转移猜测-CA
文章目录
- 前景
- 提高流水线效率的技术
- 龙芯2号处理器核结构图
- 转移指令
- 控制相关
- 转移指令对性能的影响
- 转移指令的属性
- MIPS指令系统的转移指令
- 程序的转移行为
- 各统计结果
- 分支的可预测性
- 总结
- 解决转移条件相关的方法
- 方法综述
- 软件方法解决控制相关
- 硬件动态转移预测
- 动态转移猜测小结
- 常见处理器的转移预测
- 一些典型商品处理器的分支预测机制
- Alpha 21264的分支预测器
- Pentium IV的转移预测器
- Power4转移预测器
- MIPS R10000的转移预测器
- 龙芯2号分支预测器
- 常见处理器的分支预测(最近)
- 分支预测未来
前景
提高流水线效率的技术
(1)指令流水线:
• 多发射:多车道
• 动态调度:允许超车
(2)喂饱“饥饿”的运算器:
• 转移猜测:提供足够的指令
• 存储管理:提供足够的数据
• 冯诺依曼结构:存储程序和顺序执行
龙芯2号处理器核结构图

转移指令
控制相关
- 如果转移指令计算下一条指令地址在EX阶段计算,下一条指令等2拍 ;
- 解决方法:
①使用专门的地址运算部件把地址计算提前到译码阶段可以少等一拍:

②使用一个delay slot可以不用等待,但是多发射情况下延迟槽成为需要专门照顾的负担:

转移指令对性能的影响
(1)分支指令的影响是开发指令级并行性的重要障碍:
• 一条指令流中,平均每5-7条指令中就有一条是分支指令,也即基本块大小为5-7条指令
(2)增大发射宽度:
• 在发射宽度为n的处理器中,遇到分支指令的速度也快了n倍
(3)增加流水线深度:
• 流水线越深,处理分支指令所需要的时钟周期数就越多
(4)例子:
假设平均每8条指令中有一条转移指令,某处理器采用4发射结构,第10级流水解决转移地址相关(即第10级流水算出转移方向和目标):
(每次转移出问题,流水线停顿9拍,这9拍可发射36条指令,即浪费的指令带宽)
①在A系统中不进行转移预测,遇到转移指令就等待:
-指令带宽浪费36/(36+8)=82%; //相当于没发射8条指令,浪费一次
②在B系统中进行简单的转移预测,转移猜错率为50%,那么平均每16条指令预测错误一次:
-指令带宽浪费36/(36+16)=75%
③在C系统中,转移指令猜错率为10%,那么平均每80条指令预测错误一次:
-指令带宽浪费36/(36+80)=31%;
④在D系统中,转移指令猜错率为4%,平均每200条指令预测错误一次:
-取指令带宽浪费36/(36+200)=15%。
转移指令的属性
(1)条件转移与无条件转移:
• 条件转移:需等待条件确定后才能取指,程序中多数转移指令是条件转移指令
• 无条件转移:不用判断条件就转移,如call/return
(2)直接转移与间接转移:
• 直接转移:转移目标根据指令内容直接得出
• 间接转移:转移目标在寄存器中
(3)相对转移与绝对转移:
• 相对转移:转移目标为当前PC值加上偏移量
• 绝对转移:转移目标由指令或寄存器内容直接给出
由上可知:理论上有8种组合:实际上不实现所有组合
MIPS指令系统的转移指令

程序的转移行为
各统计结果
(1)SPEC CPU2000转移指令统计—龙芯2号统计结果


(2)转移指令间距离统计:
发射宽度增加,分支间的动态距离就会越小,分支预测的延迟对性能的影响就越大,当要求更高的发射宽度时,需要每个周期做不止一个预测;
例:Inter-branch distance(cycles) ,模拟环境:4发射乱序机器 @SPECint2000

(3)不同类型转移指令分布:
龙芯2号上部分SPEC CPU2000程序中转移指令分布:
• 1%是间接分支指令,采用BTB预测
• 5%是返回指令,返回地址栈RAS预测
• 29%是无条件立即跳转指令,跳转地址在指令中
• 65%是条件分支,大量的工作是进行条件分支预测
(4)转移指令的执行频率分布:
龙芯2号上部分SPEC CPU2000程序转移指令执行频率分布:
• 所有转移指令的44%仅仅执行99次或者更少,这44%的转移指令占所有转移指令总执行次数的0.03%;
• 只有4.2%的转移指令执行了超过100000次或者更多,占所有转移指令总执行次数的87%(或者说,只有14.7%的转移指令超过了10000次,占所有转移指令总执行次数的97%)。
(5)转移成功率分布:
龙芯2号上部分SPEC CPU2000程序转移指令的跳转成功率:
• 45%的指令总是跳转,15%的指令总是不跳转;
• 20%的指令跳转的几率小于5%或者大于95%;(80%的转移指令具有强烈的一个跳转方向,具有挑战性的工作是预测其余20%转移指令的跳转方向)
分支的可预测性
(1)利用单个转移指令的重复性:
基于模式的预测方法
- 循环型分支:
• for型循环:TT…TN(成功n次后跟一次不成功 )
• while型循环:NN…NT(不成功n次后跟一次成功) - 周期重复模式型分支:
• 定长重复模式类分支:{pat}^q , |pat|=k (每隔k个分支模式就重复一次)
• 块模式类分支:{T^n Nm}q, 成功n次,不成功m次,如此循环
(2)利用不同转移指令之间的关系:
基于相关的预测方法
- 利用指令间的方向相关
• 两个分支的条件(完全或部分)基于相同或相关的信息
• 第二个分支的结果基于第一个分支的结果产生

- 利用指令间的路径相关
• 如果一个分支是通向当前分支的前n条分支之一,则称该分支处在当前分支的路径之上(Y和Z在通往X的路径上)
• 处在当前分支路径上的分支与当前分支结果之间的相关称为路径相关;

(3)利⽤函数调⽤的递归性:
总结
- 分支指令是很频繁的
- 分支指令有较好的局部性
- 分支指令具有可预测性
解决转移条件相关的方法
方法综述
(1)阻塞:
- 等待直到转移条件确定
(2)用延迟槽容忍延迟:
- 延迟槽指令来源
(3)编译器优化:
- 循环:循环展开减少转移指令、软流水减少阻塞
- 分支:全局代码调度(越过分支调度指令)
- 函数调用:inline
(4)转换为数据相关:
- 条件指令、谓词
(5)硬件转移预测:
- 转移条件未确定时预测转移是否成功
- 静态与动态预测
软件方法解决控制相关
(1)利用延迟槽:
- 延迟槽指令的来源:
- 来自转移指令前:肯定执行
- 来自转移目标地址:转移成功才执行
- 来自转移不成功地址:转移不成功才执行 - 单延迟槽的编译效果:
- 能为 60% 左右的转移延迟槽找到有效操作
- 大约80%的延迟槽指令用于有效计算
- 因此大约50% (60% x 80%) 的延迟槽操作用于有效计算 - 延迟槽的限制:
- 超流水情况下一条延迟槽不够
- 多发射情况下延迟槽反而成为需要特殊照顾的兼容负担
(2)软件循环展开消除控制相关
-
方法:软件展开两个循环
①. 循环展开
②. 寄存器重命名
③. 变换次序

-
软件循环展开的不足:
- 有些循环不好展开(如循环次数不定的循环)
- 增加指令CACHE的负担 -
循环的数据相关:

- 循环内相关:
-S2使用同一次循环中S1计算的A[i+1]。
-导致一个循环体内的多条指令不能并行执行;
- 循环间(loop-carried)相关:
-本次循环计算的A[i+1]/B[i+1]将被下一次循环使用。
-导致多个循环体不能并行执行
把循环间相关转换为循环内相关 -
循环展开的条件:
- 数组元素相关的判断:
数组元素两种类型:

- 名字相关的消除:重命名技术
- 指针相关的判断:只有一些经验的方法 -
循环间相关的解决—软流水:
• 新循环体的每个操作来自不同的循环体,以分开数据相关的指令,相当于软件的Tomasulo算法;
• 符号级循环展开,比真正循环展开代码开销小;

(3)把控制相关转换成数据相关:
-
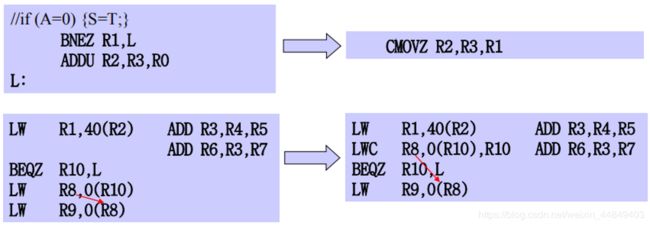
把条件转移指令转换为条件执行:
(条件指令的条件作为指令执⾏阶段的⼀个输⼊,实际上把控制相关转化为数据相关)
- if (x) then A = B op C else NOP (在执行阶段判断x是否为0) //CMOV A ,B , X

- 只有条件为真时才写结果,为假时不写结果也不发生例外
- RISC系统如Alpha, MIPS, PowerPC, SPARC都增加了条件MOVE指令; PA-RISC的nullification
- EPIC: 使用64个1位的谓词寄存器来选择是否写执行结果 -
条件指令的缺点:
- 条件为假时仍需要1拍,占用发射槽和功能部件
- 条件未确定仍需要在执行前等待,转移猜测反而在执行后
- 条件复杂时会降低效率,因为条件在执行时才确定 -
条件指令举例:
- 假设转移指令没有延迟槽
- 条件指令可消除简单的条件转移,对取绝对值等操作有用
- 条件指令仍要在执行前等待条件,注意例外的处理
硬件动态转移预测
(1)基本思路:
- 在取指或译码阶段预测转移是否成功以及转移目标进行后续指令的取指
• 以减少指令流水线由于控制相关而堵塞 - 在执行阶段判断转移预测是否正确
• 如果猜测正确,则正常提交
• 如果猜测错误,则取消该转移指令及其后续指令
(2)基本原理:
1)猜测依据:
• 当前指令的地址(PC)和性质(是否转移指令)
• 过去转移指令历史记录
2)猜测内容:
• 转移方向、转移目标地址
3)原理图示:

(3)分支处理机制的性能取决于:
- 预测精度(BPA)=> 设计好的预测器
• 预测精度越高,能抽取的并行性就越多 - 预测正确所付的代价:转到目标地址处执行所需的延迟
• 译码时根据IR内容预测:有一拍的延迟槽,在4发射情况下有4条指令的延迟槽
• 取指时根据PC预测:没有延迟槽,需要BTB/Trace Cache等机制
• MIPS R10000无BTAC,MIPS R12000有32项BTAC - 预测错所付的代价:
• 尽量提前执行转移操作
• Pentium II/III和Alpha 21264重新刷新流水线需要11周期以上
(4)转移预测关键技术:
1)如何保证准确的预测:根据记录的历史进行预测
• 如何记录转移历史,记录哪些转移历史
• 记录多少转移历史
• 何时更新:更新太早,转移指令也可能被取消;更新太晚,导致转移历史不准确
2)如何在取消猜测执行的操作时保证现场精确性
• 增加提交流水级,在提交时修改寄存器(寄存器重命名)和内存(write buffer机制)
• I/O指令的猜测执行难以取消
3)如何识别流水线中的指令哪些需要取消,哪些不要取消
• 例外取消一般在提交时,取消所有后续指令
• 转移取消一般在执行后,只取消部分指令
要求有⼀种机制来判断指令流⽔线中的每⼀条指令和错误预测的转移指令的先后关系。
4)延迟槽指令的处理
5)每个周期多个分支预测
• 每周期1个预测,基本可满足4-6 发射需要的取指带宽
(5)高性能性能转移预测机制特征:
① 减少预测延迟槽 (如⽤根据PC预测的BTB/BTAC等机制);
② 在执⾏阶段尽早确定转移结果,降低错误预测的开销;
③ 在转移预测错误时要有⾼效的流⽔线刷新机制;
④具有⾼预测精度的转移预测机制;
(6)静态/动态转移预测:
- 静态预测:总是预测转移成功或总是预测转移不成功
• 预测转移成功:较精确,计算转移地址需要delay slot
• 预测转移不成功:直接用PC+4 - 动态预测:根据转移指令执行历史进行预测
• 复杂预测技术:精确、控制复杂 - 混合预测:利用编译器的提示,结合动态和静态预测
(7)局部转移预测:
- 独立考虑单个循环的历史记录,寻找其中的重复性规律,并根据该规律预测未来的转移行为;
- 对于重复性特征明显的转移指令(如循环)效果好;
- 例子:
• for (I=0, I<10; I++){ }
• 转移模式为(1111111110)^n
(8)利用单个分支的重复性—BHT
1)转移历史表BHT(Branch History Table):
• 用PC的低位索引,每项1位 (可能两条转移指令的PC低位相同 ,从⽽引起冲突)
• 记录同一项上次转移是否成功,表示是否转移成功
(具有上述两项特征的BHT表,1位,称为PHT表)
• 不进行地址比较检查(cache,tag用于地址比较检查)(因为即使预测错误也还有纠正措施)
2)问题:

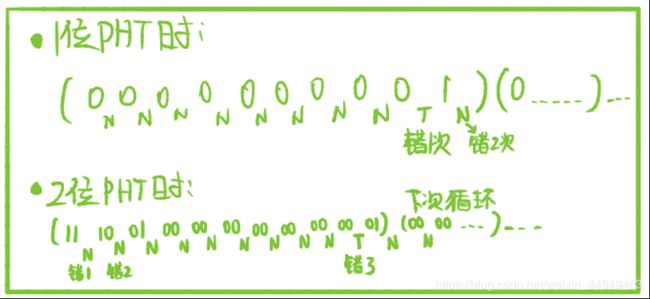
对循环进行猜测时,1位BHT(PHT)引起两次猜错:
(1位PHT表预测时仅看该转移指令上次跳转是否成功)
①循环退出时,转移方向不一致
②进入循环时,和上次退出时的转移方向不一致
3)改进:两位BHT表—转移历史表
- 特点:只有连续两次猜错,才会改变猜测方向
- 要求:
- 12位PC索引:4096项已经足够,和无穷项效果差不多;
- BHT表2位已经足够, n位 (n>2)与2位效果差不多; - 预测机制:
- 执行动作:转移指令每次转移成功(这里的转移成功是指:分支真是的跳转情况)加1,加到3为止;转移不成功减1,减到0为止;
- 预测方向:转移预测时,若相应PHT表项的高位为1(计数器的值为2或3)就预测跳转;高位为0(计数器的值为1或0)就预测不跳转; - 功能结构:

- 缺点:
①仅能预测转移指令⽅向,⽆法预测跳转⽬标;
②仅在译码阶段使⽤ ,仅只使⽤PC低位索引 ,可能把普通指令也当作转移指令进⾏预测; - 例子说明:
在前述两重循环的例子中,循环预测准确率从:
(8+80)/(10+100)= 80% //“8”外层循环错两次;“80”内层循环错20次
提高到:
(7+88)/(10+100)= 87.2%
(9)减少猜测延迟—转移目标缓冲器BTB
- 使用CAM结构,在取指阶段根据当前PC值预测转移方向和转移地址:
- 需要进行地址全相等比较;
- 直接预测PC值而不是根据指令内容计算;
- 失效时进行替换; - 硬件结构:

- 缺点:
①表项复杂 ,需全相联查找,不能做⼤;
②BTB需配合PHT;
(10)RAS:返回地址栈
- 返回地址栈(Return Addresses Stack)预测返回地址
- 函数调用时压栈,返回时从栈顶弹出作为返回地址
- 针对函数调用有很高的预测准确率
(11)BHR转移历史寄存器—转移指令的相关性
1)作用:记录所有转移指令的历史
2)实现方式:
移位寄存器:处理器执行转移指令,就把BHR左移1位,左移时最高位扔掉,最低位如果转移成功就填1,否则填0;
3)m位的BHR记录了处理器M次的转移历史;
4)BHR表:为每条转移指令单独记录 BHR ,再把多个BHR组织在⼀起的表
5)2位分支预测之后,预测正确率难以提高,主要原因是分支指令的相关性

(12)Yeh和Patt分类:
1)当前的转移依赖于两种情况:
• 该指令的过去m次转移记录:PHT(Pattern History Table)
• 程序中所有转移指令过去m次的转移记录:BHR(Branch History Register)
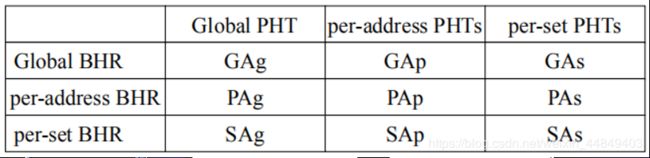
- BHR的组织:
- “PA”表示per address BHR // 每条转移指令都有自己的BHR,用PC索引BHR;
- “GA”表示global address BHR //所有转移指令共用一个BHR;
- “SA”表示set address BHR // 用PC的低位索引BHR - PHT的组织:
- 只用历史记录索引PHT表,用“g”表示
- 用全地址和历史记录一起索引PHT表,用“p”表示
- 使用部分地址和历史记录一起索引PHT表,用“s”表示
2)两层自适应预测器组合情况:
• BHR: Branch History Register
• PHT: Pattern History Table
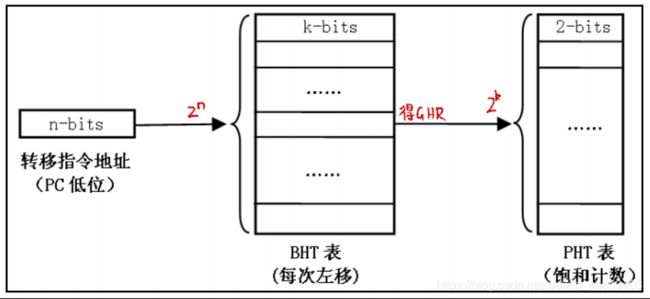
①GAg结构:
- BHR和PHT都是全局的,全局的BHR又称为GHR(Global History Rigster)。
- 其中GHR存储过去k次转移历史,并用GHR的k位值去索引2k个入口的PHT,
- PHT每项利用2位饱和计数器进行预测。

②GAs结构:
- 其中BHR表还是全局的,只有k位;
- PHT表用k位的GHR和PC的低n位进行索引,因此一共有2^(k+n)项。

③SAg(k)的结构:
- PHT是全局的,BHR寄存器一共有2^n个,每个BHR为 k位。
- 先用PC的低n位索引GHR,然后再用GHR的值索引PHT表。
④PAp(4)结构:
- 每个PC值一个BHR寄存器,每个BHR为k位。
- 先用PC索 引BHR,然后再用BHR的值和PC一起索引PHT表。
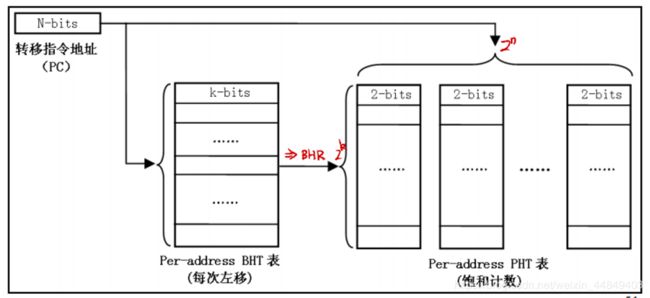
(13)分支别名干扰问题:
1)模式:
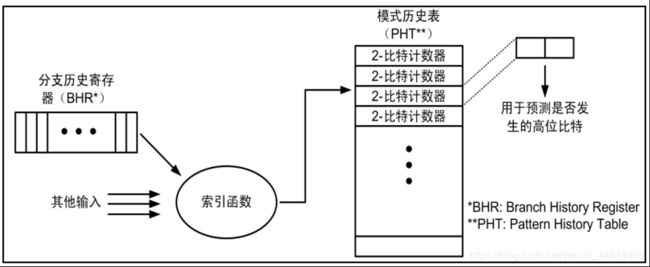
- 无论BHR和PHT表如何增大,效果也不是很明显
- 主要原因是不同分支地址访问同一个PHT,造成分支干扰
- ⾃从⼆级转移预测器出现来 ,预测精度⼀般在92%左右 。
2)分支别名干扰的消除:
①Gselect:全局历史m位和地址n位组合寻址

②Gshare: 部分地址和全局历史异或寻址

性能分析结果表明:gshare稍微好于gselect
(14)Agree分支预测:

- 分支预测缓冲区BTB:在指令Cache或转移目的地址缓存(BTB)中为每一个转移都加上一个偏向位,偏向位中保存的是这条指令最常见的转移方向。
(偏向位依据:前面分析的多数转移指令具有强烈跳转或者不跳转倾向性) - Gshare预测器:2位计数器不是用来预测转移方向的,而是用来决定是否按照偏向位来转移的。
- 当转移的实际结果与偏向位一致时,计数器加一,否则减一
1)举例计算说明:
2条分支预测正确率分别为 85%和15%,使用同一项PHT
- 传统方法 - 两条分支结果相反(分支冲突)的概率:
(br1taken, br2nottaken) + (br1nottaken, br2taken) = (85% * 85%) + (15% * 15%) = 74.5% - Agree 方法–两条分支结果相反(分支冲突)的概率:
(br1agree, br2disagree) + (br1disagree, br2agree)= (85% * 15%) + (15% * 85%) = 25.5%
2)优点:
• 2条不同方向的分支可以映射到同一表项
• 偏向位不变,只改变 PHT
• gcc误预测在64k的PHT下减少8.6%, 1K的PHT误预测减少33.3%
3)应用:HP的PA-8700处理器
(15)Bi-Mode预测器:
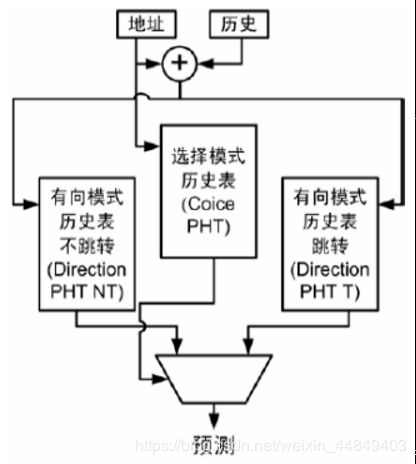
- Bi-mode 和Agree 分支预测的思想一致,不过它是把容易发生跳转和不跳转的分支放入不同的PHT。
- 它由3 部分组成,一部分用来选择PHT,另外两部分表示PHT 的方向,分别为跳转和不跳转,PHT 的方向被全局历史索引。
- 由于对预测器的选择,达到了针对每条转移的程度,因此命中率又有所提高。
(16)组合分支预测器:
- 不同的分支预测只能对某类的分支行为有效
- 不同分支预测组合起来,根据分支行为选不同分支预测器

动态转移猜测小结
- 转移的重复性和偏向性:BHT
- 转移指令的相关性问题:两层转移预测
- 分支别名干扰问题:Gshare等
- 混合预测器:不同的分支预测只能对某类的分支行为有效
不要执着于具体办法,关键是抓住应用程序的特点
常见处理器的转移预测
一些典型商品处理器的分支预测机制

Alpha 21264的分支预测器

举例:

Pentium IV的转移预测器

两个动态预测器(BTB)和静态预测混合预测:
- 静态预测:跳转方向是backward时则预测taken,反之nottaken
- BTB:记录历史信息和目标地址
- 选择:当BTB中没有该跳转指令时采用静态预测
Power4转移预测器
- 静态预测:
- 每条转移指令保留两位,一位表示是否用静态预测,若用则动态预测失效,另一位表示是否跳转 - 动态预测器由3个16K*1的表组成:
- 局部预测器由指令地址来索引;
- 全局预测器由一个11位的历史向量与地址异或来索引,历史向量记录;
- 前11组指令是否连续的信息(Power4将指令分组,1组指令为5条);
- 选择器的索引同全局预测器; - 返回地址栈Link stack:
- 遇到branch and link指令预测taken,同时将link地址压栈,由编译器对branch to link指令作上标记(hint bit),从栈中弹出地址; - 计数缓存(Count cache):
- 32项,直接相联,软件标志该指令会多次重复跳转,则将其目标地址写入计数缓存,计数缓存的每一项保存62位地址
-
MIPS R10000的转移预测器
- R10000:
• 512-entry, 2-bit BHT
• Branch stack - R12000:
• 2048-entry, 2-bit BHT
• 32-entry BTB
龙芯2号分支预测器
- 静态预测和动态预测结合的转移预测方法:
• “likely”类的转移直接预测跳转
• 其它转移指令采用动态预测方法。 - 采用Gshare结构进行条件指令的转移预测:
• BHR共9位,PHT表有4096项 - 16项BTB预测普通JR指令:
• 在译码阶段访问 - 4项RAS预测函数返回指令:
• 目标寄存器为31号寄存器的JR指令
常见处理器的分支预测(最近)

分支预测未来
- 进一步提高很难:
• 95%-98%左右
• 工业界分支预测越做越大,Alpha21464有48KB - 进一步提高很有意义:
• 预测精度提高0.5%,10000条分支指令就能减少50次流水线刷新 - 新应用及新结构需要新的预测机制:
• Power-aware分支预测
• SMT结构分支预测
• 神经网络分支预测器 - 分支预测大赛:
• 工业界支持,2年一次