从零开始的Python图像识别-Week3 图像处理
学校开设了Python图像识别的课程,想在这里给大家分享一下学习的内容与经历。
本周主要讲解了对图片的一些操作以及一个车牌识别的小练习。
文章目录
- 核心操作
- 图像的基本操作
- 访问和修改像素值
- 访问图像属性
- 图像感兴趣区域(ROI)
- 拆分和合并图像通道
- 为图像设置边框(填充)
- 图像的算法操作
- 图像加法
- 图像融合
- 按位运算
- OpenCV中的图像处理
- 改变颜色空间
- 对象追踪
- 图像几何变换
- 变换
- 缩放
- 平移
- 旋转
- 仿射变换
- 透视变换
- 图像阈值
- 简单阈值
- 自适应阈值
- 形态转换
- 侵蚀
- 扩张
- 打开
- 关闭
- 图像梯度
- 车牌识别的简单小案例
核心操作
图像的基本操作
访问和修改像素值
首先引入我们所需要的库
>>> import cv2 as cv
>>> import numpy as np
>>> from matplotlib import pyplot as plt
>>> %matplotlib inline
然后加载彩色图片
>>> img = cv.imread("img1.jpg");
>>> plt.imshow(img)
>>> plt.show()

(ps:pyplot展示的图片会有亿点点色差(应该是因为cv中图片默认是BGR,而pyplot默认是RGB),建议还是使用cv.imshow()比较好。这里使用pyplot为了方便观察效果。)
我们可以通过行和列坐标来访问像素值。对于 BGR 图像,它返回一个由蓝色、绿色和红色值组成的数组。对于灰度图像,只返回相应的灰度。
>>> px = img[100,100]
>>> print( px )
[157 166 200]
# 仅访问蓝色像素
>>> blue = img[100,100,0]
>>> print( blue )
157
我们可以用相同的方式修改像素值。
>>> img[100,100] = [255,255,255]
>>> print( img[100,100] )
[255 255 255]
注意 上面面的方法通常用于选择数组的区域,例如前5行和后3列。对于单个像素访问,Numpy数组方法array.item()和array.itemset()被认为更好,但是它们始终返回标量。如果要访问所有B,G,R值,则需要分别调用所有的array.item()。
更好的像素访问和编辑方法:
# 访问 RED 值
>>> img.item(10,10,2)
59
# 修改 RED 值
>>> img.itemset((10,10,2),100)
>>> img.item(10,10,2)
100
访问图像属性
图像属性包括行数,列数和通道数,图像数据类型,像素数等。
图像的形状可通过img.shape访问。它返回行,列和通道数的元组(如果图像是彩色的):
>>> print( img.shape )
(342, 548, 3)
注意 如果图像是灰度的,则返回的元组仅包含行数和列数,因此这是检查加载的图像是灰度还是彩色的好方法。
像素总数可通过访问img.size获得:
>>> print( img.size )
562248
图像数据类型通过img.dtype获得:
>>> print( img.dtype )
uint8
图像感兴趣区域(ROI)
有时候,我们不得不处理一些特定区域的图像。对于图像中的眼睛检测,首先对整个图像进行人脸检测。在获取人脸图像时,我们只选择人脸区域,搜索其中的眼睛,而不是搜索整个图像。它提高了准确性(因为眼睛总是在面部上:D )和性能(因为我们搜索的区域很小)。
使用Numpy索引再次获得ROI。在这里,我要选择杯子并将其显示出来:
>>> bottle = img[100:300, 360:500]
>>> plt.imshow(bottle)
>>> plt.show()

拆分和合并图像通道
有时我们需要分别处理图像的B,G,R通道。在这种情况下,我们需要将BGR图像拆分为单个通道。在其他情况下,我们可能需要将这些单独的频道加入BGR图片。我们可以通过以下方式简单地做到这一点:
>>> b, g, r = cv.split(img)
>>> plt.imshow(r)
>>> plt.show()
你看看这色差:P
为图像设置边框(填充)
如果要在图像周围创建边框(如相框),则可以使用cv.copyMakeBorder()。但是它在卷积运算,零填充等方面有更多应用。此函数采用以下参数:
-
src - 输入图像
-
top,bottom,left,right 边界宽度(以相应方向上的像素数为单位)
-
borderType - 定义要添加哪种边框的标志。它可以是以下类型:
-
cv.BORDER_CONSTANT - 添加恒定的彩色边框。该值应作为下一个参数给出。常用
-
cv.BORDER_REFLECT - 边框将是边框元素的镜像,如下所示: fedcba | abcdefgh | hgfedcb
-
cv.BORDER_REFLECT_101或 cv.BORDER_DEFAULT与上述相同,但略有变化,例如: gfedcb | abcdefgh | gfedcba
-
cv.BORDER_REPLICATE最后一个元素被复制,像这样: aaaaaa | abcdefgh | hhhhhhh
-
cv.BORDER_WRAP难以解释,它看起来像这样: cdefgh | abcdefgh | abcdefg
-
value -边框的颜色,如果边框类型为cv.BORDER_CONSTANT
bottle = img[100:300, 360:500]
replicate = cv.copyMakeBorder(bottle,10,10,10,10,cv.BORDER_REPLICATE)
reflect = cv.copyMakeBorder(bottle,10,10,10,10,cv.BORDER_REFLECT)
reflect101 = cv.copyMakeBorder(bottle,10,10,10,10,cv.BORDER_REFLECT_101)
wrap = cv.copyMakeBorder(bottle,10,10,10,10,cv.BORDER_WRAP)
constant= cv.copyMakeBorder(bottle,10,10,10,10,cv.BORDER_CONSTANT,value=[255,0,0])
plt.subplot(231),plt.imshow(bottle,'gray'),plt.title('ORIGINAL')
plt.subplot(232),plt.imshow(replicate,'gray'),plt.title('REPLICATE')
plt.subplot(233),plt.imshow(reflect,'gray'),plt.title('REFLECT')
plt.subplot(234),plt.imshow(reflect101,'gray'),plt.title('REFLECT_101')
plt.subplot(235),plt.imshow(wrap,'gray'),plt.title('WRAP')
plt.subplot(236),plt.imshow(constant,'gray'),plt.title('CONSTANT')
plt.show()

图像的算法操作
图像加法
我们可以通过OpenCV函数cv.add()或仅通过numpy操作res = img1 + img2添加两个图像。两个图像应具有相同的深度和类型,或者第二个图像可以只是一个标量值。
注意 OpenCV加法和Numpy加法之间有区别。OpenCV加法是饱和运算,而Numpy加法是模运算。
>>> x = np.uint8([250])
>>> y = np.uint8([10])
>>> print( cv.add(x,y) ) # 250+10 = 260 => 255
[[255]]
>>> print( x+y ) # 250+10 = 260 % 256 = 4
[4]
图像融合
这也是图像加法,但是对图像赋予不同的权重,以使其具有融合或透明的感觉。根据以下等式添加图像:
G ( x ) = ( 1 − α ) f 0 ( x ) + α f 1 ( x ) G(x)= (1 - \alpha)f_0(x)+ \alpha f_1(x) G(x)=(1−α)f0(x)+αf1(x)
通过从 α \alpha α 从 0 → 1 0\rightarrow1 0→1 更改,我们可以在一个图像到另一个图像之间执行很酷的过渡。
在这里,我找了两个图像,将它们融合在一起。第一幅图像的权重为0.7,第二幅图像的权重为0.3。cv.addWeighted()在图像上应用以下公式。
d s t = α ⋅ i m g 1 + β ⋅ i m g 2 + γ dst=\alpha \cdot img1+\beta \cdot img2 + \gamma dst=α⋅img1+β⋅img2+γ
在这里, γ \gamma γ 被视为零。
img1 = cv.imread('img1.jpg')
img2 = cv.imread('img2.jpg')
dst = cv.addWeighted(img1,0.7,img2,0.3,0)
cv.imshow('dst',dst)
cv.waitKey(0)
cv.destroyAllWindows()
效果如下:
按位运算
这包括按位 AND、 OR、NOT 和 XOR 操作。它们在提取图像的任何部分(我们将在后面的章节中看到)、定义和处理非矩形 ROI 等方面非常有用。
# 加载两张图片
img1 = cv.imread('img1.jpg')
img2 = cv.imread('bottle.jpg')
# 创建ROI
rows,cols,channels = img2.shape
roi = img1[0:rows, 0:cols]
plt.subplot(222),plt.imshow(roi),plt.title("ROI"),plt.xticks([]),plt.yticks([])
# 创建bottle的掩码,并同时创建其相反掩码
img2gray = cv.cvtColor(img2,cv.COLOR_BGR2GRAY)
ret, mask = cv.threshold(img2gray, 10, 255, cv.THRESH_BINARY)
mask_inv = cv.bitwise_not(mask)
# 现在将ROI中bottle的区域涂黑(扣除)
img1_bg = cv.bitwise_and(roi,roi,mask = mask_inv)
# 仅从bottle图像中提取bottle区域
img2_fg = cv.bitwise_and(img2,img2,mask = mask)
# 将bottle放入ROI并修改主图像
dst = cv.add(img1_bg,img2_fg)
img1[0:rows, 0:cols ] = dst
# 预览
plt.subplot(221),plt.imshow(img2),plt.title("BOTTLE"),plt.xticks([]),plt.yticks([])
plt.subplot(223),plt.imshow(mask),plt.title("MASK"),plt.xticks([]),plt.yticks([])
plt.subplot(224),plt.imshow(mask_inv),plt.title("MASK_INV"),plt.xticks([]),plt.yticks([])
plt.show()
# 显示结果
cv.imread("res", img1)
cv.waitKey(0)
cv.destroyAllWindows()
效果:

OpenCV中的图像处理
改变颜色空间
OpenCV中有超过150种颜色空间转换方法。但是我们将研究只有两个最广泛使用的,BGR↔灰色和BGR↔HSV。
对于颜色转换,我们使用cv函数。cvtColor(input_image, flag),其中flag决定转换的类型。
对于BGR→灰度转换,我们使用标志cv.COLOR_BGR2GRAY。类似地,对于BGR→HSV,我们使用标志cv.COLOR_BGR2HSV。要获取其他标记,只需在Python终端中运行以下命令:
>>> import cv2 as cv
>>> flags = [i for i in dir(cv) if i.startswith('COLOR_')]
>>> print( flags )
注意 HSV的色相范围为[0,179],饱和度范围为[0,255],值范围为[0,255]。不同的软件使用不同的规模。因此,如果你要将OpenCV值和它们比较,你需要将这些范围标准化。
对象追踪
现在我们知道了如何将BGR图像转换成HSV,我们可以使用它来提取一个有颜色的对象。在HSV中比在BGR颜色空间中更容易表示颜色。在我们的应用程序中,我们将尝试提取一个蓝色的对象。方法如下: - 取视频的每一帧 - 转换从BGR到HSV颜色空间 - 我们对HSV图像设置蓝色范围的阈值 - 现在单独提取蓝色对象,我们可以对图像做任何我们想做的事情。
cap = cv.VideoCapture(0)
while(1):
# 读取帧
_, frame = cap.read()
# 转换颜色空间 BGR 到 HSV
hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)
# 定义HSV中蓝色的范围
lower_blue = np.array([110,50,50])
upper_blue = np.array([130,255,255])
# 设置HSV的阈值使得只取蓝色
mask = cv.inRange(hsv, lower_blue, upper_blue)
# 将掩膜和图像逐像素相加
res = cv.bitwise_and(frame,frame, mask= mask)
cv.imshow('frame',frame)
cv.imshow('mask',mask)
cv.imshow('res',res)
k = cv.waitKey(5) & 0xFF
if k == 27:
break
cv.destroyAllWindows()
效果:

图像几何变换
变换
OpenCV提供了两个转换函数cv.warpAffine()和cv.warpPerspective(),您可以使用它们进行各种转换。cv.warpAffine采用2x3转换矩阵,而cv.warpPerspective采用3x3转换矩阵作为输入。
缩放
缩放只是调整图像的大小。为此,OpenCV带有一个函数cv.resize()。图像的大小可以手动指定,也可以指定缩放比例。也可使用不同的插值方法。首选的插值方法是cv.INTER_AREA用于缩小,cv.INTER_CUBIC(慢)和cv.INTER_LINEAR用于缩放。默认情况下,出于所有调整大小的目的,使用的插值方法为cv.INTER_LINEAR。您可以使用以下方法调整输入图像的大小:
img = cv.imread('img1.jpg')
res = cv.resize(img,None,fx=2, fy=2, interpolation = cv.INTER_CUBIC)
#或者
height, width = img.shape[:2]
res = cv.resize(img,(2*width, 2*height), interpolation = cv.INTER_CUBIC)
平移
平移是物体位置的移动。如果我们知道在(x,y)方向上的位移,则将其设为( t x t_x tx, t y t_y ty),我们可以创建转换矩阵 M \mathbf{M} M,如下所示:
M = [ 1 0 t x 0 1 t y ] M = \begin{bmatrix} 1 & 0 & t_x \ 0 & 1 & t_y \end{bmatrix} M=[10tx 01ty]
我们可以将其放入np.float32类型的Numpy数组中,并将其传递给cv.warpAffine()函数。参见下面偏移为(100, 50)的示例:
img = cv.imread('img1.jpg',0)
rows,cols = img.shape
M = np.float32([[1,0,100],[0,1,50]])
dst = cv.warpAffine(img,M,(cols,rows))
cv.imshow('img',dst)
cv.waitKey(0)
cv.destroyAllWindows()
效果:

警告 cv.warpAffine()函数的第三个参数是输出图像的大小,其形式应为(width,height)。记住width =列数,height =行数。
旋转
像旋转角度为 θ θ θ是通过以下形式的变换矩阵实现的:
M = [ c o s θ − s i n θ s i n θ c o s θ ] M = \begin{bmatrix} cos\theta & -sin\theta \ sin\theta & cos\theta \end{bmatrix} M=[cosθ−sinθ sinθcosθ]
但是OpenCV提供了可缩放的旋转以及可调整的旋转中心,因此您可以在自己喜欢的任何位置旋转。修改后的变换矩阵为
[ α β ( 1 − α ) ⋅ c e n t e r . x − β ⋅ c e n t e r . y − β α β ⋅ c e n t e r . x + ( 1 − α ) ⋅ c e n t e r . y ] \begin{bmatrix} \alpha & \beta & (1- \alpha ) \cdot center.x - \beta \cdot center.y \ - \beta & \alpha & \beta \cdot center.x + (1- \alpha ) \cdot center.y \end{bmatrix} [αβ(1−α)⋅center.x−β⋅center.y −βαβ⋅center.x+(1−α)⋅center.y]
其中:
α = s c a l e ⋅ cos θ , β = s c a l e ⋅ sin θ \begin{array}{l} \alpha = scale \cdot \cos \theta , \ \beta = scale \cdot \sin \theta \end{array} α=scale⋅cosθ, β=scale⋅sinθ
为了找到此转换矩阵,OpenCV提供了一个函数cv.getRotationMatrix2D()。请检查以下示例,该示例将图像相对于中心旋转90度而没有任何缩放比例。
img = cv.imread('img1.jpg',0)
rows,cols = img.shape
# cols-1 和 rows-1 是坐标限制
M = cv.getRotationMatrix2D(((cols-1)/2.0,(rows-1)/2.0),90,1)
dst = cv.warpAffine(img,M,(cols,rows))
效果:
仿射变换
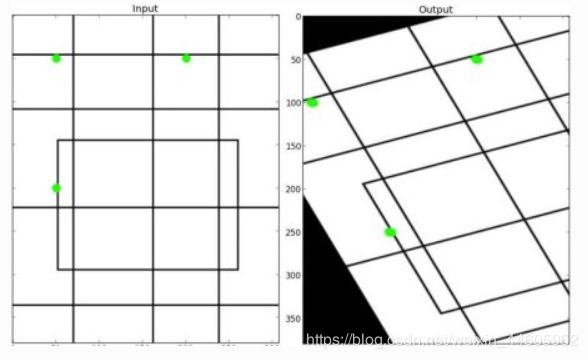
在仿射变换中,原始图像中的所有平行线在输出图像中仍将平行。为了找到变换矩阵,我们需要输入图像中的三个点及其在输出图像中的对应位置。然后cv.getAffineTransform()将创建一个2x3矩阵,该矩阵将传递给cv.warpAffine()。
查看以下示例,并查看我选择的点(以绿色标记):
img = cv.imread('drawing.png')
rows,cols,ch = img.shape
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])
M = cv.getAffineTransform(pts1,pts2)
dst = cv.warpAffine(img,M,(cols,rows))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
效果:
透视变换
对于透视变换,我们需要3x3变换矩阵。即使在转换后,直线也将保持直线。要找到此变换矩阵,我们需要在输入图像上有4个点,在输出图像上需要相应的点。在这四个点中,其中三个不应共线。然后可以通过函数cv.getPerspectiveTransform找到变换矩阵。然后将cv.warpPerspective应用于此3x3转换矩阵。
img = cv.imread('sudoku.png')
rows,cols,ch = img.shape
pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]])
M = cv.getPerspectiveTransform(pts1,pts2)
dst = cv.warpPerspective(img,M,(300,300))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
plt.show()

图像阈值
简单阈值
对于每个像素,应用相同的阈值。如果像素值小于阈值,则将其设置为0,否则将其设置为最大值。函数cv.threshold()用于应用阈值。第一个参数是源图像,它应该是灰度图像。第二个参数是阈值,用于对像素值进行分类。第三个参数是分配给超过阈值的像素值的最大值。OpenCV提供了不同类型的阈值,这由函数的第四个参数给出。通过使用类型cv.THRESH_BINARY完成上述基本阈值处理。所有简单的阈值类型为:
- cv.THRESH_BINARY
- cv.THRESH_BINARY_INV
- cv.THRESH_TRUNC
- cv.THRESH_TOZERO
- cv.THRESH_TOZERO_INV
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('gradient.png',0)
ret,thresh1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
ret,thresh2 = cv.threshold(img,127,255,cv.THRESH_BINARY_INV)
ret,thresh3 = cv.threshold(img,127,255,cv.THRESH_TRUNC)
ret,thresh4 = cv.threshold(img,127,255,cv.THRESH_TOZERO)
ret,thresh5 = cv.threshold(img,127,255,cv.THRESH_TOZERO_INV)
titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in xrange(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()

自适应阈值
在上一节中,我们使用一个全局值作为阈值。但这可能并非在所有情况下都很好,例如,如果图像在不同区域具有不同的照明条件。在这种情况下,自适应阈值可以提供帮助。在此,算法基于像素周围的小区域确定像素的阈值。因此,对于同一图像的不同区域,我们获得了不同的阈值,这为光照度变化的图像提供了更好的结果。
除上述参数外,cv.adaptiveThreshold()还接收三个输入参数:
- cv.ADAPTIVE_THRESH_MEAN_C:该阈值是平均值的附近区域减去恒定的C
- cv.ADAPTIVE_THRESH_GAUSSIAN_C:阈值是邻域值减去常数C的高斯加权和
该BLOCKSIZE确定附近区域的大小和C是从邻域像素的平均或加权总和中减去一个常数。
下面的代码比较了光照变化的图像的全局阈值和自适应阈值:
img0 = cv.imread("IMG.jpg", cv.IMREAD_GRAYSCALE)
img0 = cv.medianBlur(img0, 5)
ret,th1 = cv.threshold(img0,127,255,cv.THRESH_BINARY)
th2 = cv.adaptiveThreshold(img0,255,cv.ADAPTIVE_THRESH_MEAN_C,\
cv.THRESH_BINARY,11,2)
th3 = cv.adaptiveThreshold(img0,255,cv.ADAPTIVE_THRESH_GAUSSIAN_C,\
cv.THRESH_BINARY,11,2)
titles = ['Original Image', 'Global Thresholding (v = 127)',
'Adaptive Mean Thresholding', 'Adaptive Gaussian Thresholding']
images = [img0, th1, th2, th3]
for i in range(4):
plt.subplot(2,2,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()

形态转换
形态变换是基于图像形状的一些简单操作。通常在二进制图像上执行。它需要两个输入,一个是我们的原始图像,第二个是决定操作性质的结构元素或内核。两种基本的形态学算子是侵蚀和膨胀。然后,它的变体形式(如“打开”,“关闭”,“渐变”等)也开始起作用。
原始图像:

侵蚀
侵蚀的基本思想就像仅是土壤侵蚀一样,它侵蚀了前景物体的边界(始终尝试使前景保持白色)。那是什么呢?内核在图像中滑动(如2D卷积)。仅当内核下的所有像素均为1时,原始图像中的像素(1或0)才被视为1,否则它将被侵蚀(设为0)。
因此发生的是,将根据内核的大小丢弃边界附近的所有像素。因此,前景对象的厚度或大小会减小,或者图像中的白色区域只会减小。这对于消除小的白噪声,分离两个连接的对象等非常有用。
在这里,作为一个例子,我将使用一个全是5x5的内核。
import cv2 as cv
import numpy as np
img = cv.imread('j.png',0)
kernel = np.ones((5,5),np.uint8)
erosion = cv.erode(img,kernel,iterations = 1)
结果:

扩张
它与侵蚀正好相反。如果内核下的至少一个像素为“ 1”,则像素元素为“ 1”。因此,它会增加图像中的白色区域或增加前景对象的大小。通常,在消除噪音的情况下,侵蚀后会膨胀。因为侵蚀会消除白噪声,但也会缩小物体。因此,我们对其进行了扩展。由于噪音消失了,它们不会回来,但是我们的目标区域增加了。在连接对象的损坏部分时也很有用。
dilation = cv.dilate(img,kernel,iterations = 1)
结果:

打开
打开只是侵蚀然后扩张的另一个名称。如上文所述,它对于消除噪音很有用。这里我们使用函数cv.morphologyEx()
opening = cv.morphologyEx(img, cv.MORPH_OPEN, kernel)
结果:

关闭
关闭对于打开来说,扩张与侵蚀的顺序是相反的。关闭在前景对象内部的小孔或对象上的小黑点时很有用。
closing = cv.morphologyEx(img, cv.MORPH_CLOSE, kernel)
结果:

图像梯度
OpenCV提供了三种类型的梯度滤波器或高通滤波器,即Sobel,Scharr和Laplacian。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('dave.jpg',0)
laplacian = cv.Laplacian(img,cv.CV_64F)
sobelx = cv.Sobel(img,cv.CV_64F,1,0,ksize=5)
sobely = cv.Sobel(img,cv.CV_64F,0,1,ksize=5)
plt.subplot(2,2,1),plt.imshow(img,cmap = 'gray')
plt.title('Original'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,2),plt.imshow(laplacian,cmap = 'gray')
plt.title('Laplacian'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,3),plt.imshow(sobelx,cmap = 'gray')
plt.title('Sobel X'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,4),plt.imshow(sobely,cmap = 'gray')
plt.title('Sobel Y'), plt.xticks([]), plt.yticks([])
plt.show()

车牌识别的简单小案例
了解完上述的基本知识,我们已经具备了处理简单的车辆图片并从中提取出车牌的能力了,下面我们来动手实现一下吧。
- 图片模糊处理
首先我们需要用高斯滤波让图像中的轮廓减少一些,不然在二值化时会有很多多余的轮廓,这会增加图像处理难度。
img = cv.imread("timg1.jpg")
img1 = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
img1 = cv.GaussianBlur(img1, (5,5), 0)
plt.imshow(img)
plt.show()

(由于颜色通道不匹配的问题,图像较原图有很大色差)
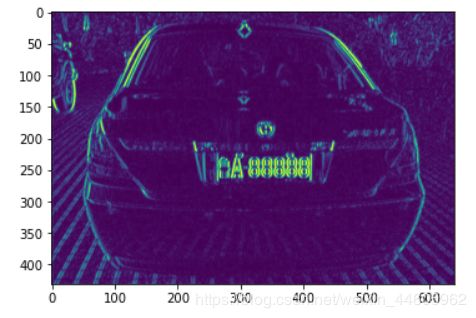
- 边缘检测
接着我们用Soble方法检测图像中的边缘信息。
sb = cv.Sobel(img1, cv.CV_16S, 1, 0)
img1 = cv.convertScaleAbs(sb)
处理后效果:
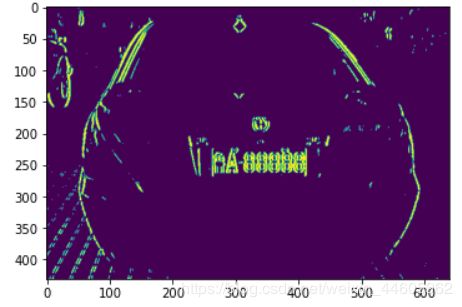
- 二值化处理
接着我们再对边缘明显化的图像进行二值化,更加凸显其边缘信息并过滤掉无用信息,方便我们处理。
_, img1 = cv.threshold(img1, 0, 255, cv.THRESH_OTSU)
效果:
- 中值滤波
我们使用中值滤波过滤掉图片中的噪点和一些小的轮廓。
(卷积核结构只能填奇数)
img1 = cv.medianBlur(img1, 7)
效果:
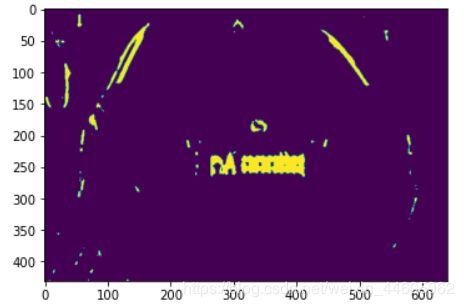
可以看到我们想要的车牌信息已经处理的不错了,但是图内还有很多我们不需要的信息,所以我们继续处理。
- 形态变换
我们使用扩张,目的是为了让车牌号连接在一起成为一个整体。
k = cv.getStructuringElement(1, (10,5))
img2 = cv.dilate(img1, k)
效果:
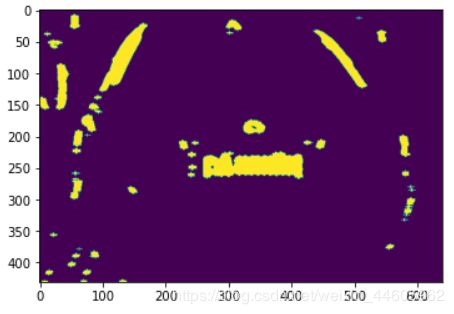
现在我们可以看到车牌信息已经连成了一个整体,并且图片内没有其他形态与其相似的内容,这将大大简化我们的处理难度。
- 查找轮廓
gradients, _ = cv.findContours(img2, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
将图片中所有的轮廓信息都查找出来,然后我们可以大概看出车牌轮廓的宽度是其高度的两倍还多,并且车牌的高度大概为30px以上,所以我们以此为条件,查找符合的轮廓。
for i in gradients:
x, y, w, h = cv.boundingRect(i)
if w > h*2 and h>30:
timg = img[y:y+h,x:x+w]
plt.imshow(timg)
plt.show()
结果:

可以看到我们成功的找到了车牌!
- 处理
最后我们简单的处理一下,在原图上框选出来我们找到的车牌。
cut = cv.copyMakeBorder(timg, 3, 3 ,3 ,3, cv.BORDER_CONSTANT, value = [0, 0, 255])
img[220:270, 255:420] = cut
plt.imshow(img)
plt.show()
结果:

啪啪啪啪啪!()
当然这只是一个非常简单且简陋的车牌识别代码,后面我们会更加深入的学习如何快速、准确且自动的识别出车牌信息dei!
这里是 咸鱼不垫底
不定时更新自己的学习经历,以及分享自己学到的知识!