强智科技教务系统验证码识别
强智科技验证码识别
前言
由于近期在写一个教务系统的爬虫程序,但是网站的验证码让人很头疼,所以笔者临时找了一些资料学习了一下,本人python用的很少,而且在机器学习这块也是新手,从来没有接触过,所以写的不好还请指点出来。
环境
python3.6
PIL
sklearn
准备
使用一个简单的脚本下载1000张验证码,然后做好标记
import requests
url = "http://****/verifycode.servlet"
for i in range(1000):
filename = "./code/"+str(i)+".png"
response = requests.get(url)
with open(filename , "wb") as f:
f.write(response.content)

图像处理
实例图片
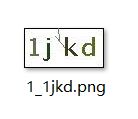
1.二值化,这里我们进行手动利用一个阈值进行二值化,处理完成以后的图片如下
![]()
2.降噪,思路是,当一个点他为黑色时,周围8(这个数字改小一点还可以完成线去除干扰线的功能,我这里就是使用这种方式将干扰点和干扰线去除的)个点都是白色则认为这是一个噪点

我们发现还是有一个点没有去除,没有关系,下面我们做字符分割的时候还是会进行一次降噪
3.字符分割,思路是找出每个数字的边缘坐标,如果上下边缘相差太小的话则认为这里为噪点,直接去除

图片转换为数据
上面已经分割好了,我们现在需要将图片转换成数据,方便我们下面传入机器学习,我用的方式是遍历分割好的方形区域,黑色为1,白色为0,拼接成一个类似于“0011010100000101111111111”的字符串,然后将字符串转换成int型数值
最后生成的数据是下面这种样子
图片数据:[“61256415613215646512” , “61256415613215646512” , “61256415613215646512” , “61256415613215646512”]
结果数据:[‘1’ , ‘j’ , ‘k’ , ‘d’]
训练模型
我是用的是knn分类算法
代码
1.图像处理类
from PIL import Image , ImageDraw
import cv2
'''
图片处理类
'''
class ImageHandler():
threshold = 130 #二值化处理阈值
im = None #保存当前类所处理的图片
spliter = []
data = []
labels = []
def __init__(self , filename):
self.filename = filename
self.data = []
self.labels = []
self.spliter = []
self.im = None
'''
图片文件读取
'''
def readFile(self):
self.im = Image.open(self.filename)
'''
图片二值化
'''
#def toBinary_img(self , im):
# im = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
# th1 = cv2.adaptiveThreshold(im, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 1)
# return th1
'''
手动将图片二值化
顺便去掉边框
'''
def toBinary_data(self):
self.readFile()
im = self.im
im = im.convert('L')
pixdata = im.load()
width , height = im.size
for j in range(height):
for i in range(width):
if(i == 0 or i == width-1 or j == 0 or j == height-1):
pixdata[i , j] = 255
continue
if(pixdata[i , j] < self.threshold):
pixdata[i , j] = 0
else:
pixdata[i , j] = 255
self.im = im
'''
降噪(点线降噪)
'''
def dot_noise(self):
im = self.im
w , h = im.size
pixdata = im.load()
#从左至右降噪
for y in range(h):
for x in range(w):
if(pixdata[x , y] == 0):
sum = 0 #四周总共有多少个白点
if(pixdata[x-1 , y] == 255):
sum+=1
if(pixdata[x+1 , y] == 255):
sum+=1
if(pixdata[x , y+1] == 255):
sum+=1
if(pixdata[x , y-1] == 255):
sum+=1
if(pixdata[x-1 , y-1] == 255):
sum+=1
if(pixdata[x-1 , y+1] == 255):
sum+=1
if(pixdata[x+1 , y-1] == 255):
sum+=1
if(pixdata[x+1 , y+1] == 255):
sum+=1
if(sum >= 7): #这里为7的时候图片处理这完整,但是当准确率不及为5的时候,所以真正应用的时候建议将它改成5,下面那个也一样
pixdata[x , y] = 255
'''
#从右至左降噪
for y in range(h):
for x in range(w-1 , -1 , -1):
if(pixdata[x , y] == 0):
sum = 0 #四周总共有多少个白点
if(pixdata[x-1 , y] == 255):
sum+=1
if(pixdata[x+1 , y] == 255):
sum+=1
if(pixdata[x , y+1] == 255):
sum+=1
if(pixdata[x , y-1] == 255):
sum+=1
if(sum >= 3):
pixdata[x , y] = 255
'''
#从下至上降噪
for y in range(h-1 , -1 , -1):
for x in range(w-1 , -1 , -1):
if(pixdata[x , y] == 0):
sum = 0 #四周总共有多少个白点
if(pixdata[x-1 , y] == 255):
sum+=1
if(pixdata[x+1 , y] == 255):
sum+=1
if(pixdata[x , y+1] == 255):
sum+=1
if(pixdata[x , y-1] == 255):
sum+=1
if(pixdata[x-1 , y-1] == 255):
sum+=1
if(pixdata[x-1 , y+1] == 255):
sum+=1
if(pixdata[x+1 , y-1] == 255):
sum+=1
if(pixdata[x+1 , y+1] == 255):
sum+=1
if(sum >= 7):
pixdata[x , y] = 255
self.im = im
'''
切割
'''
def cut_img(self):
im = self.im
w , h = im.size
pixdata = im.load()
#1.找出切割点
spliter_y = []
spliter_x = []
flag = False #表示当前遍历的全部为白色,当遇到黑色时就会变成True
#1.1找纵向切割点
for x in range(w):
column = False #当前行全是白色则为False , 否则为True
for y in range(h):
if(pixdata[x , y] == 0):
column = True
if(flag == False):
flag = True
spliter_x.append(x - 1)
if(flag == True and column == False):
spliter_x.append(x)
if(column == False):
flag = False
#print(self.filename)
#判断是否有字符粘连,如果有就进行切割
for i in range(0 , len(spliter_x) , 2):
#两个粘连的问题
if(spliter_x[i+1] - spliter_x[i] > 21 and spliter_x[i+1] - spliter_x[i] < 43):
x = spliter_x[i]
y = spliter_x[i+1]
spliter_x[i+1] = x+19
spliter_x.insert(i+2 , y)
spliter_x.insert(i+2 , x+19)
if(i == 0):
if(spliter_x[i+5] - spliter_x[i+4] > 21):
x = spliter_x[i+4]
y = spliter_x[i+5]
spliter_x[i+5] = x+19
spliter_x.insert(i+6 , y)
spliter_x.insert(i+6 , x+19)
break
#三个粘连的问题
elif(spliter_x[i+1] - spliter_x[i] >= 43):
x = spliter_x[i]
y = spliter_x[i+1]
spliter_x[i+1] = x+19
spliter_x.insert(i+2 , y)
spliter_x.insert(i+2 , x+37)
spliter_x.insert(i+2 , x+37)
spliter_x.insert(i+2 , x+19)
break ;
#print(spliter_x)
#2.2找横向切割点
for i in range(0 , len(spliter_x) , 2):
#1.1.1先从上到下找到顶部临界点
flag = False
for y in range(h):
for x in range(spliter_x[i] , spliter_x[i+1]):
if(pixdata[x , y] == 0):
if(flag == False):
flag = True
spliter_y.append(y)
break ;
if(flag == True):
break
#1.1.2从下至上找到底部临界点
flag = False
for y in range(h-1 , -1 , -1):
for x in range(spliter_x[i] , spliter_x[i+1]):
if(pixdata[x , y] == 0):
if(flag == False):
flag = True
spliter_y.append(y+1)
break
if(flag == True):
break
#再次降噪
temp_arr_x = []
temp_arr_y = []
for i in range(0 , len(spliter_y) , 2):
#print(str(spliter_y[i+1]) +"\t"+ str(spliter_y[i]))
if(spliter_y[i+1] - spliter_y[i] <= 4):
for x in range(spliter_x[i] , spliter_x[i+1]):
for y in range(spliter_y[i] , spliter_y[i+1]):
pixdata[x , y] = 255
spliter_x[i] = 0
spliter_x[i+1] = 0
spliter_y[i] = 0
spliter_y[i+1] = 0
else:
temp_arr_x.append(spliter_x[i])
temp_arr_x.append(spliter_x[i+1])
temp_arr_y.append(spliter_y[i])
temp_arr_y.append(spliter_y[i+1])
spliter_x = temp_arr_x
spliter_y = temp_arr_y
#将分割点进行存储
result = [[] , [] , [] , []]
#print(len(spliter_x))
if(len(spliter_x) == 8):
for i in range(len(result)):
result[i].append(spliter_x[i*2])
result[i].append(spliter_y[i*2])
result[i].append(spliter_x[i*2+1])
result[i].append(spliter_y[i*2+1])
else:
return False
self.spliter = result
def test(self):
'''测试切割后的结果'''
for index , i in enumerate(self.spliter):
box = tuple(i)
region = self.im.crop(box)
w , h = region.size
w = w - 1
h = h - 1
draw = ImageDraw.Draw(region)
draw.line((0 , 0 , w , 0) , fill=160)
draw.line((0 , 0 , 0 , h) , fill=160)
draw.line((w , 0 , w , h) , fill=160)
draw.line((0 , h , w , h) , fill=160)
del draw
self.im.paste(region, box)
#region.save(str(index)+".png" , "PNG")
'''
将分割好的图片转换成机器学习数据
'''
def img_2_train_data(self):
f = self.filename.replace(".png" , "")[-4:]
for index , i in enumerate(self.spliter):
box = tuple(i)
region = self.im.crop(box)
w , h = region.size
pixdata = region.load()
d = "0b"
for y in range(h):
for x in range(w):
if(pixdata[x , y] == 0):
d+='1'
else:
d+='0'
self.data.append(int(d , 2))
self.labels.append(f[index])
2.训练代码
from numpy import *
import numpy as np
from sklearn import neighbors
import os
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.externals import joblib
from ImageHandler import ImageHandler
from PIL import Image
img_dir = "./code"
files = os.listdir(img_dir)
data = []
result = []
for i in range(len(files)):
path = img_dir+"/"+files[i]
image = ImageHandler(path)
image.toBinary_data()
image.dot_noise()
image.cut_img()
image.img_2_train_data()
data = np.append(data , image.data)
result = np.append(result , image.labels)
del image
print("数据准备完毕")
x = data.reshape(-1 , 1)
y = result.reshape(-1 , 1)
x = np.array(x)
y = np.array(y)
# 拆分训练数据与测试数据
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.1)
# 训练KNN分类器
clf = neighbors.KNeighborsClassifier()
clf.fit(x, y)
print("训练完成")
# 保存分类器模型
joblib.dump(clf, './knn/knn.pkl')
print("结束")
print("检验准确率")
# # 测试结果打印
pre_y_train = clf.predict(x_train)
pre_y_test = clf.predict(x_test)
class_name1 = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9' , 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j' , 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't' , 'u', 'v', 'w', 'x']
class_name2 = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9' , 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j' , 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't' , 'u', 'v', 'w', 'x']
print (classification_report(y_train, pre_y_train, target_names=class_name1))
print (classification_report(y_test, pre_y_test, target_names=class_name2))