拼多多2020学霸批数据分析师笔试 —— SQL整理(2019.7.28)
半个月过去,终于安装好Mysql,可以开始实操、解决和总结「拼多多学霸批」的SQL题了。真题还是非常珍贵的,难得和业务需求结合在一起。
加之这周,了解了「窗口函数」,比半个月前的我,又有多一点不一样的思路。
数据是自己生成的,代码是自己码的。如有错误,请评论指正,感谢!
❤️「更多完整真题」
拼多多2020学霸批数据分析师笔试题 (2019.7.28)
一、第一题
-
表ord(用户订单表)
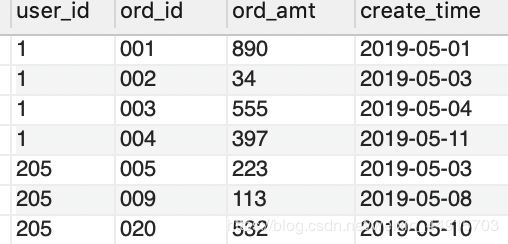
-
表act_usr(活动参与用户表)
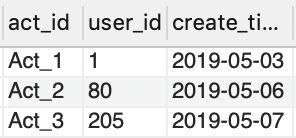
(1)创建表act_output,保存以下信息:
区分不同活动,统计每个活动对应所有用户在报名参与活动之后产生的总订单金额、总订单数(一个用户只能参加一个活动)。
CREATE TABLE act_output AS
SELECT a.act_id, SUM(o.ord_amt) AS Total_amount, COUNT(o.ord_id) AS Total_order
FROM ord AS o INNER JOIN act_usr AS a ON o.user_id = a.user_id
WHERE o.create_time >= a.create_time
GROUP BY a.act_id;
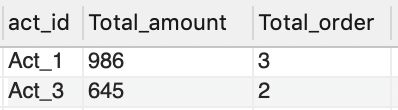
(2)加入活动开始后每天都会产生订单,计算每个活动截止当前(2019-08-12)平均每天产生的订单数,活动开始时间假设为用户最早报名时间。
SELECT a.act_id, TIMESTAMPDIFF(DAY,MIN(a.create_time),'2019-08-12') AS time_interval,
ROUND(COUNT(o.ord_id)/TIMESTAMPDIFF(DAY,MIN(a.create_time),'2019-08-12'),3) AS avg_order
FROM ord AS o INNER JOIN act_usr AS a ON o.user_id = a.user_id
WHERE o.create_time >= a.create_time
GROUP BY a.act_id;

二、第二题
某网络用户访问操作流水表 tracking_log,
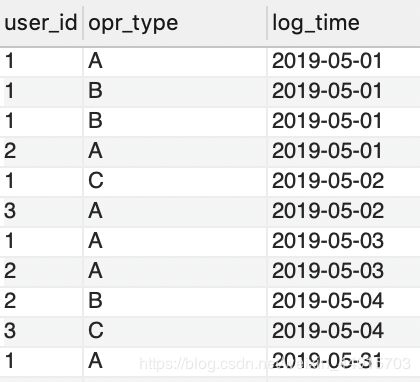
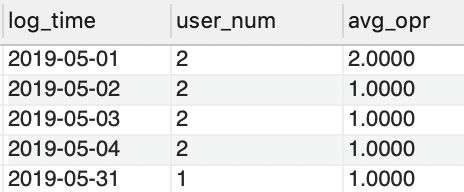
(1)计算网站每天的访客数以及他们的平均操作次数;
SELECT log_time, COUNT(DISTINCT user_id) AS user_num,
COUNT(opr_type)/COUNT(DISTINCT user_id) AS avg_opr
FROM tracking_log
GROUP BY log_time;
(2)统计每天符合A操作后B操作的操作模式的用户数,即要求AB相邻。
- 「思路」
i)按照天分组;
ii)在每一天,判断同一个user的操作是否连续。也就是说,在相邻行比较的时候,不仅要判断是否AB相连,还要保证是对于同一个user。比如,user2 操作A,user3 操作B,哪怕相连,也不满足。
iii)因为要判断相邻行,所以用row_numbers在每一组内计算行数。
step1:
-- 组内统计行数
CREATE VIEW view1 AS
(SELECT user_id, log_time, opr_type,
row_number() over (PARTITION BY log_time ORDER BY user_id) AS flag FROM tracking_log
);
step 2:
SELECT t1.log_time, COUNT(DISTINCT t1.user_id) AS count
FROM view1 AS t1 INNER JOIN view1 AS t2
ON t1.user_id = t2.user_id AND t1.log_time = t2.log_time
WHERE t1.opr_type = 'A' AND t2.opr_type = 'B' AND t1.flag +1 = t2.flag
GROUP BY t1.log_time;
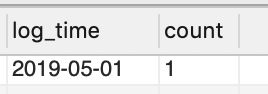
其实如果想看,筛选前的中间过程:
SELECT *
FROM view1 AS t1 INNER JOIN view1 AS t2
ON t1.user_id = t2.user_id AND t1.log_time = t2.log_time
WHERE t1.opr_type = 'A' AND t2.opr_type = 'B' AND t1.flag +1 = t2.flag;

也就是说,只有这一个连续操作是符合条件的。
- 完整代码
CREATE VIEW view1 AS
(SELECT user_id, log_time, opr_type,
row_number() over (PARTITION BY log_time ORDER BY user_id) AS flag FROM tracking_log
);
SELECT t1.log_time, COUNT(DISTINCT t1.user_id) AS count
FROM view1 AS t1 INNER JOIN view1 AS t2
ON t1.user_id = t2.user_id AND t1.log_time = t2.log_time
WHERE t1.opr_type = 'A' AND t2.opr_type = 'B' AND t1.flag +1 = t2.flag
GROUP BY t1.log_time;
三、第三题
根据第2题的用户访问操作流水表 tracking_log,
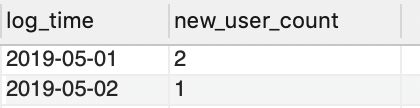
(1)计算网络每日新增访客表;
- 如果只是计算,每日新增访客数量
SELECT t4.log_time, COUNT(DISTINCT t4.user_id) AS new_user_count
FROM tracking_log AS t4
WHERE t4.user_id NOT IN
(SELECT t3.user_id FROM tracking_log AS t3
WHERE t3.log_time < t4.log_time)
GROUP BY t4.log_time
ORDER BY t4.log_time;
⚠️ 注意 : GROUP BY和DISTINCT 都有起到去重作用。因为一个新user出现的那一天,可能有多个操作。比如如下的原始数据中,对于2019-05-01,user_id = 1 是新增访客,前三条记录都是满足条件的,都会被选出来,因为只用user_id和log_time来判断,他们都是重复记录。
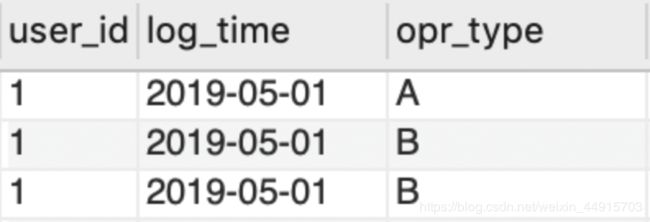
- 如果要列出新增访客的具体名字。
「思路」一致,
i)「在这次访问之前没有访问过该网站」用NOT IN,同上种情况。
ii)用row_numbers()对整行相同的重复记录,去重。
CREATE VIEW view2 AS
SELECT t4.log_time, t4.user_id AS new_user,
row_number() OVER (PARTITION BY t4.log_time, t4.user_id) AS rn
FROM tracking_log AS t4
WHERE t4.user_id NOT IN
(SELECT t3.user_id FROM tracking_log AS t3
WHERE t3.log_time < t4.log_time) ;
SELECT log_time, new_user FROM view2 WHERE rn = 1;
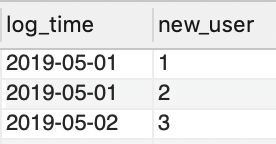
下图是中间过程,view2,未去重之前。
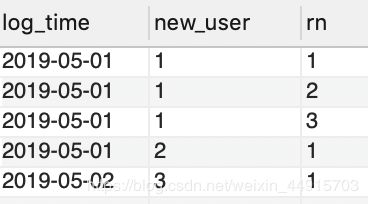
(2)新增访客的第2日、第30日回访比例。
- 「思路」
i)增加一列first_log,此列存着每个用户最早登录时间;用窗口函数实现;去重,用户同一天多次登录仅算一次访客量(存疑,待确认)。
ii)增加一列by_day = log_time - first_log,计算留存时间;
iii) 统计各留存天数的总人数。i.e. day_0的访客量就是新增访客量,day_2的访客量就是两日留存的量。
iv)计算各留存天数的留存率。
留存率的概念是,
- 如果用户在5月1日第一次使用我们的产品。
- 如果5月2日他还使用了,那么5月1日的“一日留存”加一.
- 同理5月3日他又使用了,5月1日的“两日留存”加一.
- 5月1日的“一日留存率”=5月1日“一日留存” / 5月1日新增用户数量.
- 代码实现
step1:
-- 增加一列first_log
CREATE VIEW view3 AS
SELECT user_id, log_time,
MIN(log_time) OVER (PARTITION BY user_id ORDER BY log_time) AS first_log,
row_number() OVER (PARTITION BY user_id, log_time) AS t
FROM tracking_log;
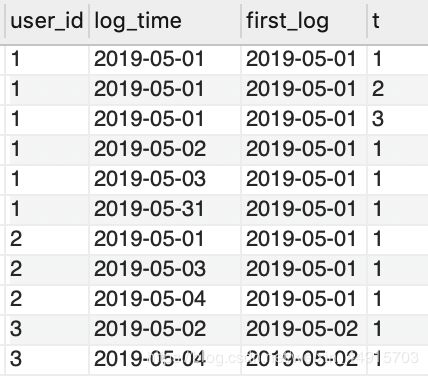
step2: 去重,并增加一列by_day
CREATE VIEW view4 AS
SELECT *, TIMESTAMPDIFF(DAY, first_log, log_time) AS by_day
FROM view3
WHERE t=1;
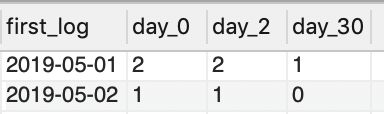
step 3: 统计新增访客量,2日留存,30日留存
CREATE VIEW view5 AS
SELECT first_log,
sum(case when by_day = 0 then 1 else 0 end) AS day_0,
sum(case when by_day = 2 then 1 else 0 end) AS day_2,
sum(case when by_day = 30 then 1 else 0 end) AS day_30
FROM view4
GROUP BY first_log;
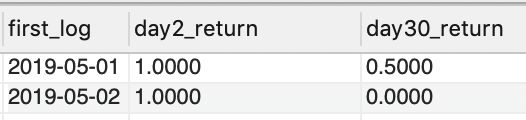
step4 : 计算留存率(回头访客率)
SELECT first_log, day_2/day_0 AS day2_return,
day_30/day_0 AS day30_return FROM view5;
一点疑问
其实我想问,新增访客定义如何? 同一个用户一天内访问并操作了好几次,是按照user_id还是操作次数来统计?
第二问和第三问里,我都去重了。但参考的博客中,没有去重。
求指点。
如若有其他错误,也请一并指出,谢谢~