Flask-- (三) Flask数据库操作
1、数据库开始
1.1 ORM
python 本身是可以操作数据库的,但是在开发中这些步骤却显得有些复杂,同时数据库可移植性差和开发人员数据库技术参差不齐等问题也尤为突出。为了解决以上问题,从而有了ORM(object relationship mapping)。
数据库关系映射:用面向对象的类对应数据库当中的表,开发者通过面向对象编程来描述数据库表、结构和增删改查,然后将描述映射到数据库,完成对数据库的操作。用户不需要再去和SQL语句打交道,只要像平时操作对象一样操作即可。
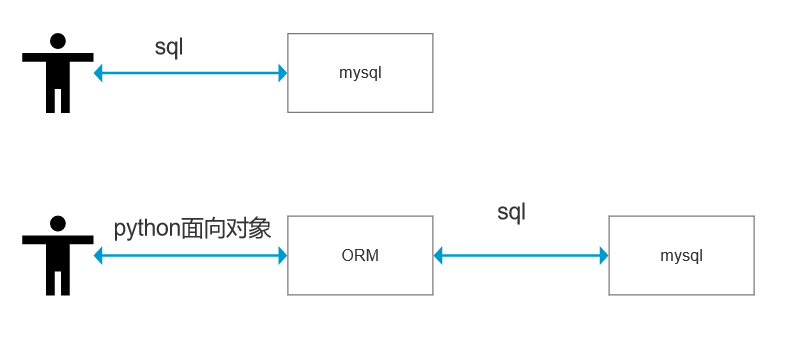
由于flask本身没有操作数据库的能力,需要借助flask_sqlalchemy(ORM框架)进行操作。
# 切换到flask的沙箱环境中执行下面的安装命令
pip install flask_sqlalchemy
1.2 数据库
sqlite数据库,是和python最契合的轻量级关系型数据库,python在安装同时已经携带了sqlite数据库。sqlite数据库就是一个.sqlite文件。但由于pycharm大部分都没有安装sqlite驱动,需要手动安装。
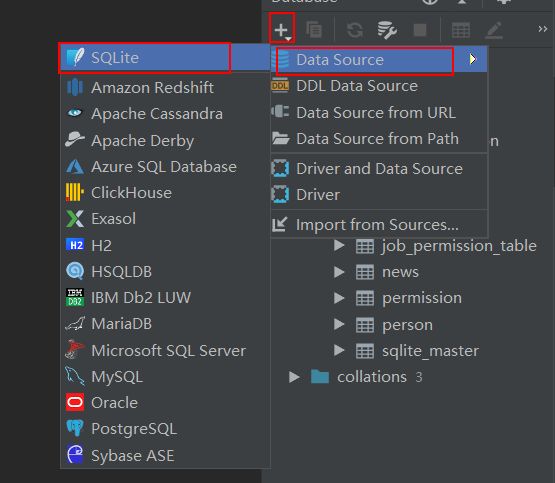
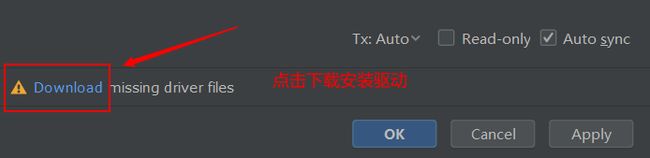
2、数据库建模
用数据库来描述业务逻辑,一个好的数据库模型代表整个网站成功一半,反之,如果数据库设计出了问题,项目多半不会成功。可根据需求画出ER图,根据ER图中列出的各个实体的字段和之间的联系来创建数据表。
3、数据库初始化
创建数据库并将数据库文件的存放到指定位置、创建表。
import os
from flask import Flask
from flask_sqlalchemy import SQLAlchemy # 导入flask_sqlalchemy模块
base_dir = os.path.dirname(
os.path.abspath(__file__) # 获取当前文件的绝对路径
) # 返回当前文件的目录
app = Flask(__name__) # 实例化app
# 设置数据库文件存放的路径为当前文件目录下,以OA.sqlite命名
app.config["SQLALCHEMY_DATABASE_URI"] = "sqlite:///"+os.path.join(base_dir, "OA.sqlite")
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = True # 设置数据库支持追踪修改
db = SQLAlchemy(app) # 加载数据库
class Person(db.Model): # 定义数据表,db.Model是所有创建表的父类
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
# Column:列,primary_key:主键,autoincrement:自增长
username = db.Column(db.String(32), unique=True) # 用户名不能重复
password = db.Column(db.String(32))
nickname = db.Column(db.String(32))
age = db.Column(db.Integer, default=18) # 年龄默认十八岁
gender = db.Column(db.String(16))
score = db.Column(db.Float, nullable=True) # 值可以为空
db.create_all() # 同步数据库
数据表字段常用的数据类型:
| 数据类型 | 描述 |
|---|---|
| Integer | 整形 |
| Float: | 浮点型 |
| String | 字符串 |
| Date | 年月日 |
| Datetime | 年月日时分秒 |
| Text | 长文本 |
字段的常用参数
| 参数 | 描述 |
|---|---|
| primary_key | 主键 |
| unique | 键值唯一性 |
| nullable | 空值 |
| default | 默认值 |
| index | 索引 |
4、增
添加数据到数据库中
person1 = Person(
username="laoli",
password="123456",
nickname="老李",
age=18,
gender="男",
score=96.5
)
person2 = Person(
username="laosun",
password="123456",
nickname="老孙",
age=18,
gender="男",
score=92.5
)
# 增加单条数据
db.session.add(person1)
db.session.commit()
# 增加多条数据
db.session.add_all([person1, person2])
db.session.commit()
5、删
# 获取要删除的数据对象
person = Person.query.get(1)
# 删除
db.session.delete(person)
db.session.commit()
6、改
# 获取要修改的数据对象
person = Person.query.get(1)
# 修改
person.age = 35
db.session.commit()
7、查
7.1 查询一条数据
# 以id为条件查询数据
person = Person.query.get(302) # 获取id为302的员工数据
print(person.score) # 输出该用户的分数
7.2 查询所有数据
person_list = Person.query.all() # 查询所有员工数据
7.3 查询部分数据
filter_by:适合简单的查询,例如单个条件限制
# 查询所有女员工
person_list = Person.query.filter_by(gender="女")
filter:适合比较复杂的查询,多条件限制
# 查询所有年龄大于21岁的男员工
person_list = Person.query.filter(Person.gender=="男", Person.age > 21)
7.4 模糊查询
# 查询所有年龄大于21岁的姓王的男员工
person_list = Person.query.filter(
Person.gender == "男",
Person.age > 21,
Person.nickname.like("王%"))
7.5 数量限制查询
限制返回条数
# 查询十条年龄大于21岁的姓王的男员工
person_list = Person.query.filter(
Person.gender == "男",
Person.age > 21,
Person.nickname.like("王%")).limit(10)
设置查询的起始位置
# 查询十条年龄大于21岁的姓王的男员工,从第二十个开始
person_list = Person.query.filter(
Person.gender == "男",
Person.age > 21,
Person.nickname.like("王%")).limit(10).offset(20)
7.6 排序查
正序
# 查询一百条年龄大于21岁的姓王的男员工,按照年龄排序
person_list = Person.query.filter(
Person.gender == "男",
Person.age > 21,
Person.nickname.like("王%")).order_by(Person.age).limit(100)
倒序
# 查询一百条年龄大于21岁的姓王的男员工,按照年龄排倒序
person_list = Person.query.filter(
Person.gender == "男",
Person.age > 21,
Person.nickname.like("王%")).order_by(Person.age.desc()).limit(100)
7.7 聚合查
聚合查需要导入func
from sqlalchemy import func
最大值
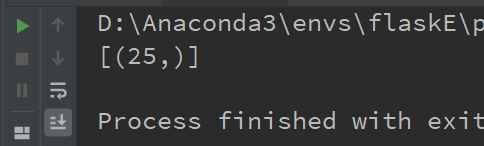
# 查询姓王的男员工的最大年龄
result = db.session.query(
func.max(Person.age)
).filter(
Person.gender == "男",
Person.nickname.like("王%")).all()
print(result)
最小值
# 查询姓王的男员工的最小年龄
result = db.session.query(
func.min(Person.age)
).filter(
Person.gender == "男",
Person.nickname.like("王%")).all()
print(result)
统计数量
# 查询所有年龄大于21的男生的个数
result = db.session.query(
func.count(Person.id)
).filter(
Person.gender == "男",
Person.age > 21,
Person.nickname.like("王%")).all()
print(result)

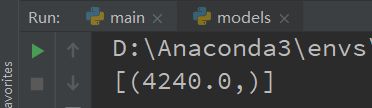
求和
# 查询姓王的男员工的分数总和
result = db.session.query(
func.sum(Person.score)
).filter(
Person.gender == "男",
Person.nickname.like("王%")).all()
print(result)
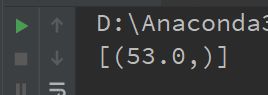
求平均值
# 查询姓王的男员工的分数的平均数
result = db.session.query(
func.avg(Person.score)
).filter(
Person.gender == "男",
Person.nickname.like("王%")).all()
print(result)
7.8 分组查
# 查询男女个数
result = db.session.query(
Person.gender,
func.count(Person.id)
).group_by(Person.gender).all()
print(result)

# 查询姓王的男员工各年龄段的人数
result = db.session.query(
Person.age,
func.count(Person.id)
).filter(
Person.gender == "男",
Person.nickname.like("王%")
).group_by(Person.age).all()
print(result)

7.9 逻辑查
逻辑查需要导入and_ or_ not_
from sqlalchemy import and_, or_, not_
# 查询十个女员工或者年龄小于22的男员工
result = Person.query.filter(or_(
Person.gender=="女",
and_(
Person.gender=="男",
Person.age<22
)
)
).limit(10).all()
for i in result:
print(i.nickname, i.gender, i.age)

8、基于面向对象的操作
定义一个父类,在类中定义保存、删除、修改的方法,所有表类继承该类,即可实现基于面向对象的操作。
# 基于面向对象的操作
class Base(db.Model):
__abstract__ = True # 作为父类完成被继承,本身不执行
id = db.Column(db.Integer, primary_key=True, autoincrement=True) # 设置所有子类的id
def save(self): # 保存方法
db.session.add(self)
db.session.commit()
def delete(self): # 删除方法
db.session.delete(self)
db.session.commit()
def update(self): # 修改方法
db.session.commit()
class Person(Base): # 定义人员表
username = db.Column(db.String(32), unique=True) # 用户名不能重复
password = db.Column(db.String(32))
nickname = db.Column(db.String(32))
age = db.Column(db.Integer, default=18) # 年龄默认十八岁
gender = db.Column(db.String(16))
score = db.Column(db.Float, nullable=True) # 值可以为空
# 增
person = Person()
person.username="laohu"
person.password="123"
person.nickname="老胡"
person.save()
# 修改id为2的性别
person = Person.query.get(2)
person.gender = "男"
person.update()
# 删除id为2的员工
person = Person.query.get(2)
person.delete()
9、关系操作
9.1 一对多关系
以员工和职位为例,一个员工只能担任一个职位,一个职位可以有多名员工。
# 数据库建模
class Base(db.Model):
__abstract__ = True # 作为父类完成被继承,本身不执行
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
def save(self):
db.session.add(self)
db.session.commit()
def delete(self):
db.session.delete(self)
db.session.commit()
def update(self):
db.session.commit()
class Person(Base): # 员工表
username = db.Column(db.String(32), unique=True) # 用户名不能重复
password = db.Column(db.String(32))
nickname = db.Column(db.String(32))
age = db.Column(db.Integer, default=18) # 年龄默认十八岁
gender = db.Column(db.String(16))
score = db.Column(db.Float, nullable=True) # 值可以为空
# 声明p_job是一个外键字段,对应job表的id
p_job = db.Column(db.Integer, db.ForeignKey("job.id"))
class Job(Base): # 职位表
j_name = db.Column(db.String(32))
p_person = db.relationship(
"Person", # 映射的类对象 p_person映射到员工表,可以在职位表中快速查询每个职位所对应的所有员工
backref="my_job" # 反向映射,给person表使用的,可以在员工表中,根据my_job快速查询到员工的职位
)
注意:p_job字段填入的是员工所对应的职位id,在添加员工的职位id数据时,该职位id在job表中必须已经存在,job表中不存在的职位id不能添加到员工信息表中。
查询职位所对应的所有员工
job = Job.query.get(1)
person_list = job.p_person # p_person映射到员工表,可以在职位表中快速查询每个职位所对应的员工
print([p.nickname for p in job.p_person])

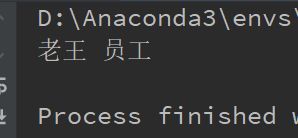
查询员工的职位
# 查询id为1的员工的职位
person = Person.query.get(1)
print(person.nickname, person.my_job.j_name)
9.2 多对多关系
以职位和权限为例,一个职位可以有多个权限,每个权限可以授予多个职位使用。
# 数据库建模
class Base(db.Model):
__abstract__ = True # 作为父类完成被继承,本身不执行
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
def save(self):
db.session.add(self)
db.session.commit()
def delete(self):
db.session.delete(self)
db.session.commit()
def update(self):
db.session.commit()
class Job(Base):
j_name = db.Column(db.String(32))
job_permission_map = db.relationship(
"Permission", # 映射表 可以在职位表中快速查询职位所对应的所有权限
secondary="job_permission_table", # 中间表
backref="permission_job_map" # 给permission表使用的,可以在权限表中快速查询权限所对应的 所有职位
)
class Permission(Base):
perm_name = db.Column(db.String(64))
job_permission_table = db.Table(
"job_permission_table", # 表名,职位和权限联系表
db.Column("perm_id", db.Integer, db.ForeignKey("permission.id")),
db.Column("job_id", db.Integer, db.ForeignKey("job.id")),
) # 中间表必须这样创建
中间表的数据添加
# 给主任添加权限
j = Job.query.get(1)
j.job_permission_map.append(
Permission.query.get(1) # 自动添加数据到中间表
)
j.save()
j = Job.query.get(1)
j.job_permission_map.append(
Permission.query.get(2) # 自动添加数据到中间表
)
j.save()
# 给经理添加权限
j = Job()
j.j_name = "经理"
j.save()
for i in range(1, 4):
j.job_permission_map.append(
Permission.query.get(i) # 自动添加数据到中间表
)
j.save()

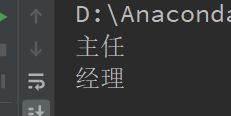
根据权限查询拥有该权限的所有职位
# 查看拥有权限id为1对应的所有职位
perm = Permission.query.get(1)
for job in perm.permission_job_map:
print(job.j_name)
查询职位的所有权限
# 查询职位为经理所对应的权限
job = Job.query.filter_by(j_name="经理").all()[0]
for i in job.job_permission_map:
print(i.perm_name)

9.3 映射表的位置
在一对多关系中,例如职位(一)和员工(多)关系中,映射表一般放在“一”表中,便于开发者使用一条数据查询出多条有关联的数据。在多对多关系中,映射表可以随意放置,一般放在使用频率较高的表中。