “SUM(num)” DESC
LIMIT 50
OFFSET 0;


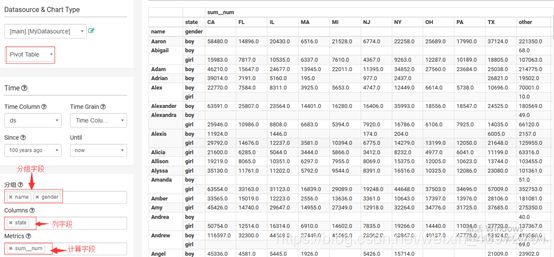
4.3Pivot Table – 数据透视表
数据透视表(Pivot Table)是一种交互式的表,可以进行某些计算,如求和与计数等。所进行的计算与数据跟数据透视表中的排列有关。
案例需求:按照name,gender分组,对每个state人数进行统计。
SQL:
SELECT gender AS gender,
state AS state,
name AS name,
sum(num) AS sum__num
FROM
(select *
from birth_names) AS expr_qry
WHERE ds >= ‘1917-07-05 18:25:21’
AND ds <= ‘2017-07-05 18:25:21’
GROUP BY gender,state,name
ORDER BY sum__num DESC LIMIT 50000
4.4Time Series – Line Chart – 时序线图
案例需求:查看每个state人数总数随时间的变化。
SQL:
SELECT state AS state,
ds AS timestamp,
sum(num) AS sum__num
FROM
(select *
from birth_names) AS expr_qry
INNER JOIN
(SELECT state AS state,
sum(num) AS sum__num
FROM
(select *
from birth_names) AS expr_qry
WHERE ds >= ‘1917-07-05 18:26:35’
AND ds <= ‘2017-07-05 18:26:35’
GROUP BY state
ORDER BY sum__num DESC LIMIT 50) AS anon_1 ON state = state__
WHERE ds >= ‘1917-07-05 18:26:35’
AND ds <= ‘2017-07-05 18:26:35’
GROUP BY state,ds
ORDER BY sum__num DESC LIMIT 50000
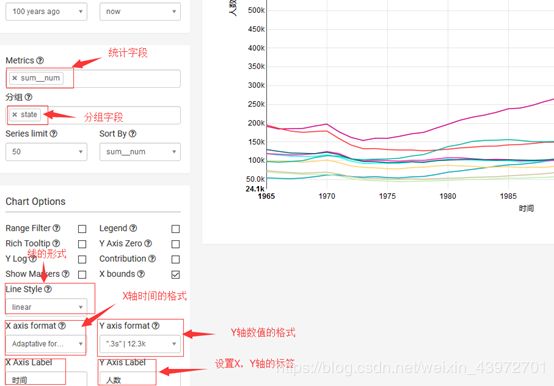
4.5Time Series – Stacked – 时序面积图
面积图强调数量随时间而变化的程度,也可用于引起人们对总值趋势的注意。例如,表示随时间而变化的产生的数据可以绘制在面积图中以强调总数据量。
案例需求:根据每个state每年的总人数的时序图-叠图。
SQL:
SELECT state AS state,
ds AS timestamp,
sum(num) AS sum__num
FROM
(select *
from birth_names) AS expr_qry
INNER JOIN
(SELECT state AS state,
sum(num) AS sum__num
FROM
(select *
from birth_names) AS expr_qry
WHERE ds >= ‘1917-07-05 18:27:06’
AND ds <= ‘2017-07-05 18:27:06’
GROUP BY state
ORDER BY sum__num DESC LIMIT 50) AS anon_1 ON state = state__
WHERE ds >= ‘1917-07-05 18:27:06’
AND ds <= ‘2017-07-05 18:27:06’
GROUP BY state,ds
ORDER BY sum__num DESC LIMIT 50000

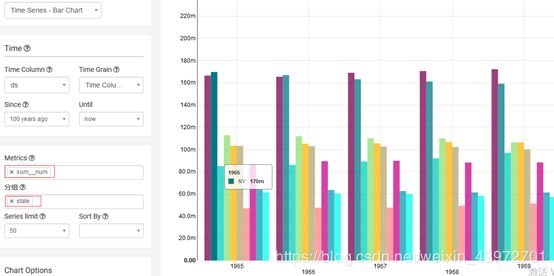
4.6Time Series – Bar Chart – 时序柱形图
案例需求:比较不同的年份每个state的人数差异的时序柱形图。
SQL:
SELECT state AS state,
ds AS timestamp,
sum(num) AS sum__num
FROM
(select *
from birth_names) AS expr_qry
INNER JOIN
(SELECT state AS state,
sum(num) AS sum__num
FROM
(select *
from birth_names) AS expr_qry
WHERE state NOT IN (‘other’)
AND ds >= ‘1917-07-05 18:28:57’
AND ds <= ‘2017-07-05 18:28:57’
GROUP BY state
ORDER BY sum__num DESC LIMIT 50) AS anon_1 ON state = state__
WHERE ds >= ‘1917-07-05 18:28:57’
AND ds <= ‘2017-07-05 18:28:57’
AND state NOT IN (‘other’)
GROUP BY state,ds
ORDER BY sum__num DESC LIMIT 50000
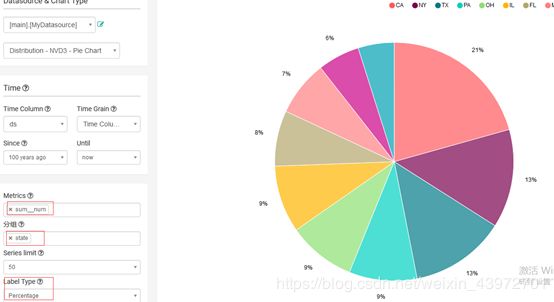
4.7Distribution – NVD3 - Pie Chart –饼图
案例:比较每个state的人数占总人数的比例。
SQL:
SELECT state AS state,
sum(num) AS sum__num
FROM
(select *
from birth_names) AS expr_qry
WHERE ds >= ‘1917-07-05 18:29:51’
AND ds <= ‘2017-07-05 18:29:51’
AND state NOT IN (‘other’)
GROUP BY state
ORDER BY sum__num DESC LIMIT 50000
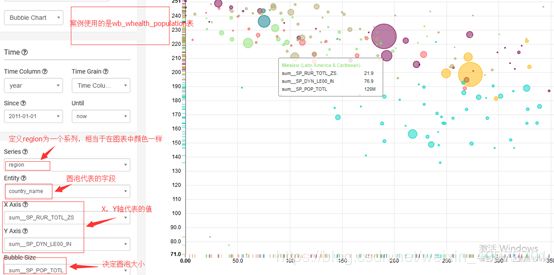
4.8Bubble Chart – 气泡图
SQL语句:
SELECT country_name AS country_name,
region AS region,
SUM(SP_POP_TOTL) AS sum__SP_POP_TOTL,
SUM(SP_RUR_TOTL_ZS) AS sum__SP_RUR_TOTL_ZS,
SUM(SP_DYN_LE00_IN) AS sum__SP_DYN_LE00_IN
FROM wb_health_population
WHERE year >= STR_TO_DATE(‘2011-01-01 00:00:00’, ‘%%Y-%%m-%%d %%H:%%i:%%s’)
AND year <= STR_TO_DATE(‘2011-01-02 00:00:00’, ‘%%Y-%%m-%%d %%H:%%i:%%s’)
AND country_code NOT IN (‘TCA’, ‘MNP’, ‘DMA’, ‘MHL’, ‘MCO’, ‘SXM’, ‘CYM’, ‘TUV’, ‘IMY’, ‘KNA’, ‘ASM’, ‘ADO’, ‘AMA’, ‘PLW’)
GROUP BY country_name,region
ORDER BY sum__SP_POP_TOTL DESC LIMIT 50000
4.9MarKup – 标记图

4.10Word Clould – 文字云
案例需求:显示所有的name,且看到使用这个名字的人数比重。
SQL语句:
SELECT name AS name,
sum(num) AS sum__num
FROM
(select *
from birth_names) AS expr_qry
WHERE ds >= ‘1917-07-05 17:39:23’
AND ds <= ‘2017-07-05 17:39:23’
GROUP BY name
ORDER BY sum__num DESC LIMIT 50000

4.11Sunburst – 旭日图
案例需求:第一层gender,第二层name,统计人数。
SQL:
SELECT gender AS gender,
name AS name,
sum(num) AS sum__num,
sum(num) AS sum__num
FROM
(select *
from birth_names) AS expr_qry
WHERE ds >= ‘1917-07-05 17:56:35’
AND ds <= ‘2017-07-05 17:56:35’
GROUP BY gender,
name
ORDER BY sum__num DESC LIMIT 50000

4.12Parallel Coordinates –平行坐标图
平行坐标图为一种数据可视化的方式。以多个垂直平行的坐标轴表示多个维度,以维度上的刻度表示在该属性上对应值,以颜色区分类别。每个样本在各个维度上对应一个值,相连而得的一个折线表示该样本。
SQL:
SELECT country_name AS country_name,
SUM(SP_POP_TOTL) AS sum__SP_POP_TOTL,
SUM(SP_RUR_TOTL_ZS) AS sum__SP_RUR_TOTL_ZS,
SUM(SH_DYN_AIDS) AS sum__SH_DYN_AIDS,
AVG(NY_GNP_PCAP_CD) AS avg__NY_GNP_PCAP_CD
FROM wb_health_population
WHERE year >= STR_TO_DATE(‘2011-01-01 00:00:00’, ‘%%Y-%%m-%%d %%H:%%i:%%s’)
AND year <= STR_TO_DATE(‘2011-01-01 00:00:00’, ‘%%Y-%%m-%%d %%H:%%i:%%s’)
GROUP BY country_name
ORDER BY sum__SP_POP_TOTL DESC LIMIT 50000

4.13Box plot – 盒图
盒图(boxplot):摆弄数据离散度的一种图形。它对于显示数据的离散的分布情况效果不错。在软件工程中,Nassi和Shneiderman 提出了一种符合结构化程序设计原则的图形描述工具,叫做盒图,也被称为N-S图。
SQL:
SELECT region AS region,
year AS timestamp,
SUM(SP_POP_TOTL) AS sum__SP_POP_TOTL
FROM wb_health_population
INNER JOIN
(SELECT region AS region,
SUM(SP_POP_TOTL) AS sum__SP_POP_TOTL
FROM wb_health_population
WHERE year >= STR_TO_DATE(‘1960-01-01 00:00:00’, ‘%%Y-%%m-%%d %%H:%%i:%%s’)
AND year <= STR_TO_DATE(‘2017-07-11 09:46:33’, ‘%%Y-%%m-%%d %%H:%%i:%%s’)
GROUP BY region
ORDER BY sum__SP_POP_TOTL DESC LIMIT 25) AS anon_1 ON region = region__
WHERE year >= STR_TO_DATE(‘1960-01-01 00:00:00’, ‘%%Y-%%m-%%d %%H:%%i:%%s’)
AND year <= STR_TO_DATE(‘2017-07-11 09:46:33’, ‘%%Y-%%m-%%d %%H:%%i:%%s’)
GROUP BY region,year
ORDER BY sum__SP_POP_TOTL DESC LIMIT 50000
