python中正则表达式的应用大全
正则表达式
应用场景
处理/判断用户提供的数据
爬虫(数据清洗)
快速提取数据
创建流程
导入re模块
match方法匹配
group提取
import re
ret = re.match(正则表达式,需要处理的字符串)
ret.group()
匹配单个字符

注:
-
只取一位:
-
\d 一位数字(0-9)
-
[1-36-8] 连续数字 可断开(只有一位 等同于[123678])(并不按顺序)
-
[1-8a-zA-Z] 连续数字 及字母(大小写)
-
\w 数字字母下划线及中文等(“Unicode码”)
re.match(r"","",re.A) 不支持中文 (“ASCII码”)(等价于[a-zA-Z0-9_])
re.match(r"","",re.U) 支持中文
re.match(r"","",re.I) 支持大小写同时匹配
匹配多个字符

- {} 规定输入位数
- {1,3} 范围
{m,} 匹配前一个字符出现m到无限次
{,} 中 ,两侧不能有空格 - ? 前测紧邻数据 数据非必须输入
- .* 除换行外 任意多个字符
- re.match(r"","",re.S) .情况下 支持匹配\n
匹配开头结尾
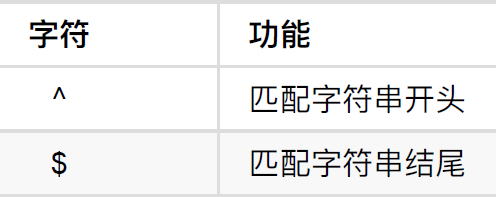
注:
- 还可在[]式内部(非开头)表示**只要不是**>,eg."[>]";当匹配到>时,^>匹配停止,且并不取>。
- $ 需匹配的字符串到$处停止
匹配分组
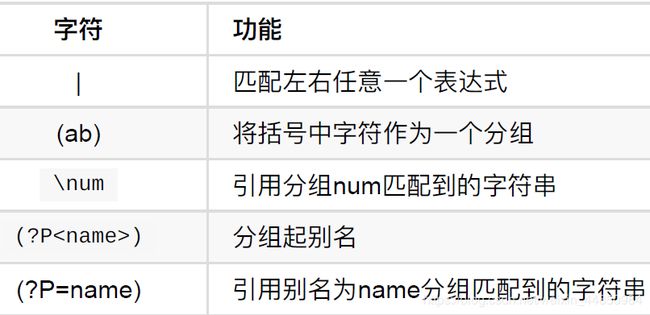
匹配分组的应用格式:
-
re.match(r"()()","").group(1,2)
-
re.match(r"()(|)","").groups(1)
-
re.match(r"(|)","").groups(1)
分组的应用:
\num:
thml_str = "yemian
"
re.match(r"<(\w*)><(\w*)>.*,thml_str").group()
'yemian
'
(?P)(?P=name):
thml_str = "yemian
"
re.match(r"<(?P\w*)><(?P\w*)>.*,thml_str").group()
'yemian
'
python的贪婪和非贪婪
python正则表达式默认贪婪,Python会尽可能多的匹配信息
非贪婪:条件成立下,匹配越小越好
? 可将python模式调整为非贪婪
+ * ? {} 后面加上?,使贪婪变成非贪婪
r的作用
Python中字符串前⾯加上 r 表示原⽣字符串,表示r""内正则表达式的\不在作为转义字符