拼多多(yangkeduo)H5页面信息(anti_content)_requests
TOC
声明:本文仅作技术交流,严禁用于任何非法用途(如有冒犯,请联系我删除此文)
自从开始js逆向后就停不下来,有闲时就想去看看别人的网站,既见多识广,又享受解出来时的快乐。这次看的是市场份额发展飞快的拼多多手机版网页
1.模块作用
本demo目的是爬取http://mobile.yangkeduo.com/search_result.html?search_key=%E5%AD%A6%E7%94%9F%E6%96%87%E5%85%B7%E7%94%A8%E5%93%81%E7%AC%94通过xhr异步响应回来的信息。如下图示例:

2.思路解析
1)需要参数寻找
首先说明:图下这个url如果按照 首页–打字–搜索 的步骤话会出现很多参数,但有效参数其实就只有search_key一个。所以我把其他多余的都删了,这样比较精简(为啥说这个,因为后面有用)

行,我们还是来看看目标url的情况吧,如下图:
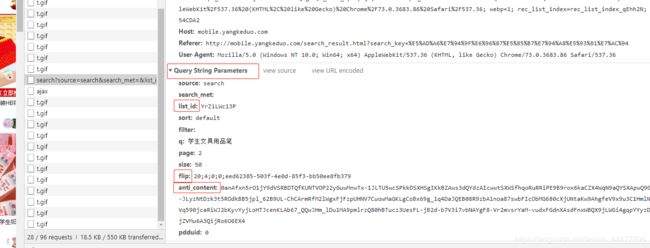
headers没啥说的,都挺正常。然后看params里面主要就是list_id、flip、anti_content三个参数不知道咋得出来的了
2)list_id、flip
仔细找一会儿的话会发现这俩参数其实是在主页里面的

这个id名为__NEXT_DATA__的script标签下一看起来就非常可疑,这个标签下就有list_id和flip
3)anti_content
在找到了list_id和flip后就只剩一个anti_content参数了,是不是感觉胜利在望了?其实pdd在js上就只有这一个反爬措施而已。
行, 那就开始吧。
(1)找入口
将鼠标悬浮到加载过的js后能看到很长一串,一般都是随便点一个,然后进去用上下栈慢慢找。
pdd的这个js是真的不好找,因为是异步执行的,调用上下栈能看到的参数是以异步前后分开的,所以耐心特别重要了。当然不是纯看参数,有时候也可以搜,或者看看代码英文对应的大概意思。
比如到这里的时候,这个getAntiContent那不就明摆着了吗?然后读一下riskController啥意思?不就是风险控制吗。这连anti_content的大概意思都懂了,然后再看看到了case 4的情况:
这个时候我们需要的anti_content已经出来,那么就意味着在case 0到case 4之间他已经加密完成了,接下来就再一次在case 0到case 4之间一直按F11观察情况了。然后按着按着就来到了这个js文件:

js文件名就叫RiskControl,这不明摆着么,不要犹豫,犹豫就会白给。然后多按几下F11,这就是入口了: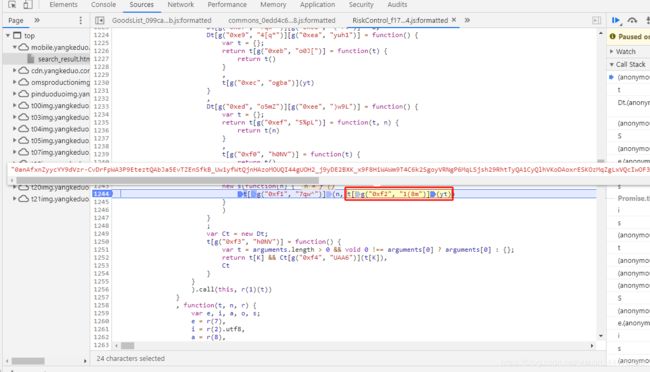
ps:看了这么多的js,我感觉pdd的难度其实就在找入口这里,找入口花了我2个多小时,因为promise这个东西毕竟不太熟,还去补了一下,附上我当前补promise语法的网址:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Promise
(2)逆js吧
先说一下:pdd的js用了N多语法丑化的混淆方式,其目的就是为了增大你的代码阅读量。当解起来的时候会出现很多开发中不可能出现的zz调用,但是我觉得这种来回调用在上下栈面前形同虚设,他故意为之,我们习惯就行。
举个例子:上图中的 t[g(“0xf2”, “1(8m”)](yt) 这个函数其实等于 yt()
行,我们直接就进入yt()吧,如下图(yt太长,我截部分图分两张):
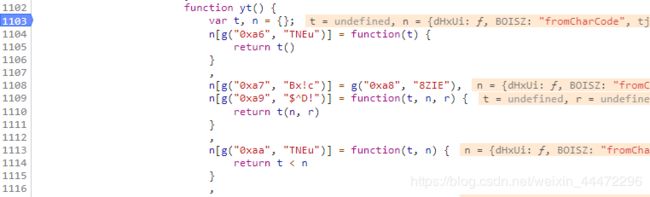
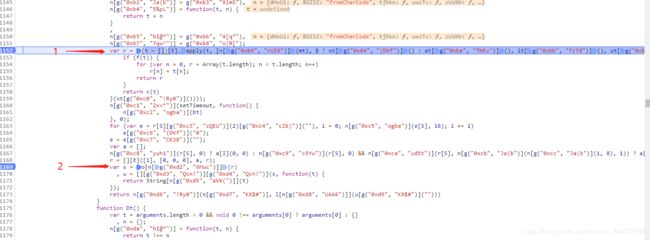
总说一下吧,yt()最后的return就是我们需要的anti_content,然后解的途中有两个重要的节点,我标记出来了。
1的目的是获取初始化参数r;
2的目的是以r为基础参数,产生最后需要转换成字符串的数组s。
然后中间的其他步骤都可以直接运行,比较简单。
第一步:r
然后开始这个长的不行的3目运算符吧:
拉通看,他就是一个apply改变this对象,然后把生成的这些拼成一个数组,只是有mt,at,it,ut,ct,ft,ht,wt,lt,dt,_t,pt,xt。 13个变量,所以看起来很长,比较难看。语法本身挺简单的,我觉得还行。
调用方式都一样,就选一个看吧(就选这个ut吧):
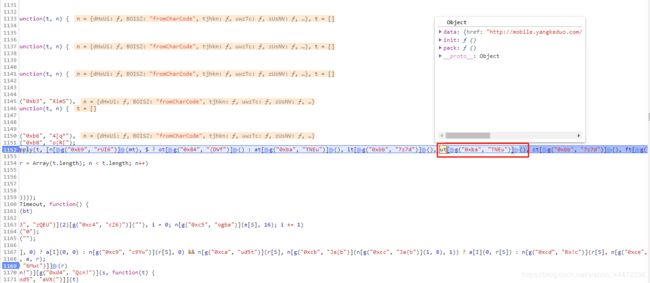
一开始我说了进入主页的url有用,其实用处就在ut这里了。由于他运行时自执行了init,而我抠的时候没有(因为会用到好多window对象,所以就自己加上),所以我们需要逐个将上面13个变量附上data值。
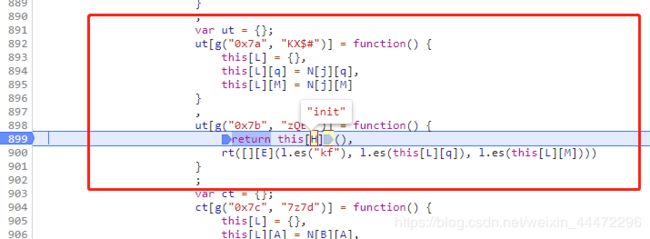
首先进入ut.pack()会在这里,他分为两部,再init一下,然后返回下面那一串。上面这个ut[g(“0x7a”, “KX$#”)]就是Init。L表示"data", q表示“href”, M表示"port", N表示window对象, j表示“location”。这个自己造就可以了----我这样搞的:
![]()

把href_data定义在了全局最后以参数形式来改变值,因为不可能每次都请求一样的东西吧。
然后是这个 rt([][E](l.es(“kf”), l.es(this[L][q]), l.es(this[L][M])))。这个时候需要去找这个l对象的生成地方。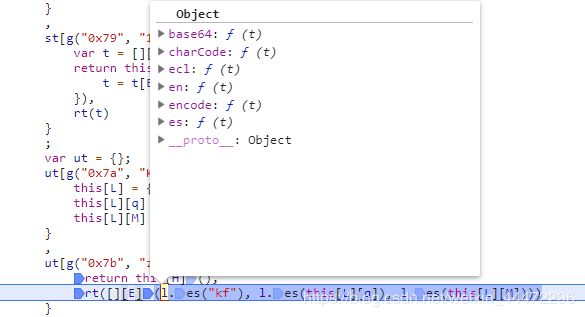
然后随便选个函数点过去,就是下图了,从260行到651行的大函数里,自执行的匿名函数就是l产生的过程: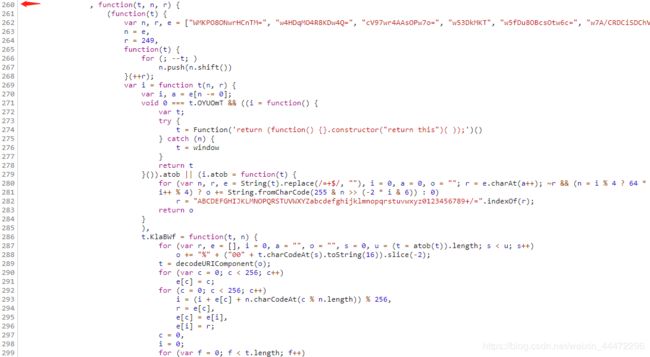

然后ut就可以运行完成了。没啥跨作用域的问题,非常简单。
就这样逐个完成这些变量,最后r就出来了,整个过程没啥难度,耐心即可。
然后一路向下都到第二个重点节点没什么困难,除了这个h:
多点几下就能知道,其实它简单得一匹,我把它简化了抠出来:

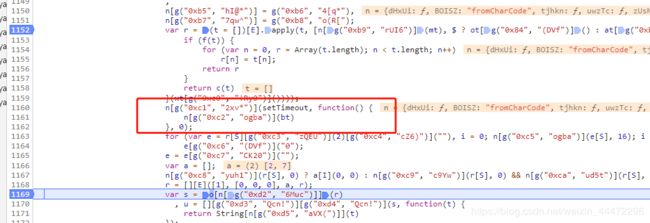
ps:途中有一个点我没去搞明白它的意义, 就是下图这个setTimeout,这里安个定时器是干啥的?知道的大佬可以讲一下它的作用:
第二步:o
后面都差不多,我就只说一下几个比较重要的函数吧。
点击o[n[g(“0xd2”, “6Muc”)]],进入这个函数:
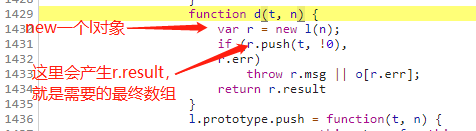
然后差啥补啥,比较麻烦的就是这个e.deflateInit2()
我就只截比较麻烦的地方了:Z(t),X(t)到这个a._tr_init(n),这里都是把函数所在的这个大函数截出来,自执行后绑定给一个变量就像一开始那个l对象一样,就不再说了

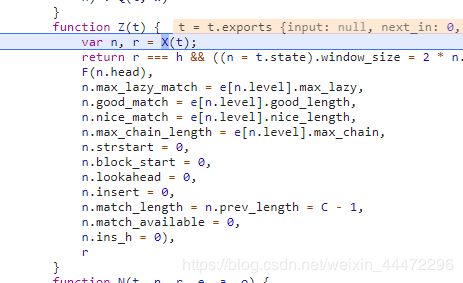

这个l对象 new出来了,然后就下一步push一下吧:

其实这里也是一样的操作方式,到这个e.deflate(s, o)的生成方式也是一样的,虽然它这个函数很长,但是有点耐心就可以了。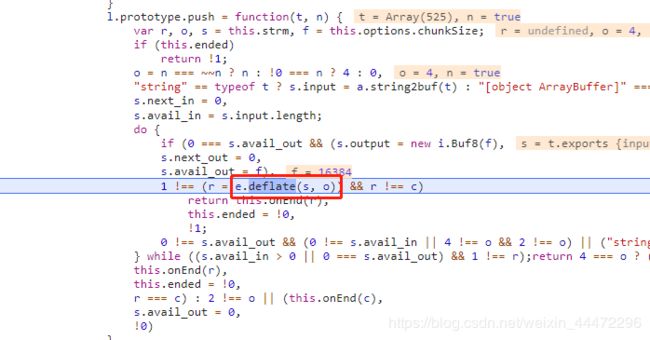
如果第二步这个s生成了,基本就完了。
代码可以参考我的antiContent_Js.py
3.检测一下结果

先请求一下主页

然后获取主页的list_id和flip,这里其实这个req_params就是除了flip和anti_content之外所有的参数了,非常方便,都不用自己写了
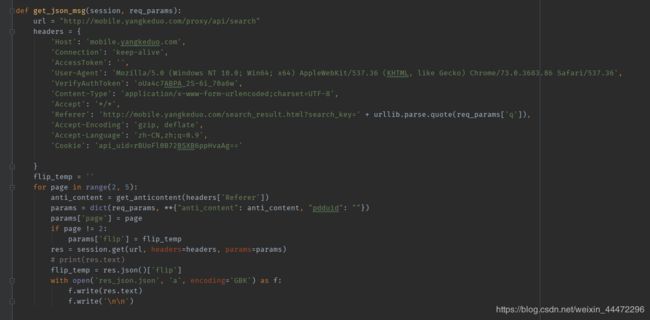
然后就开始请求吧,这里有一个veriyAuthToken是第二个我没有深入研究的地方,猜一下可能是pdd新加入的手机登录或者验证码机制的校验吧?有知道它作用的大佬可以点明一下。
这里我就只爬3页试试了,一是因为我们只是学习一下别人的代码,只解js,不搞服务器;二是爬多了肯定会出现手机验证和图片验证码的问题。
flip的值是根据上一页返回回来的flip值来确定的,所以和anti_content一样,每次都要变。不过好像就是20\40\60\80的等差规律吧,手动写也可以。
最后把数据暂时到json文件里吧

出来了,应该没有问题。
ps:发现一件有趣的事,我查看了一下,pdd的价格体系是按分计的啊,真是100个飞机呢,哈哈

4.总结
- 整个anti_content的破解,从开始找入口到解出来用了1天半,其中,大半天都用在了无用功上。因为我当时觉得第一步的r变量生成实在太简单,没有跨作用域,没有特别的语法,很容易,然后膨胀了,想用逐个抠函数的方式解决第二步的o变量。最后不知道是那一步抠错了,结果不对,导致重来。如果先搞清楚作用域的话,只花了2个小时就搞定了o,所以想起了高中数学老师的一句话:慢即是快啊;
- 以前解异步js比较少,通过pdd熟悉了一下promise的运作方式;
- 在我解的js中这个js的难度只能算中等(稍偏下吧)
附上github传送门:https://github.com/634739726/pdd_yangkeduo_spider