写在前面
本文上接SpringDataJpa学习(1)——Jpa学习,在学习了Jpa规范后,来学习一下SpringDataJpa的使用。SpringDataJpa是spring公司推出的对jpa规范的深层封装。SpringDataJpa极大简化了数据库访问层代码,可以让我们免除各种简单的sql语句。
使用SpringDataJpa的环境准备
导入坐标
5.2.3.RELEASE
5.0.7.Final
1.6.6
1.2.12
0.9.1.2
5.1.6
junit
junit
4.12
test
org.aspectj
aspectjweaver
1.6.8
org.springframework
spring-aop
${spring.version}
org.springframework
spring-context
${spring.version}
org.springframework
spring-context-support
${spring.version}
org.springframework
spring-orm
${spring.version}
org.springframework
spring-beans
${spring.version}
org.springframework
spring-core
${spring.version}
org.hibernate
hibernate-core
${hibernate.version}
org.hibernate
hibernate-entitymanager
${hibernate.version}
org.hibernate
hibernate-validator
5.2.1.Final
c3p0
c3p0
${c3p0.version}
log4j
log4j
${log4j.version}
org.slf4j
slf4j-api
${slf4j.version}
org.slf4j
slf4j-log4j12
${slf4j.version}
mysql
mysql-connector-java
${mysql.version}
org.springframework.data
spring-data-jpa
2.3.1.RELEASE
org.springframework
spring-test
${spring.version}
javax.el
javax.el-api
3.0.1-b06
org.glassfish.web
javax.el
2.2.6
书写配置文件
由于是spring的一套规范,我们肯定要写spring的配置文件,如下。
配置映射关系
还是和之前一样,在实体类上配置:
@Entity
@Table(name = "cst_customer")
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "cust_id")
private Long custId;
@Column(name = "cust_address")
private String custAddress;
@Column(name = "cust_industry")
private String custIndustry;
@Column(name = "cust_level")
private String custLevel;
@Column(name = "cust_name")
private String custName;
@Column(name = "cust_phone")
private String custPhone;
@Column(name = "cust_source")
private String custSource;
}
并且生成对应的get和set方法以及toString即可。
编写符合SpringDataJpa规范的Dao层接口
/**
* JpaRepository<操作的实体类类型,实体类中主键属性的类型>
* 封装了基本CRUD操作
* JpaSpecificationExecutor<操作的实体类类型>
* 封装了复杂查询(分页)
*
* @author wushen
*/
public interface CustomerDao extends JpaRepository, JpaSpecificationExecutor {}
实际上,我们只需要定义一个接口然后继承规定好的接口并写好泛型即可。
使用SpringDataJpa
在配置好后,我们可以写一个测试类来测试一下:
测试根据id查询
@RunWith(SpringJUnit4ClassRunner.class) // 声明单元测试环境
@ContextConfiguration(locations = "classpath:applicationContext.xml") //指定spring容器的配置信息
public class CustomerDaoTest {
@Autowired
private CustomerDao customerDao;
/**
* 根据id查询
*/
@Test
public void testFindOne() {
Optional one = customerDao.findById(3L);
if (one.isPresent()) {
System.out.println(one.get());
}
}
}
由于是Spring的相关组件,我们要在测试类上配置好spring的相关测试信息,并且设置自动注入。
这里我们测试了一个简单的findById方法,会返回一个封装类,这都是SpringDataJpa规定好的,我们通过isPresent()方法判空,然后get()方法取得该对象即可。
测试添加和修改
/**
* save:保存或者更新
* 根据传递的对象是否存在主键id,如果没有id主键属性:保存
* 存在id主键属性,根据id查询数据库,更新数据
*/
@Test
public void testSave() {
Customer customer = new Customer();
customer.setCustName("我的天呐");
customer.setCustLevel("VIP");
customer.setCustIndustry("吔屎国");
customerDao.save(customer);
}
/**
* 更新
*/
@Test
public void testUpdate() {
Customer customer = new Customer();
customer.setCustId(4L);
customer.setCustName("我的天呐");
customer.setCustLevel("VIP");
customer.setCustIndustry("吔屎国");
Date date = new Date();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
String dateTime = simpleDateFormat.format(date);
customer.setCustName(dateTime);
customerDao.save(customer);
}
在接口定义中,save既是保存也是更新,这主要取决于是否包含id。
延迟加载的根据id查询
/**
* 根据id从数据库查询
*
* @Transactional 保证getOne正常运行
*
* findById:em.find()
* getOne:em.getReference() 延迟加载
* 返回的是一个客户的动态代理对象,什么时候用,什么时候查询
*/
@Test
@Transactional
public void testGetOne() {
Customer customer = customerDao.getOne(4L);
System.out.println(customer);
}
与JPA相似,这里也有延迟加载。
使用jpql的方式查询
既然是封装的jpa规范,肯定也能使用jpql。我们首先在dao接口定义方法:
/**
* 根据客户名称查询客户
* 使用jpql的形式查询
* jpql: from Customer where custName = ?
* 配置jpql语句,使用@Query注解
* 也可以是这种形式
*/
@Query(value = "from Customer where custName = :custName")
Customer findJpql(@Param("custName") String custName);
之后使用即可:
public void testFindJPQL(){
Customer customer = customerDao.findJpql("我去");
System.out.println(customer);
}
这里我们注意到,query语句里使用了这样的形式。其实我们也可以使用下面这种形式:
/**
* 根据客户名称和客户id查询客户
* jpql:from Customer where custName = ? and custId = ?
* 可以是这种形式
*
* @param custName
* @param custId
* @return
*/
@Query(value = "from Customer where custName = ?1 and custId = ?2")
Customer findCustNameAndId(String custName, Long custId);
一种是通过索引,一种是通过标注@param后直接在语句中写上:加名字即可
测试更新或删除
更新与删除有点点不同,需要添加一个@Modifying注解:
/**
* 使用jpql完成更新操作
* 根据id更新客户的名称
* sql: update cst_customer set cust_name = ? where cust_id = ?
* jpql:update Customer set custName = ? where custId = ?
* 需要手动添加事务的支持
*
* @modifying 注解以通知这是一个delete或update操作
*/
@Query(value = "update Customer set custName = ?2 where custId = ?1")
@Modifying
void updateCustomer(Long custId, String custName);
编写测试类:
@Test
@Transactional
public void testUpdate(){
customerDao.updateCustomer(2L,"我去");
}
需要加上支持事务的注解。
使用原生sql查询
SpringDataJpa也是支持原生sql查询的,我们在dao中定义方法:
/**
* 以sql的形式查询
* 查询全部的客户
* sql: select * from cst_customer;
* nativeQuery:true:sql查询
* false:jpql查询
*/
@Query(value = "select * from cst_customer", nativeQuery = true)
List findSql();
只要把nativeQuery改成true即可使用原生sql(默认是false,使用jpql)
编写测试类:
/**
* 测试sql查询
*/
@Test
public void testFindSql(){
List list = customerDao.findSql();
for (Object[] objects : list) {
System.out.println(Arrays.toString(objects));
}
}
类似的,我们也可以使用占位符(?)
/**
* 带参数的模糊查询sql
* @param custName
* @return
*/
@Query(value = "select * from cst_customer where cust_name like ?1", nativeQuery = true)
List findSqlWithParam(String custName);
编写测试类:
/**
* 测试带参数的模糊sql查询
*/
@Test
public void testFindSqWithParam(){
List list = customerDao.findSqlWithParam("我%");
for (Object[] objects : list) {
System.out.println(Arrays.toString(objects));
}
}
按照spring官方定义的命名规则的查询
实际上,我们不必自己写jpql语句,只需要按照官方的命名方式命名即可。我上官方文档看了看,目前有这些:

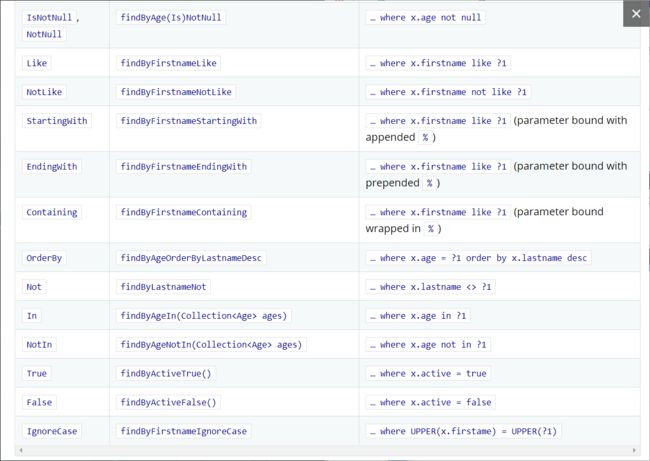
可以看到这些基本包含了所有的查询方法了。我们自己写一个试试:
/**
* 方法名的约定:
* findBy:查询
* 对象中的属性名(首字母大写) :查询的条件
* findByCustName -- 根据客户名称查询 默认情况:使用等于的方式查询
*
* 在springdatajpa的运行阶段会根据方法名称进行解析, findBy from xx(实体类)
* 属性名 where custName =
* @param custName
* @return
*/
Customer findByCustName(String custName);
编写测试类:
/**
* 测试方法命名规则的查询
*/
@Test
public void testFindByCustName(){
Customer customer = customerDao.findByCustName("我去");
System.out.println(customer);
}
其他的还有很多,这里就不再一一测试了,按照表格对应的关系书写即可。
总结
可以看到SpringDataJpa的功能十分强大,几乎涵盖了全部的常用应有场景。但这里并没有涉及到多表的配置。之后会学习如何配置多表。