Marco's Java【面试系列篇之 面试官:你了解线程池么?讲讲它的原理呗!】
前言
或许大家在日常开发中直接使用线程池的场景不会特别多,但是很多开源框架的底层都会使用到它来管理线程,进而降低资源消耗,提高线程的可管理性。因为线程的创建和销毁都是非常耗费系统资源的,如果不妥善的管理线程(例如,我创建了一个线程,但是忘了释放一些资源,那么很可能会造成资源回收不了,同时也带来一些不必要的系统性能损耗),很容易导致系统问题。其实打从一开始接触线程池,我觉得很简单… 因为使用起来没难度,无非就是声明并创建一个线程池对象,加一些七七八八的参数,然后execute或者submit执行就over了。
但是,谈及它的原理,以及底层的实现时,就傻眼了。
文章目录
- 前言
- 从本质上解释为什么需要线程池
- 线程池的工作原理
- 线程池的组成
- 线程池的是如何工作的
- 为什么线程池要这么设计
- 手写一个功能完整的线程池
- 线程池主要参数
- 线程池的资源分配
- 线程池的拒绝策略
- 线程池的任务执行
- 线程池的任务获取
- 线程池的关闭
从本质上解释为什么需要线程池
刚才我们提到了使用线程池可以提高线程的可管理性并降低资源消耗,这个回答其实很笼统,应付的了自己,可应付不了面试大佬啊!
因此,若是被谈及线程池的问题时,我们可以先从这上面两方面去分析。
首先我们要知道一点,创建线程使用是直接向系统申请资源的,Java线程的线程栈所占用的内存是在Java堆外的,而不受Java程序控制,之受限于系统资源,默认一个的线程的线程栈大小为1M(JDK1.5之后为1M,我们可以通过设置-Xss属性设置线程栈大小,但是要注意栈溢出问题),如果每个用户的请求来了,我都去创建一个线程,那么1000个用户瞬间就可以占用我1个G的内存,并且每创建一个都去申请系统资源。可想而知,在没有统一管理线程的情况下,肆意去创建线程,很容易会造成堆栈溢出,进而导致系统崩溃。
并且1000个线程的创建就会执行1000次系统资源的请求,可想而知,这消耗得有多大!再说了,线程切换时会消耗CPU的工作时间,创建过多的线程后,当线程数达到一个阈值,CPU就会什么都不用做了,所有的时间都消耗在线程切换上,而线程根本都没有真正去执行,白忙活!
因此,为了提高线程的可管理性,保证系统的稳定性,我们需要使用线程池来管理线程!
线程池的工作原理
第一关算是过了,面试官连点头,小伙子分析的不错!那我问你,线程池具体由哪几个部分组成?它们的功能是什么?为什么要这么设计… 你给我讲讲它的工作原理吧…
ok… 给我一只笔,给你讲到天亮!谁让你问这么多。
线程池的组成
1. 线程池管理器(ThreadPool):用于创建并管理线程池,包括创建线程池,销毁线程池,添加新任务。
2. 工作线程(PoolWorker):线程池中的线程,用于执行任务。执行任务的线程为忙碌状态,无正在执行的任务的线程为空闲状态。
3. 任务接口(Task):要使用线程池的线程执行某个任务,该任务就必须实现任务接口,它规定了一个任务的入口,状态等。
4. 任务队列(TaskQueue):当有新任务进入线程池,如果此时线程池中没有空闲线程可以用来执行任务,则任务会被暂存在任务队列中。
一个完整的线程池包含上面几个组件,举个很简单的栗子,线程池管理器就是银行行长(管事儿的),工作线程就是办理银行业务的小姐姐(真正执行任务的),任务接口就相当于一个头衔(员工归属于哪个银行下的哪个支行,闲杂人等不得入内),任务队列就是在银行办理业务的我们排起的队列。
线程池的是如何工作的
啥也不说了,先给咱们的面试官画张图,接着娓娓道来线程池的工作原理…
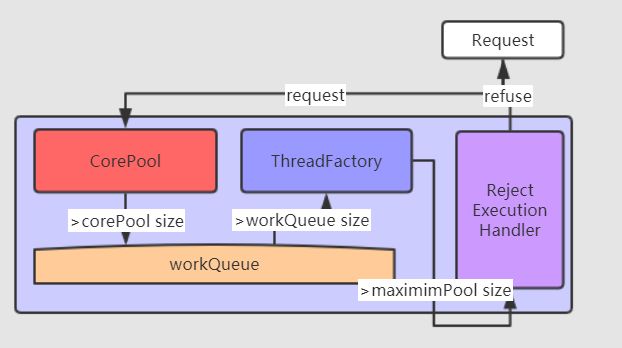
首先,一个请求过来了,此时线程池需要创建一个线程去执行任务,这里执行任务的线程就是Worker(实现了Runable接口),在创建线程的这个过程中历经了下面几个步骤。
1)获取当前线程池的状态,确认当前的线程池是否shutdown
2)若线程池没有被关闭,且当前的线程数量小于coreSize核心线程数,则创建一个新的线程
3)若超过coreSize,且当前的线程还处于运行状态,且workQueue还没满的情况下,将任务添加到阻塞队列中(本质上是一个BlockingQueue)
4)再次进行检查,如果线程池停止工作且当前任务可以被移除,则移除任务并且拒绝新的任务,否则继续添加任务,若等待队列被占满,则继续创建新的线程直到maxSize最大线程数
5)若当前工作线程数超过maxSize,则直接执行RejectExecutionHandler的拒绝策略
在ThreadPoolExecutor的execute方法源码中也能体现出这一点。
public void execute(Runnable command) {
// 判断当前是否有任务
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 当小于核心线程数时,添加worker并执行任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 若线程池仍处于正常工作状态,并且队列中还没有满的情况下执行
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 再次检查,如果线程池停止工作且当前任务可以被移除,则移除任务并且拒绝新的任务
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
为什么线程池要这么设计
这个问题其实很笼统,因为要谈到的点会比较多,其实如果真的有面试官问到为什么线程池要这么设计的时候,我们可以从下面几个点去分析
|- 为什么会有coreSize、workQueue和maxSize的概念?
|- 为什么coreSize满了之后不继续创建线程而要放入workQueue?
|- 为什么需要有保活机制?
先说第一个点,其实coreSize、workQueue和maxSize只是一种理念,在Java中我们可以看到很多这种栗子,就好比JVM中的堆栈大小会有初始堆栈大小和最大堆栈大小,当你所需要的资源没那么多的时候,小一点就够用了,一旦你的资源量大了,我还有弹性空间,当然如果你对数据的预估已经很精准了,比如说你知道每秒的请求数量并且访问量非常平稳,那么你也可以一次性到位,将最小值和最大值设置为一样的(当然这种情况不常见)。
我们再谈谈第二个点,首先我们知道线程的创建是非常消耗资源的,需要内存态到用户态的切换,这一点显然已经达成共识,那么试想,当coreSize满了之后,我们还继续创建线程直到maxSize,那么这就没有coreSize存在的意义了!直接设置个maxSize得了!显然workQueue就是为了解决这个问题,因为我们知道,每秒的请求量其实是不均衡的,时多时少,那么当请求多的时候(不考虑请求多到超过阻塞队列大小),我将任务放入阻塞队列,等不忙的时候,我再从队列取出任务,执行任务,那么此时我用有限的资源(coreSize)解决了多request的问题(相对)。是不是很棒!
其实最后一个问题也很好理解,不仅线程的创建消耗资源,存在着的线程更是占用资源(内存方面),因此当任务没有那么多的时候,线程池中的线程就会空闲下来,当线程等待任务超过了keepAliveTime之后,没有任务可收就会被remove掉,从而节省一部分开销,此时的线程就好比公司里的"闲人",公司没有那么多活,你也不做事,就被开除了…
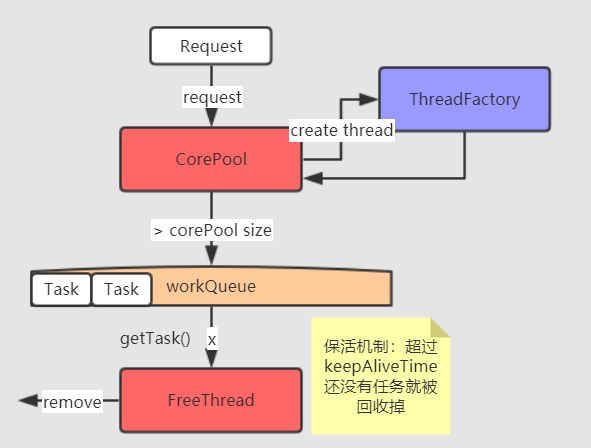
当然,在线程池中,对于核心线程超时也可以设置为回收,需要执行下边这个方法,确保核心线程超时之后也被回收。
threadPoolExecutor.allowCoreThreadTimeOut(true);
手写一个功能完整的线程池
正所谓好记性不如烂笔头… 可能源码看了一大堆,觉得自己已经懂了,那还不够!凡事得自己做一遍、写一遍,才会记得清!这样再有关于线程池方面的问题就完全不虚了!当然了,本次手写的线程池只追求功能完整,核心逻辑一致,属于精简版啦!
线程池主要参数
通过上面的一顿分析,相信大家对下面的线程池参数应该也不陌生了(略有修改,换了个名字…)
// 线程池主锁
private static final ReentrantLock mainLock = new ReentrantLock();
// 核心线程数
private volatile int coreTheadSize;
// 最大线程数
private volatile int maxSize;
// 线程最长存活时间(保活时间)
private long keepAliveTime;
// 时间单位
private TimeUnit unit;
// 等待队列
private BlockingQueue<Runnable> workQueue;
// 存放线程池
private volatile Set<Worker> workers;
// 线程池中的总任务数
private AtomicInteger totalTask = new AtomicInteger(0);
// 线程池是否关闭
private AtomicBoolean isShutDown = new AtomicBoolean(false);
// 拒绝线程通知器
private volatile RejectHandler handler;
// 线程池被shutdown功能中,唤醒线程的锁
private Object shutDownNotify = new Object();
线程池的构造函数如下,注意这里的核心线程数、最大线程数以及保活时间不能小于0且阻塞队列不能为空哦。另外存储工作线程的线程池workers使用的是ConcurrentHashSet,因为在 j.u.c 源码中workers是一个 HashSet ,并且对他所有的操作都是需要加锁(使用ReetrantLock)。因此需要一个线程安全的Set。

当然ConcurrentHashSet在jdk中是没有的,通过自定义类集成AbstractSet,其内部本质上就是使用ConcurrentHashMap进行存储啦!因为ConcurrentHashMap 的 size() 函数并不准确,所以这里单独利用了一个 AtomicInteger来统计容器大小,从而保证线程安全。源码如下。

线程池的资源分配
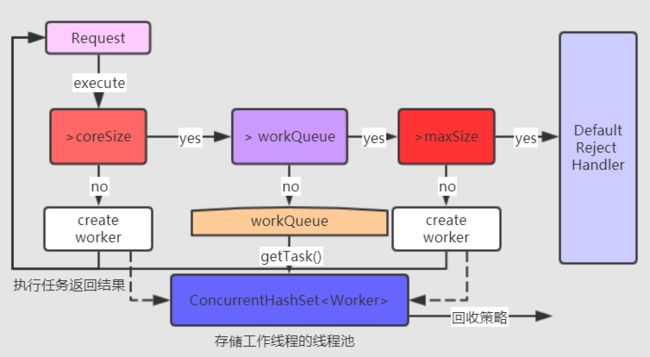
execute(Runnable runnable)作为线程池的核心方法,主要为是为了合理安排线程池中的线程执行请求,进行线程的分配、调度(下图的逻辑),注意这里的totalTask(线程池中的总任务数)为AtomicInteger,保证线程安全。addWorker()方法本质上就是创建一个Worker对象去执行请求。workQueue.offer(runnable)用于判断当前的workQueue是否可再添加,如果不可加则返回false,可加则添加到workQueue(下面多处会涉及到BlockingQueue的操作,因此我总结了常见的操作,及其相应返回值类型)。
| 操作 | 抛出异常 | 特殊值 | 阻塞 | 超时 |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| 移除 | remove(e) | poll(e) | take(e) | poll(time, unit) |
| 检查 | element() | peek() | - | - |
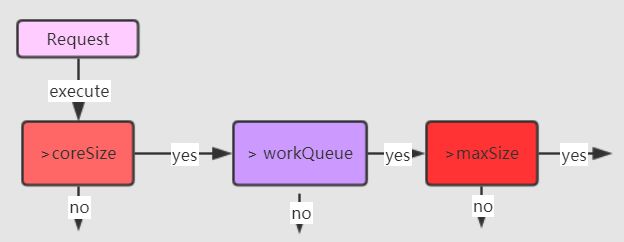

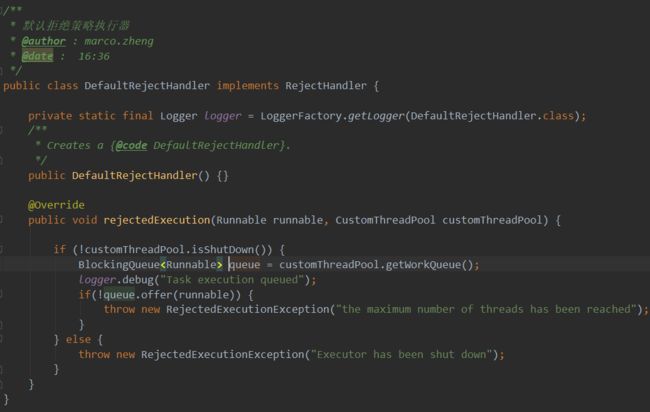
线程池的拒绝策略
这里的reject(runnable)本质上是调用了我们传进来的DefaultRejectHandler的rejectedExecution()方法,该类实现了RejectHandler接口,并实现rejectedExecution(Runnable runnable, CustomThreadPool customThreadPool)方法。内部实现比较简单,主要是判断线程池中的阻塞队列到底还能不能放任务进去,如果不能放了,就抛出异常,拒绝接收请求。customThreadPool.isShutDown()部分也是相当有必要的,因为我们的一系列操作都是基于线程池正常工作的前提下进行的。
线程池的任务执行
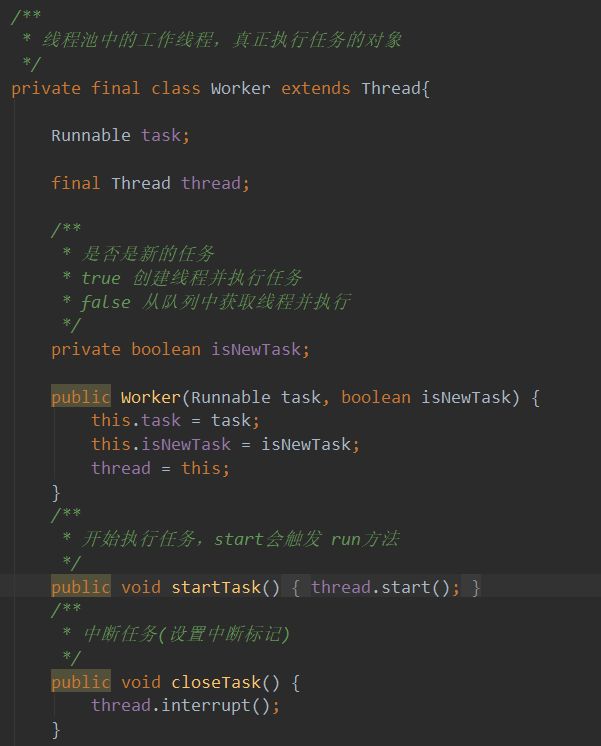
如上面所讲,addWorker() 就是创建了一个worker线程(可以添加ThreadFactory来创建worker),利用它的 startTask() 方法来执行任务,不要忘了将这个线程加入线程池复用。

说了半天,我们来看看 Worker 对象里面有些啥(在ThreadPoolExecutor中Worker是他的一个内部类)。上面我们提到了Worker本身也是一个线程,将接收到需要执行的任务存放到成员变量 task 处。
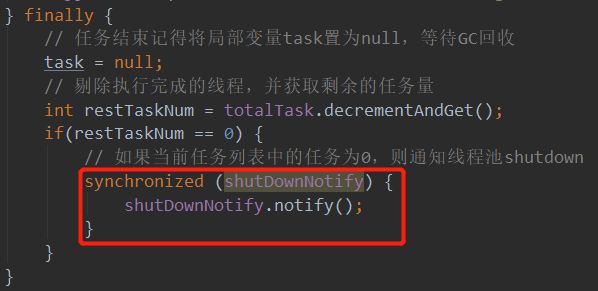
而其中最为关键的则是执行任务 worker.startTask() 这一步骤。它调用了Worker重写Thread的run()方法,这里的逻辑相对较复杂,首先我们要知道将要执行的任务是不是新的任务,如果是则直接执行新的任务,若没有新的任务了,就去阻塞队列里面取任务,这里有个注意点,就是我们方法中的任务task对象其实就是实际执行任务对象,只不过做了一个引用而已,因此任务执行完成之后,最好是手动的给设置为null,让GC清理掉这个无用的对象。任务执行完成之后记得剔除执行完成的线程,并获取剩余的任务量。这里的shutDownNotify.notify()我们后面讲到线程关闭的部分会详细讲解。
@Override
public void run() {
Runnable task = null;
// 如果是新的任务,那么将当前传递过来的task对象的引用给到局部变量task
if(isNewTask) {
task = this.task;
}
// 是否编译
boolean success = true;
try {
// 如果没有新的任务,则直接调用getTask()从workQueue中获取任务
while (null != task || null != (task = getTask())) {
try {
// 执行当前任务
task.run();
} catch (Exception e) {
// 如果任务执行发生异常,设置标志位为false
success = false;
logger.error("the task was executed with wrong, error stack is {}", e.getStackTrace());
} finally {
// 任务结束记得将局部变量task置为null,等待GC回收
task = null;
// 剔除执行完成的线程,并获取剩余的任务量
int restTaskNum = totalTask.decrementAndGet();
if(restTaskNum == 0) {
// 如果当前任务列表中的任务为0,则通知线程池shutdown
synchronized (shutDownNotify) {
shutDownNotify.notify();
}
}
}
}
} finally {
// 当线程行完任务之后释放线程资源
boolean remove = workers.remove(this);
logger.info("current thread is removed, the rest number of workers is {}", workers.size());
if(!success) {
// 可以根据需求拓展一些操作
}
tryClose(true);
}
}
注意,在线程执行完成之后,如果没有新的任务,且在线程可以被remove的情况下,可以清理没有在工作的线程。
线程池的任务获取
我们再回到线程池的任务获取getTask()方法,它用于从workQueue中获取任务,整个过程需要加锁,保证线程安全。当worker工作线程数量大于核心线程数量时需要用保活时间获取任务,如果当前的队列中没有任务,最多等keepAliveTime(单位为秒或者毫秒),过了规定时间没有收到任务则返回null,如果workers.size() < coreTheadSize,则一直阻塞并进入等待状态,直到Blocking有新的对象被加入为止。
private Runnable getTask() {
ReentrantLock mainLock = this.mainLock;
// 关闭标识以及任务是否全部完成了
if(isShutDown.get() && totalTask.get() == 0) {
return null;
}
// 获取任务时可能涉及到并发获取,因此需要对此操作上锁
mainLock.lock();
try {
Runnable task = null;
if(workers.size() > coreTheadSize) {
// 当大于核心线程数量时需要用保活时间获取任务
// (取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间,取不到时返回null)
task = workQueue.poll(keepAliveTime, unit);
} else {
// 取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到Blocking有新的对象被加入为止
task = workQueue.take();
}
if(null != task) {
return task;
}
} catch (InterruptedException e) {
logger.error("current task is null");
return null;
} finally {
mainLock.unlock();
}
return null;
}
线程池的关闭
线程池的关闭分两种情形:正常关闭和强制关闭
- 正常关闭:不接受新的任务,并等待现有任务执行完毕后退出线程池。
- 强制关闭:执行关闭方法后不管现在线程池的运行状况,直接结束所有任务,这样可能会导致任务丢失

我们可以对比这两种关闭方式的区别,强制关闭很简单,无非就是设置线程池的ShutDown标志为true,并且调用tryClose(false),当isTry为false时,无论是否有线程在工作,都直接关闭。
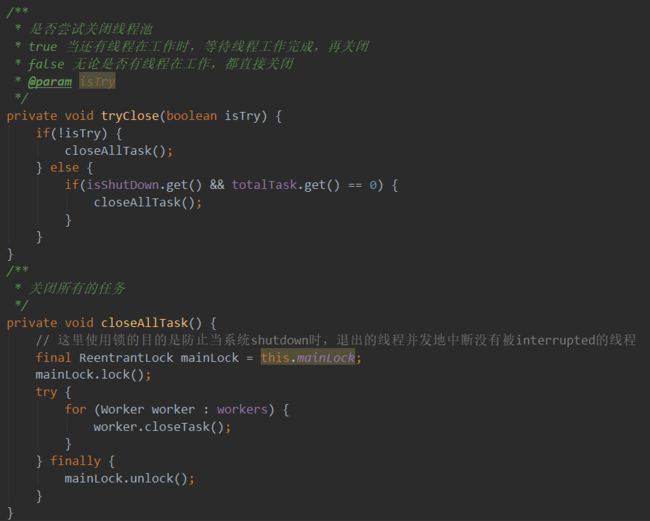
这里有个细节,也就是worker.closeTask()方法,实质上是调用了线程的thread.interrupt()方法,该方法执行之后并不会立即中断线程,而是将线程的中断标志位设置为true,此时我们可以通过isInterrupted()方法判断线程是否终止,做一些逻辑上的处理,当然,如果线程中有阻塞方法,例如sleep()、join()等,那么一旦调用thread.interrupt()方法,则会抛出InterruptedException异常来中止线程。
还有一个细节就是刚才我们提到的shutDownNotify这个"锁"的用途,当我们正常ShutDown线程池时,会执行截图一的方法,判断是否还有任务在执行中,如果在执行中,则阻塞主线程不要关闭线程池。
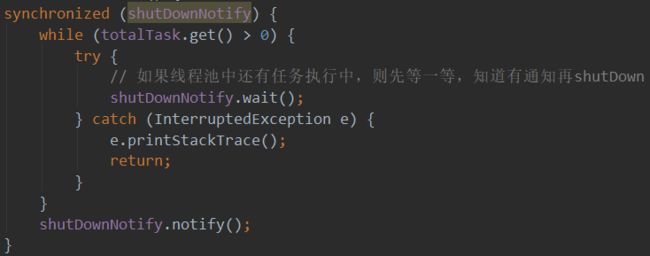
截图二是从run()方法中抠出来的部分,意思是,当任务执行完成并且剩余的任务数为0时,则通知主线程可以关闭线程池了。
总的来说,当执行了 shutdown 方法后会将线程池的状态置为关闭状态,此时 worker 线程尝试从队列里获取任务时就会直接返回空,如果没有任务,那么 worker 线程就会被回收。一旦线程池大小超过了核心线程数就会使用保活时间来从队列里获取任务,一旦获取不到任务返回 null 时也会触发回收。
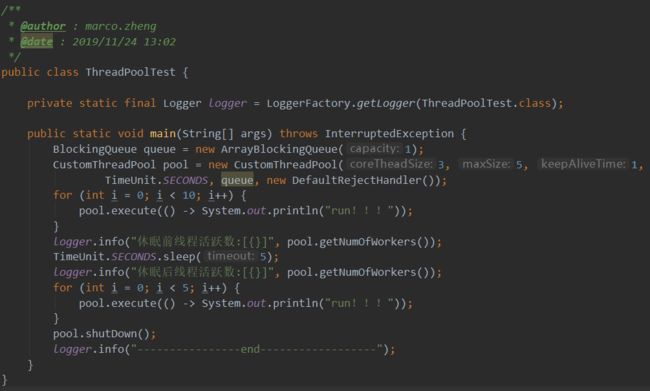
接下来我们测试下线程池的效果
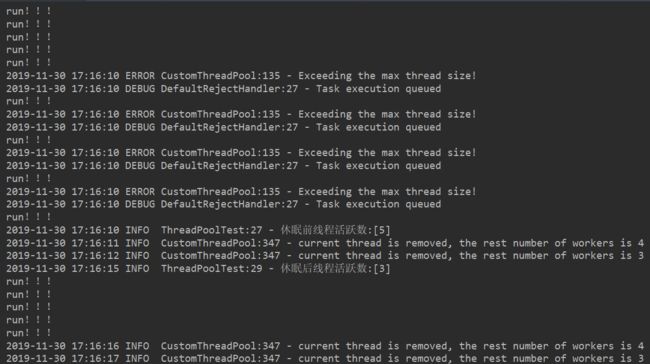
不难发现,当请求数量超过了最大可创建线程的数量时,会被拒绝策略器回绝掉,此时的线程数量为maxSize,当没有任务的时候,会回收线程,可以看到休眠之后线程数量从5变为3。
当我把阻塞队列的数量设置为7的时候,coreSize仍然为3,请求的数量为10,可以看到休眠前后的线程数量都为3,最终的线程数量也为3,并没有被回收。
