Android--网络请求篇
一、 Retrofit网络请求框架
//添加依赖
compile 'com.squareup.okhttp3:okhttp:3.1.2'// Okhttp库
compile 'com.squareup.retrofit2:retrofit:2.0.2'// Retrofit库
compile 'com.squareup.retrofit2:converter-gson:2.0.2'//GSON解析器
//添加网络权限
<uses-permission android:name="android.permission.INTERNET"/>
1.GET请求
- 创建接收服务器返回数据的类
public class News {
// 根据返回数据的格式和数据解析方式(Json、XML等)定义
}
- 创建用于描述网络请求的接口
public interface APi {
// @GET注解的作用:采用Get方法发送网络请求
// getNews(...) = 接收网络请求数据的方法
// 其中返回类型为Call,News是接收数据的类(即上面定义的News类)
// 如果想直接获得Responsebody中的内容,可以定义网络请求返回值为Call getNews();
}
Retrofit将Http请求抽象成Java接口,并在接口里面采用注解来配置网络请求参数。用动态代理将该接口的注解“翻译”成一个Http请求,最后再执行 Http请求(接口中的每个方法的参数都需要使用注解标注,否则会报错)
APi接口中的最后一个注释,Responsebody是Retrofit网络请求回来的原始数据类,没经过Gson转换什么的,如果想看接口返回的json字符串,把Call的泛型定义为ResponseBody:Call
GET注解:
说白了就是我们的GET请求方式。这里涉及到Retrofit创建的一些东西,Retrofit在创建的时候,有一行代码:baseUrl(“http://apis.baidu.com/txapi/”),这个http://apis.baidu.com/txapi/是我们要访问的接口的BaseUrl,
而我们现在用GET注解的字符串 "word/word"会追加到BaseUrl中变为:http://apis.baidu.com/txapi/world/world
@GET():
在我们日常开发中,BaseUrl具体是啥由后端接口童鞋给出,之后接口童鞋们会出各种各种的后缀(比如上面的 “word/word”)组成各种各行的接口用来供移动端数据调用,实现各种各样的功能
@Query:
@Query(“num”)String num, @Query(“page”)String page就是键值对,Retrofit会把这两个字段一块拼接到接口中,追加到http://apis.baidu.com/txapi/world/world后面,变为http://apis.baidu.com/txapi/world/world?num=10&page=1,这样,这个带着响应头的接口就是我们最终请求网络的完整接口。GET请求方式,如果携带的参数不是以?num=10&page=1拼接到接口中(就是不带?分隔符),那就不用Query注解了,而是使用Path注解。还有一点哈,有的url既有“{}”占位符,又有“?”后面的键值对(key-value),那Retrofit既得使用@Query注解又得使用@Path注解,也就是说,两者可以同时使用。
@Headers:
@Headers(“apikey:81bf9da930c7f9825a3c3383f1d8d766”)这个很好理解,这个接口需要添加的header:apikey:81bf9da930c7f9825a3c3383f1d8d766。@Headers就是把接口的header注解进去。
- 创建Retrofit对象
Retrofit retrofit = new Retrofit.Builder()
//设置数据解析器
.addConverterFactory(GsonConverterFactory.create())
//设置网络请求的Url地址
.baseUrl("http://apis.baidu.com/txapi/")
.build();
// 创建网络请求接口的实例
mApi = retrofit.create(APi.class);
- 异步发起网络请求:
Call<News> news = mApi.getNews("1", "10");//对发送请求进行封装
//发送网络请求(异步)
@Override
public void onResponse(Call<News> call, Response<News> response) {
news.enqueue(new Callback<News>() {
//请求成功时回调//请求处理,输出结果-response.body().show();
}
@Override
public void onFailure(Call<News> call, Throwable t) {
//请求失败时候的回调
}
});
- 同步发起网络请求
//对发送请求进行封装
Call<News> news = mApi.getNews("1", "10");
//发送网络请求(同步)
Response<Reception> response = news.execute();
2.POST请求
- 创建用于描述网络请求的接口
public interface IServiceApi {
@POST("/claims/preclaims")
Observable<PublicResponseEntity<PreclaimsResponseEntity>> postClaimPreclaims(@Header("Authorization") String authorization, @QueryMap HashMap<String, String> deviceInfo, @Body RequestBody body);
}
方法中的第一个参数:在代码中动态的添加了一个header。
方法中的第二个参数:通过@QueryMap往接口中注解很多个参数,通过@QueryMap方式将所有的参数集成在一个Map统一传递。
第三个参数:通过@Body注解了一个RequestBody,大体意思是:使用这个注解可以把参数放到请求体中,适用于 POST/PUT请求,一脸懵逼呀,只知道它适用于对于POST/PUT。
- 创建Retrofit对象
Retrofit retrofit = new Retrofit.Builder()
.baseUrl(URL.SERVICE_URL)
.addCallAdapterFactory(RxJava2CallAdapterFactory.create())
.addConverterFactory(GsonConverterFactory.create())
.client(okHttpClient)
.build();
// 创建网络请求接口的实例
IServiceApi mApi = retrofit.create(IServiceApi .class); //对发送请求进行封装
Observable<PublicResponseEntity<PreclaimsResponseEntity>> news = mApi.postClaimPreclaims("你的Header信息", "你要传到接口中的HashMap参数", "你的实体类");
//发送网络请求(异步)
news.enqueue(new Callback<News>() {
@Override
public void onResponse(Call<News> call, Response<News> response) {
//请求成功时回调//请求处理,输出结果-response.body().show();
}
@Override
public void onFailure(Call<News> call, Throwable t) {
//请求失败时候的回调
}
});
OKHttp的取消网络请求
public synchronized void cancelAll() {
//取消所有等待执行的异步请求
for (AsyncCall call : readyAsyncCalls) {
call.get().cancel();
}
//取消所有的同步请求
for (AsyncCall call : runningAsyncCalls) {
call.get().cancel();
}
//取消正在执行的异步请求
for (RealCall call : runningSyncCalls) {
call.cancel();
}
}
二、 RxJava详解
//导入依赖
compile 'io.reactivex:rxjava:1.0.14'
compile 'io.reactivex:rxandroid:1.0.1'
RxJava 本质可以压缩为异步这一个词。说到根上,它就是一个实现异步操作的库。观察者模式。RxJava 好在哪。一个词:简洁。
RxJava 有四个基本概念:
Observable (被观察者) 【相当于View】
Observer (观察者) 【相当于OnClickListener】
subscribe (订阅)、事件。 【相当于setOnClickListener()】
Observable和Observer通过subscribe()方法实现订阅关系,而Observable可以在需要的时候发出事件来通知Observer。
RxJava 的事件回调方法除了普通事件onNext(),还定义了两个特殊的事件:
onCompleted():不再有新onNext()发出时,需触发onCompleted()方法作为标志。
onError(): 事件队列异常。
两个事件互斥。
1.基本实现
- 创建 Observer
Observer 即观察者,它决定事件触发的时候将有怎样的行为。 RxJava 中的 Observer 接口的实现方式:
Observer<String> observer = new Observer<String>() {
@Override
public void onNext(String s) {
Log.d(tag, "Item: " + s);
}
@Override
public void onCompleted() {
Log.d(tag, "Completed!");
}
@Override
public void onError(Throwable e) {
Log.d(tag, "Error!");
}
};
除了Observer接口之外,RxJava 还内置了一个实现了Observer的抽象类:Subscriber。Subscriber对Observer接口进行了一些扩展,但他们的基本使用方式是完全一样的:
Subscriber<String> subscriber = new Subscriber<String>() {
@Override
public void onNext(String s) {
Log.d(tag, "Item: " + s);
}
@Override
public void onCompleted() {
Log.d(tag, "Completed!");
}
@Override
public void onError(Throwable e) {
Log.d(tag, "Error!");
}
};
不仅基本使用方式一样,实质上,在 RxJava 的 subscribe 过程中,Observer也总是会先被转换成一个Subscriber再使用。所以如果你只想使用基本功能,选择Observer和Subscriber是完全一样的。它们的区别对于使用者来说主要有两点:
·onStart(): 这是Subscriber增加的方法。它会在 subscribe 刚开始,而事件还未发送之前被调用,可以用于做一些准备工作,例如数据的清零或重置。这是一个可选方法,默认情况下它的实现为空。需要注意的是,如果对准备工作的线程有要求(例如弹出一个显示进度的对话框,这必须在主线程执行),onStart()就不适用了,因为它总是在 subscribe 所发生的线程被调用,而不能指定线程。要在指定的线程来做准备工作,可以使用doOnSubscribe()方法。
·unsubscribe(): 这是Subscriber所实现的另一个接口Subscription的方法,用于取消订阅。在这个方法被调用后,Subscriber将不再接收事件。一般在这个方法调用前,可以使用isUnsubscribed()先判断一下状态。unsubscribe()这个方法很重要,因为在subscribe()后,Observable会持有Subscriber的引用,这个引用如果不能及时被释放,将有内存泄露的风险。所以最好保持一个原则:要在不再使用的时候尽快在合适的地方(例如onPause() onStop()等方法中)调用unsubscribe()来解除引用关系,以避免内存泄露的发生。
- 创建 Observable
Observable 即被观察者,它决定什么时候触发事件以及触发怎样的事件。 RxJava 使用 create() 方法来创建一个 Observable:
Observable observable = Observable.create(new Observable.OnSubscribe<String>() {
@Override
public void call(Subscriber<? super String> subscriber) {
subscriber.onNext("Hello");
subscriber.onNext("Hi");
subscriber.onNext("Aloha");
subscriber.onCompleted();
}
});
这里传入了一个OnSubscribe对象作为参数。OnSubscribe会被存储在返回的Observable对象中,当Observable被订阅的时候,OnSubscribe的call()方法会自动被调用,事件序列就会依照设定依次触发。这样,由被观察者调用了观察者的回调方法,就实现了由被观察者向观察者的事件传递,即观察者模式。
create()方法是 RxJava 最基本的创造事件序列的方法。基于这个方法, RxJava 还提供了一些方法用来快捷创建事件队列,例如:
just(T…): 将传入的参数依次发送出来。
Observable observable = Observable.just("Hello", "Hi", "Aloha");
// 将会依次调用:
// onNext("Hello");
// onNext("Hi");
// onNext("Aloha");
// onCompleted();
from(T[])/from(Iterable): 将传入的数组或Iterable拆分成具体对象后,依次发送出来。
String[] words = {"Hello", "Hi", "Aloha"};
Observable observable = Observable.from(words);
// 将会依次调用:
// onNext("Hello");
// onNext("Hi");
// onNext("Aloha");
// onCompleted();
just(T…)的例子和from(T[])的例子,都和之前的create(OnSubscribe)的例子是等价的。
- Subscribe (订阅)
创建了Observable和Observer之后,再用subscribe()方法将它们联结起来,整条链子就可以工作了。代码形式很简单:
observable.subscribe(observer);
// 或者:
observable.subscribe(subscriber);
Observable.subscribe(Subscriber) 的内部实现是这样的(仅核心代码):
// 注意:这不是 subscribe() 的源码,而是将源码中与性能、兼容性、扩展性有关的代码剔除后的核心代码。
// 如果需要看源码,可以去 RxJava 的 GitHub 仓库下载。
public Subscription subscribe(Subscriber subscriber) {
subscriber.onStart();
onSubscribe.call(subscriber);
return subscriber;
}
可以看到,subscriber()做了3件事:
1.调用Subscriber.onStart()。
2.调用Observable中的OnSubscribe.call(Subscriber)。在这里,事件发送的逻辑开始运行。从这也可以看出,在 RxJava 中,Observable不是在创建的时候就立即开始发送事件,而是在它被订阅的时候,即当subscribe()方法执行的时候。
3.将传入的Subscriber作为Subscription返回。是为了方便unsubscribe()
- 除了subscribe(Observer)和subscribe(Subscriber),subscribe()还支持不完整定义的回调,RxJava 会自动根据定义创建出Subscriber。
形式如下:
Action1<String> onNextAction = new Action1<String>() {
// onNext()
@Override
public void call(String s) {
Log.d(tag, s);
}
};
Action1<Throwable> onErrorAction = new Action1<Throwable>() {
// onError()
@Override
public void call(Throwable throwable) {
// Error handling
}
};
Action0 onCompletedAction = new Action0() {
// onCompleted()
@Override
public void call() {
Log.d(tag, "completed");
}
};
// 自动创建 Subscriber ,并使用 onNextAction 来定义 onNext()
observable.subscribe(onNextAction);
// 自动创建 Subscriber ,并使用 onNextAction 和 onErrorAction 来定义 onNext() 和 onError()
observable.subscribe(onNextAction, onErrorAction);
// 自动创建 Subscriber ,并使用 onNextAction、 onErrorAction 和 onCompletedAction 来定义 onNext()、 onError() 和 onCompleted()
observable.subscribe(onNextAction, onErrorAction, onCompletedAction);
简单解释一下这段代码中出现的Action1和Action0。Action0 是 RxJava 的一个接口,它只有一个方法call(),这个方法是无参无返回值的;由于onCompleted()方法也是无参无返回值的,因此Action0可以被当成一个包装对象,将onCompleted()的内容打包起来将自己作为一个参数传入subscribe()以实现不完整定义的回调。这样其实也可以看做将onCompleted()方法作为参数传进了subscribe(),相当于其他某些语言中的『闭包』。Action1也是一个接口,它同样只有一个方法call(T param),这个方法也无返回值,但有一个参数;与Action0同理,由于onNext(T obj)和onError(Throwable error)也是单参数无返回值的,因此Action1可以将onNext(obj)和onError(error)打包起来传入subscribe()以实现不完整定义的回调。事实上,虽然Action0和Action1在 API 中使用最广泛,但 RxJava 是提供了多个ActionX形式的接口 (例如Action2,Action3) 的,它们可以被用以包装不同的无返回值的方法。
- 场景实例
//将字符串数组names中的所有字符串依次打印出来:
String[] names = ...;
Observable.from(names)
.subscribe(new Action1<String>() {
@Override
public void call(String name) {
Log.d(tag, name);
}
});
//由 id 取得图片并显示。由指定的一个drawable文件 iddrawableRes取得图片,并显示在ImageView中,并在出现异常的时候打印 Toast 报错:
int drawableRes = ...;
ImageView imageView = ...;
Observable.create(new OnSubscribe<Drawable>() {
@Override
public void call(Subscriber<? super Drawable> subscriber) {
Drawable drawable = getTheme().getDrawable(drawableRes));
subscriber.onNext(drawable);
subscriber.onCompleted();
}
}).subscribe(new Observer<Drawable>() {
@Override
public void onNext(Drawable drawable) {
imageView.setImageDrawable(drawable);
}
@Override
public void onCompleted() {
}
@Override
public void onError(Throwable e) {
Toast.makeText(activity, "Error!", Toast.LENGTH_SHORT).show();
}
});
2.变换
- API
RxJava提供了对事件序列进行变换的支持,这是它的核心功能之一。
所谓变换,就是将事件序列中的对象或整个序列进行加工处理,转换成不同的事件或事件序列。
Observable.just("images/logo.png") // 输入类型 String
.map(new Func1<String, Bitmap>() {
@Override
public Bitmap call(String filePath) { // 参数类型 String
return getBitmapFromPath(filePath); // 返回类型 Bitmap
}
})
.subscribe(new Action1<Bitmap>() {
@Override
public void call(Bitmap bitmap) { // 参数类型 Bitmap
showBitmap(bitmap);
}
});
这里出现了一个叫做Func1的类。它和Action1非常相似,也是 RxJava 的一个接口,用于包装含有一个参数的方法。Func1和Action的区别在于,Func1包装的是有返回值的方法。另外,和ActionX一样,FuncX也有多个,用于不同参数个数的方法。FuncX和ActionX的区别在FuncX包装的是有返回值的方法。
可以看到,map()方法将参数中的String对象转换成一个Bitmap对象后返回,而在经过map()方法后,事件的参数类型也由String转为了Bitmap。这种直接变换对象并返回的,是最常见的也最容易理解的变换。不过 RxJava 的变换远不止这样,它不仅可以针对事件对象,还可以针对整个事件队列,这使得 RxJava 变得非常灵活。
- 几个常用的变换:
·map(): 事件对象的直接变换,具体功能上面已经介绍过。RxJava 最常用的变换。
·flatMap(): 这是一个很有用但非常难理解的变换。首先假设这么一种需求:现在需要打印出一组数据结构“学生”的名字。实现方式很简单:
Student[] students = ...;
Subscriber<String> subscriber = new Subscriber<String>() {
@Override
public void onNext(String name) {
Log.d(tag, name);
}
...
};
Observable.from(students)
.map(new Func1<Student, String>() {
@Override
public String call(Student student) {
return student.getName();
}
})
.subscribe(subscriber);
很简单。那么再假设:如果要打印出每个学生所需要修的所有课程的名称呢?(需求的区别在于,每个学生只有一个名字,但却有多个课程。)首先可以这样实现:
Student[] students = ...;
Subscriber<Student> subscriber = new Subscriber<Student>() {
@Override
public void onNext(Student student) {
List<Course> courses = student.getCourses();
for (int i = 0; i < courses.size(); i++) {
Course course = courses.get(i);
Log.d(tag, course.getName());
}
}
...
};
Observable.from(students)
.subscribe(subscriber);
依然很简单。那么如果我不想在Subscriber中使用 for 循环,而是希望Subscriber中直接传入单个的Course对象呢(这对于代码复用很重要)?
用map()显然是不行的,因为map()是一对一的转化,而我现在的要求是一对多的转化。那怎么才能把一个 Student 转化成多个 Course 呢?
这个时候,就需要用flatMap()了:
Student[] students = ...;
Subscriber<Course> subscriber = new Subscriber<Course>() {
@Override
public void onNext(Course course) {
Log.d(tag, course.getName());
}
...
};
Observable.from(students)
.flatMap(new Func1<Student, Observable<Course>>() {
@Override
public Observable<Course> call(Student student) {
return Observable.from(student.getCourses());
}
})
.subscribe(subscriber);
从上面的代码可以看出,flatMap()和map()有一个相同点:它也是把传入的参数转化之后返回另一个对象。和map()不同的是,flatMap()中返回的是个Observable对象,并且这个Observable对象并不是被直接发送到了Subscriber的回调方法中。
flatMap()的原理是这样的:1. 使用传入的事件对象创建一个Observable对象;2.激活这个Observable,开始发送事件;3. 每一个创建出来的Observable发送的事件,都被汇入同一个Observable,而这个Observable负责将这些事件统一交给Subscriber的回调方法。这三个步骤,把事件拆成了两级,通过一组新创建的Observable将初始的对象『铺平』之后通过统一路径分发了下去。而这个『铺平』就是flatMap()所谓的 flat。
扩展:由于可以在嵌套的 Observable 中添加异步代码,flatMap() 也常用于嵌套的异步操作,例如嵌套的网络请求。
示例代码(Retrofit + RxJava):
networkClient.token() // 返回 Observable,在订阅时请求 token,并在响应后发送 token
.flatMap(new Func1<String, Observable<Messages>>() {
@Override
public Observable<Messages> call(String token) {
// 返回 Observable,在订阅时请求消息列表,并在响应后发送请求到的消息列表
return networkClient.messages();
}
})
.subscribe(new Action1<Messages>() {
@Override
public void call(Messages messages) {
// 处理显示消息列表
showMessages(messages);
}
});
传统的嵌套请求需要使用嵌套的 Callback 来实现。而通过 flatMap() ,可以把嵌套的请求写在一条链中,从而保持程序逻辑的清晰。
·throttleFirst(): 在每次事件触发后的一定时间间隔内丢弃新的事件。
常用作去抖动过滤。
- 变换的原理lift()
变换虽然功能各有不同,但实质上都是针对事件序列的处理和再发送。而在 RxJava 的内部,它们是基于同一个基础的变换方法:lift(Operator)。
首先看一下lift()的内部实现(仅核心代码):
// 注意:这不是 lift() 的源码,而是将源码中与性能、兼容性、扩展性有关的代码剔除后的核心代码。
// 如果需要看源码,可以去 RxJava 的 GitHub 仓库下载。
public <R> Observable<R> lift(Operator<? extends R, ? super T> operator) {
return Observable.create(new OnSubscribe<R>() {
@Override
public void call(Subscriber subscriber) {
Subscriber newSubscriber = operator.call(subscriber);
newSubscriber.onStart();
onSubscribe.call(newSubscriber);
}
});
}
它生成了一个新的Observable并返回,而且创建新Observable所用的参数OnSubscribe的回调方法call()中的实现竟然看起来和前面讲过的Observable.subscribe()一样!然而不一样的地方关键就在于第二行onSubscribe.call(subscriber)中的onSubscribe所指代的对象不同。
·subscribe()中这句话onSubscribe指的Observable中的onSubscribe对象,这个没有问题,但是lift()之后的情况就复杂了点。
• 当含有lift()时:
1.lift()创建了一个Observable后,加上之前的原始Observable,已经有两个Observable了;
2.而同样地,新Observable里的新OnSubscribe加上之前的原始Observable中的原始OnSubscribe,也就有了两个OnSubscribe;
3.当用户调用经过lift()后的Observable的subscribe()的时候,使用的是lift()所返回的新的Observable,于是它所触发的onSubscribe.call(subscriber),也是用的新Observable中的新OnSubscribe,即在lift()中生成的那个OnSubscribe;
4.而这个新OnSubscribe的call()方法中的onSubscribe,就是指的原始Observable中的原始OnSubscribe,在这个call()方法里,新OnSubscribe利用operator.call(subscriber)生成了一个新的Subscriber(Operator就是在这里,通过自己的call()方法将新Subscriber和原始Subscriber进行关联,并插入自己的『变换』代码以实现变换),然后利用这个新Subscriber向原始Observable进行订阅。
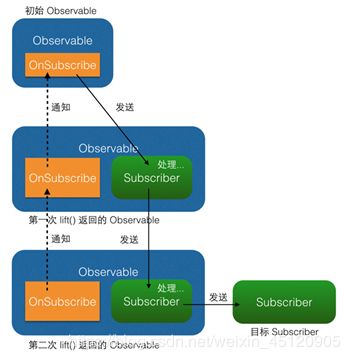
这样就实现了lift()过程,有点像一种代理机制,通过事件拦截和处理实现事件序列的变换。
精简掉细节的话,也可以这么说:在Observable执行了lift(Operator)方法之后,会返回一个新的Observable,这个新的Observable会像一个代理一样,负责接收原始的Observable发出的事件,并在处理后发送给Subscriber。

两次和多次的lift()同理,如下图:
举一个具体的Operator的实现。下面这是一个将事件中的Integer对象转换成String的例子,仅供参考:
observable.lift(new Observable.Operator<String, Integer>() {
@Override
public Subscriber<? super Integer> call(final Subscriber<? super String> subscriber) {
// 将事件序列中的 Integer 对象转换为 String 对象
return new Subscriber<Integer>() {
@Override
public void onNext(Integer integer) {
subscriber.onNext("" + integer);
}
@Override
public void onCompleted() {
subscriber.onCompleted();
}
@Override
public void onError(Throwable e) {
subscriber.onError(e);
}
};
}
});
讲述lift()的原理只是为了让你更好地了解 RxJava ,从而可以更好地使用它。然而不管你是否理解了lift()的原理,RxJava 都不建议开发者自定义Operator来直接使用lift(),而是建议尽量使用已有的lift()包装方法(如map()flatMap()等)进行组合来实现需求,因为直接使用lift()非常容易发生一些难以发现的错误。
- compose: 对 Observable 整体的变换
除了lift()外,Observable还有一个变换方法叫做compose(Transformer)。
它和lift()的区别在于:lift()是针对事件项和事件序列的,compose()是针对Observable自身进行变换。
举个例子,假设在程序中有多个Observable,并且他们都需要应用一组相同的lift()变换。你可以这么写:
observable1
.lift1()
.lift2()
.lift3()
.lift4()
.subscribe(subscriber1);
observable2
.lift1()
.lift2()
.lift3()
.lift4()
.subscribe(subscriber2);
observable3
.lift1()
.lift2()
.lift3()
.lift4()
.subscribe(subscriber3);
observable4
.lift1()
.lift2()
.lift3()
.lift4()
.subscribe(subscriber1);
你觉得这样太不软件工程了,于是你改成了这样:
private Observable liftAll(Observable observable) {
return observable
.lift1()
.lift2()
.lift3()
.lift4();
}
...
liftAll(observable1).subscribe(subscriber1);
liftAll(observable2).subscribe(subscriber2);
liftAll(observable3).subscribe(subscriber3);
liftAll(observable4).subscribe(subscriber4);
可读性、可维护性都提高了。可是Observable被一个方法包起来,这种方式对于Observale的灵活性似乎还是增添了那么点限制。怎么办?这个时候,就应该用compose()来解决了:
public class LiftAllTransformer implements Observable.Transformer<Integer, String> {
@Override
public Observable<String> call(Observable<Integer> observable) {
return observable
.lift1()
.lift2()
.lift3()
.lift4();
}
}
...
Transformer liftAll = new LiftAllTransformer();
observable1.compose(liftAll).subscribe(subscriber1);
observable2.compose(liftAll).subscribe(subscriber2);
observable3.compose(liftAll).subscribe(subscriber3);
observable4.compose(liftAll).subscribe(subscriber4);
像上面这样,使用compose()方法,Observable可以利用传入的Transformer对象的call方法直接对自身进行处理,也就不必被包在方法的里面了。
3.线程控制:Scheduler
- Scheduler
观察者模式本身的目的就是『后台处理,前台回调』的异步机制,因此异步对于 RxJava是至关重要的。
在不指定线程的情况下(即Schedulers.immediate()),RxJava遵循的是线程不变的原则,即:在哪个线程调用subscribe(),就在哪个线程生产事件;在哪个线程生产事件,就在哪个线程消费事件。如果需要切换线程,就需要用到Scheduler(调度器)。
RxJava 已经内置了几个Scheduler,它们已经适合大多数的使用场景:
·Schedulers.immediate(): 直接在当前线程运行,相当于不指定线程。
·Schedulers.newThread(): 总是启用新线程,并在新线程执行操作。
·Schedulers.io(): I/O 操作(读写文件、读写数据库、网络信息交互等)所使用的Scheduler.
行为模式和newThread()差不多,区别在于io()的内部实现是是用一个无数量上限的线程池,可以重用空闲的线程,因此多数情况下io()比newThread()更有效率。不要把计算工作放在io()中,可以避免创建不必要的线程。
·Schedulers.computation(): 计算所使用的Scheduler。
这个计算指的是 CPU 密集型计算,即不会被 I/O 等操作限制性能的操作,例如图形的计算。这个Scheduler使用的固定的线程池,大小为 CPU 核数。不要把 I/O 操作放在computation()中,否则 I/O 操作的等待时间会浪费 CPU。
·Android专用的AndroidSchedulers.mainThread():它指定的操作将在 Android 主线程运行。
有了这几个Scheduler,就可以使用subscribeOn()和observeOn()两个方法来对线程进行控制了。subscribeOn(): 指定subscribe()所发生的线程,即Observable.OnSubscribe被激活时所处的线程。或者叫做事件产生的线程。observeOn(): 指定 Subscriber所运行在的线程。或者叫做事件消费的线程。
Observable.just(1, 2, 3, 4)
.subscribeOn(Schedulers.io()) // 指定 subscribe() 发生在 IO 线程
.observeOn(AndroidSchedulers.mainThread()) //指定 Subscriber的回调发生在主线程
.subscribe(new Action1<Integer>() {
@Override
public void call(Integer number) {
Log.d(tag, "number:" + number);
}
});
上面这段代码中,由于subscribeOn(Schedulers.io())的指定,被创建的事件的内容1、2、3、4将会在IO线程发出;
而由于observeOn(AndroidScheculers.mainThread())的指定,因此subscriber数字的打印将发生在主线程。
事实上,这种在subscribe()之前写上两句subscribeOn(Scheduler.io())和observeOn(AndroidSchedulers.mainThread())的使用方式非常常见,它适用于多数的 『后台线程取数据,主线程显示』的程序策略。
- Scheduler 的 API
因为observeOn()指定的是Subscriber的线程,而这个Subscriber并不一定是subscribe()参数中的Subscriber,而是observeOn()执行时的当前Observable所对应的Subscriber,即它的直接下级Subscriber。换句话说,observeOn()指定的是它之后的操作所在的线程。因此如果有多次切换线程的需求,只要在每个想要切换线程的位置调用一次observeOn()即可。上代码:
Observable.just(1, 2, 3, 4) // IO 线程,由 subscribeOn() 指定
.subscribeOn(Schedulers.io())
.observeOn(Schedulers.newThread())
.map(mapOperator) // 新线程,由 observeOn() 指定
.observeOn(Schedulers.io())
.map(mapOperator2) // IO 线程,由 observeOn() 指定
.observeOn(AndroidSchedulers.mainThread)
.subscribe(subscriber); // Android 主线程,由observeOn()指定
如上,通过observeOn()的多次调用,程序实现了线程的多次切换。
不过,不同于observeOn(),subscribeOn()的位置放在哪里都可以,但它是只能调用一次的。
- Scheduler 的原理
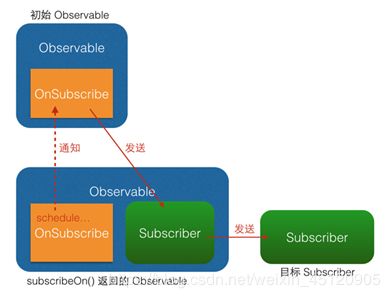
其实,subscribeOn()和observeOn()的内部实现,也是用的lift()。具体看图(不同颜色的箭头表示不同的线程):
subscribeOn()原理图:
observeOn()原理图:
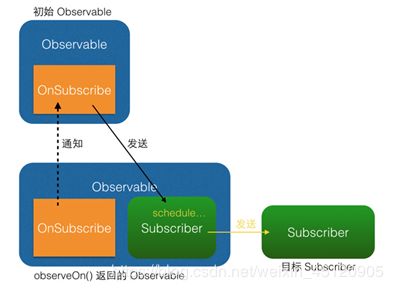
从图中可以看出,subscribeOn()和observeOn()都做了线程切换的工作(图中的 “schedule…” 部位)。不同的是,subscribeOn()的线程切换发生在OnSubscribe中,即在它通知上一级OnSubscribe时,这时事件还没有开始发送,因此subscribeOn()的线程控制可以从事件发出的开端就造成影响;而observeOn()的线程切换则发生在它内建的Subscriber中,即发生在它即将给下一级Subscriber发送事件时,因此observeOn()控制的是它后面的线程。
最后用一张图来解释当多个subscribeOn()和observeOn()混合使用时,线程调度是怎么发生的(由于图中对象较多,相对于上面的图对结构做了一些简化调整):
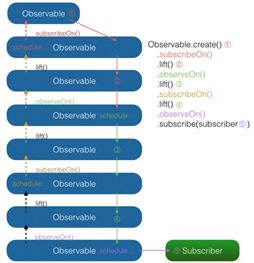
图中共有 5 处含有对事件的操作。由图中可以看出,
③ 和②两处受第一个subscribeOn()影响,运行在红色线程;
③和④处受第一个observeOn()的影响,运行在绿色线程;
⑤处受第二个onserveOn()影响,运行在紫色线程;
而第二个subscribeOn(),由于在通知过程中线程就被第一个subscribeOn()截断,因此对整个流程并没有任何影响。这里也就回答了前面的问题:当使用了多个subscribeOn()的时候,只有第一个subscribeOn()起作用。
- 延伸:doOnSubscribe()
虽然超过一个的subscribeOn()对事件处理的流程没有影响,但在流程之前却是可以利用的。
在前面讲Subscriber的时候,提到过Subscriber的onStart()可以用作流程开始前的初始化。然而onStart()由于在subscribe()发生时就被调用了,因此不能指定线程,而是只能执行在subscribe()被调用时的线程。这就导致如果onStart()中含有对线程有要求的代码(例如在界面上显示一个 ProgressBar,这必须在主线程执行),将会有线程非法的风险,因为有时你无法预测subscribe()将会在什么线程执行。而与Subscriber.onStart()相对应的,有一个方法Observable.doOnSubscribe()。它和Subscriber.onStart()同样是在subscribe()调用后而且在事件发送前执行,但区别在于它可以指定线程。默认情况下,doOnSubscribe()执行在subscribe()发生的线程;而如果在doOnSubscribe()之后有subscribeOn()的话,它将执行在离它最近的subscribeOn()所指定的线程。
示例代码:
Observable.create(onSubscribe)
.subscribeOn(Schedulers.io())
.doOnSubscribe(new Action0() {
@Override
public void call() {
progressBar.setVisibility(View.VISIBLE); // 需要在主线程执行
}
})
.subscribeOn(AndroidSchedulers.mainThread()) // 指定主线程
.observeOn(AndroidSchedulers.mainThread())
.subscribe(subscriber);
如上,在doOnSubscribe()的后面跟一个subscribeOn(),就能指定准备工作的线程了。
三、 RxJava+Retrofit封装网络请求框架
Retrofit 除了提供了传统的Callback形式的API,还有RxJava 版本的Observable形式API。
Retrofit 的 RxJava 版 API 和传统版本的区别,以获取一个User对象的接口作为例子:
使用Retrofit 的传统API,你可以用这样的方式来定义请求:
@GET("/user")
public void getUser(@Query("userId") String userId, Callback<User> callback);
在程序的构建过程中, Retrofit 会把自动把方法实现并生成代码,然后开发者就可以利用下面的方法来获取特定用户并处理响应:
getUser(userId, new Callback<User>() {
@Override
public void success(User user) {
userView.setUser(user);
}
@Override
public void failure(RetrofitError error) {
// Error handling
...
}
};
使用 RxJava 形式的 API,定义同样的请求是这样的:
@GET("/user")
public Observable<User> getUser(@Query("userId") String userId);
使用的时候是这样的:
getUser(userId)
.observeOn(AndroidSchedulers.mainThread())
.subscribe(new Observer<User>() {
@Override
public void onNext(User user) {
userView.setUser(user);
}
@Override
public void onCompleted() {
}
@Override
public void onError(Throwable error) {
// Error handling
...
}
});
当 RxJava 形式的时候,Retrofit 把请求封装进 Observable ,在请求结束后调用 onNext()或在请求失败后调用 onError()。
对比来看, Callback 形式和 Observable 形式长得不太一样,但本质都差不多,而且在细节上 Observable 形式似乎还比Callback形式要差点。
那 Retrofit 为什么还要提供 RxJava 的支持呢?
因为它好用啊!从这个例子看不出来是因为这只是最简单的情况。而一旦情景复杂起来,Callback 形式马上就会开始让人头疼。
假设这么一种情况:你的程序取到的 User 并不应该直接显示,而是需要先与数据库中的数据进行比对和修正后再显示。使用 Callback方式大概可以这么写:
getUser(userId, new Callback<User>() {
@Override
public void success(User user) {
processUser(user); // 尝试修正 User 数据
userView.setUser(user);
}
@Override
public void failure(RetrofitError error) {
// Error handling
...
}
};
很简便,但不要这样做。为什么?因为这样做会影响性能。数据库的操作很重,一次读写操作花费 10~20ms 是很常见的,这样的耗时很容易造成界面的卡顿。所以通常情况下,如果可以的话一定要避免在主线程中处理数据库。所以为了提升性能,这段代码可以优化一下:
getUser(userId, new Callback<User>() {
@Override
public void success(User user) {
new Thread() {
@Override
public void run() {
processUser(user); // 尝试修正 User 数据
runOnUiThread(new Runnable() { // 切回 UI 线程
@Override
public void run() {
userView.setUser(user);
}
});
}).start();
}
@Override
public void failure(RetrofitError error) {
// Error handling
...
}
};
性能问题解决,但代码实在是太乱了,影响团队开发效率的降低和出错率的升高。
这时候,如果用 RxJava 的形式,就好办多了。 RxJava 形式的代码是这样的:
getUser(userId)
.doOnNext(new Action1<User>() {
@Override
public void call(User user) {
processUser(user);
})
.observeOn(AndroidSchedulers.mainThread())
.subscribe(new Observer<User>() {
@Override
public void onNext(User user) {
userView.setUser(user);
}
@Override
public void onCompleted() {
}
@Override
public void onError(Throwable error) {
// Error handling
...
}
});
后台代码和前台代码全都写在一条链中,明显清晰了很多。
再举一个例子:假设/user接口并不能直接访问,而需要填入一个在线获取的token,代码应该怎么写?
Callback方式,可以使用嵌套的Callback:
@GET("/token")
public void getToken(Callback<String> callback);
@GET("/user")
public void getUser(@Query("token") String token, @Query("userId") String userId, Callback<User> callback);
...
getToken(new Callback<String>() {
@Override
public void success(String token) {
getUser(token, userId, new Callback<User>() {
@Override
public void success(User user) {
userView.setUser(user);
}
@Override
public void failure(RetrofitError error) {
// Error handling
...
}
};
}
@Override
public void failure(RetrofitError error) {
// Error handling
...
}
});
倒是没有什么性能问题,可是迷之缩进毁一生。
而使用 RxJava 的话,代码是这样的:
@GET("/token")
public Observable<String> getToken();
@GET("/user")
public Observable<User> getUser(@Query("token") String token, @Query("userId") String userId);
...
getToken()
.flatMap(new Func1<String, Observable<User>>() {
@Override
public Observable<User> onNext(String token) {
return getUser(token, userId);
})
.observeOn(AndroidSchedulers.mainThread())
.subscribe(new Observer<User>() {
@Override
public void onNext(User user) {
userView.setUser(user);
}
@Override
public void onCompleted() {
}
@Override
public void onError(Throwable error) {
// Error handling
...
}
});
用一个flatMap()就搞定了逻辑,依然是一条链