python爬虫——用selenium爬取淘宝商品信息
python爬虫——用selenium爬取淘宝商品信息
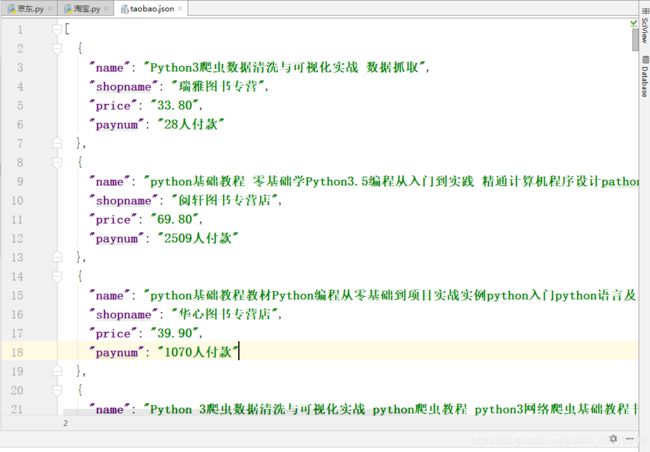
1.附上效果图

2.淘宝网址https://www.taobao.com/
3.先写好头部
browser = webdriver.Chrome()
wait = WebDriverWait(browser,20)#设置等待时间为20秒
url ='https://www.taobao.com/'
keyword = 'python爬虫'#关键词
data_list = []#设置全局变量来存储数据
4.先找到搜索框并用selenium模拟点击(发现需要登录,我直接扫码登录,没有写模拟登录的过程)

def search():
try:
browser.get(url)#获取网页
input = wait.until(EC.presence_of_element_located((
By.XPATH,'//*[@id="q"]'
)))#等到输入框加载出来
button = wait.until(EC.element_to_be_clickable((
By.XPATH,'//*[@id="J_TSearchForm"]/div[1]/button'
)))#等到搜索框加载出来
input.send_keys(keyword)#输入关键词
button.click()#模拟鼠标点击
total = wait.until(EC.presence_of_element_located((
By.XPATH,'//*[@id="mainsrp-pager"]/div/div/div/div[1]'
))).text#等到python爬虫页面的总页数加载出来
total = re.sub(r',|,','',total)#发现总页数有逗号
#数据清洗,将共100页后面的逗号去掉,淘宝里的是大写的逗号
print(total)
totalnum = int(re.compile('(\d+)').search(total).group(1))
# 只取出100这个数字
print("第1页:")
get_data()#获取数据(下面才写到)
return totalnum
except TimeoutError:
search()

5.获取商品信息,在这里我发现前几个会有淘宝的掌柜热卖的广告,属性和其他的不一样,我就用item从上往下数的第几个的方法找到他们

def get_data():
try:
lis = browser.find_elements_by_xpath('//div[@class = "items"]/div[@data-category="auctions"]')
for i in range(len(lis)):
name = browser.find_elements_by_xpath('.//div[@class="pic"]/a[@class="pic-link J_ClickStat J_ItemPicA"]/img')[i].get_attribute('alt')
#获取书名,我是从图片那里的属性获取的书名,比较方便
shopname = browser.find_elements_by_xpath('.//div[@class="shop"]/a[@class="shopname J_MouseEneterLeave J_ShopInfo"]/span[2]')[i].text
#获取店铺名
price = browser.find_elements_by_xpath('.//div[@class="price g_price g_price-highlight"]/strong')[i].text
#获取价格
paynum = browser.find_elements_by_xpath('.//div[@class="deal-cnt"]')[i].text
#获取付款人数
data_dict={}#定义一个字典存储数据
data_dict["name"] = name
data_dict["shopname"] = shopname
data_dict["price"] = price
data_dict["paynum"] = paynum
print(data_dict)#输出这个字典
data_list.append(data_dict)#将数据存入全局变量中
except TimeoutError:
get_data()


6.翻页方法,对比1,2,3页网址,发现只有q和s的属性有用,q是搜索,s是商品数,只需要填写这2个属性,用修改s的属性的方式翻页

def next_page():
totalnum = search()#获取总页数的值,并且调用search获取第一页数据
num = 1#初始为1,因为我第一页已经获取过数据了
while num !=3:#这里我偷懒只爬取了3页
# while num != totalnum - 1:#首先进来的是第1页,共100页,所以只需要翻页99次
print("第%s页:" %str(num+1) )
browser.get('https://s.taobao.com/search?q=python爬虫&s={}'.format(44 * num))
#用修改s属性的方式翻页
browser.implicitly_wait(10)
#等待10秒
get_data()#获取数据
time.sleep(3)
num +=1#自增
7.存储方法
def save():
content = json.dumps(data_list, ensure_ascii=False, indent=2)
# 把全局变量转化为json数据
with open("taobao.json", "a+", encoding="utf-8") as f:
f.write(content)
print("json文件写入成功")
with open('taobao.csv', 'w', encoding='utf-8', newline='') as f:
# 表头
title = data_list[0].keys()
# 声明writer
writer = csv.DictWriter(f, title)
# 写入表头
writer.writeheader()
# 批量写入数据
writer.writerows(data_list)
print('csv文件写入完成')
8.调用函数
def main():
next_page()
save()
if __name__ == '__main__':
main()
9.最后附上完整代码,因为爬取的是淘宝,我也不敢多爬
import time
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
import re
import json
import csv
browser = webdriver.Chrome()
wait = WebDriverWait(browser,20)#设置等待时间为20秒
url ='https://www.taobao.com/'
keyword = 'python爬虫'#关键词
data_list = []#设置全局变量来存储数据
def search():
try:
browser.get(url)#获取网页
input = wait.until(EC.presence_of_element_located((
By.XPATH,'//*[@id="q"]'
)))#等到输入框加载出来
button = wait.until(EC.element_to_be_clickable((
By.XPATH,'//*[@id="J_TSearchForm"]/div[1]/button'
)))#等到搜索框加载出来
input.send_keys(keyword)#输入关键词
button.click()#模拟鼠标点击
total = wait.until(EC.presence_of_element_located((
By.XPATH,'//*[@id="mainsrp-pager"]/div/div/div/div[1]'
))).text#等到python爬虫页面的总页数加载出来
total = re.sub(r',|,','',total)#发现总页数有逗号
#数据清洗,将共100页后面的逗号去掉,淘宝里的是大写的逗号
print(total)
totalnum = int(re.compile('(\d+)').search(total).group(1))
# 只取出100这个数字
print("第1页:")
get_data()#获取数据(下面才写到)
return totalnum
except TimeoutError:
search()
def get_data():
try:
lis = browser.find_elements_by_xpath('//div[@class = "items"]/div[@data-category="auctions"]')
for i in range(len(lis)):
name = browser.find_elements_by_xpath('.//div[@class="pic"]/a[@class="pic-link J_ClickStat J_ItemPicA"]/img')[i].get_attribute('alt')
#获取书名,我是从图片那里的属性获取的书名,比较方便
shopname = browser.find_elements_by_xpath('.//div[@class="shop"]/a[@class="shopname J_MouseEneterLeave J_ShopInfo"]/span[2]')[i].text
#获取店铺名
price = browser.find_elements_by_xpath('.//div[@class="price g_price g_price-highlight"]/strong')[i].text
#获取价格
paynum = browser.find_elements_by_xpath('.//div[@class="deal-cnt"]')[i].text
#获取付款人数
data_dict={}#定义一个字典存储数据
data_dict["name"] = name
data_dict["shopname"] = shopname
data_dict["price"] = price
data_dict["paynum"] = paynum
print(data_dict)#输出这个字典
data_list.append(data_dict)#将数据存入全局变量中
except TimeoutError:
get_data()
def next_page():
totalnum = search()#获取总页数的值,并且调用search获取第一页数据
num = 1#初始为1,因为我第一页已经获取过数据了
while num !=3:#这里我偷懒只爬取了3页
# while num != totalnum - 1:#首先进来的是第1页,共100页,所以只需要翻页99次
print("第%s页:" %str(num+1) )
browser.get('https://s.taobao.com/search?q=python爬虫&s={}'.format(44 * num))
#用修改s属性的方式翻页
browser.implicitly_wait(10)
#等待10秒
get_data()#获取数据
time.sleep(3)
num +=1#自增
def save():
content = json.dumps(data_list, ensure_ascii=False, indent=2)
# 把全局变量转化为json数据
with open("taobao.json", "a+", encoding="utf-8") as f:
f.write(content)
print("json文件写入成功")
with open('taobao.csv', 'w', encoding='utf-8', newline='') as f:
# 表头
title = data_list[0].keys()
# 声明writer
writer = csv.DictWriter(f, title)
# 写入表头
writer.writeheader()
# 批量写入数据
writer.writerows(data_list)
print('csv文件写入完成')
def main():
next_page()
save()
if __name__ == '__main__':
main()