Hadoop大数据学习---Hadoop3.1.3(完全分布式实战)---使用脚本一键搭建Hadoop--精华篇(五)
Hadoop大数据学习----脚本,超详细,一键搭建Hadoop完全分布式集群,
前言
首先,很多网友催我快出完全分布式,但是我做一篇文章要很久,因为我对文章要求比较高,绝对不做烂帖,看到这篇文章,我建议你收藏,如网友们所愿,详细讲解搭建步骤,喂奶式教学,手刃新手搭建Bug,深扒新手Bug底层原理,解密免密登录原理, 以及脚本核心原理,Hadoop2.x.x和Hadoop3.x.x的区别,带大家来感受一下,脚本一键搭建集群的力量,也感受一下以后搭建集群,还要不要一个一个服务器的手敲配置,还是那句话,剑指Hadoop3.1.3,以白话文说大数据,以开源为精神,为更多想学习Hadoop的人,提供便利。
不懂,留言,我们先搭建,后理论,不玩一把,都不知道我们在干嘛
Hadoop3.1.3下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
上一章回顾
上一章我们讲了一个官方给的案例,同时测试了一下,我们的Hadoop是正常能用的,环境变量也配置的很好,并且Hadoop帮我们做了一下简单的单词统计,我们也了解了,原来Hadoop自己也可以做单词统计,做计算的时候,不需要任何外力,至于后面为什么会用Hive,Spark,Flink去做计算,我们一步一步来,慢慢说,下面我们就尝试着搭建一下完全分布式。
本篇学习内容
1.学习Hadoop3.1.3完全分布式搭建
2.配置集群免密登录,方便集群之间的文件传输。
3.实现功能:
免密登录
一键搭建Hadoop集群
一键 启动 / 关闭 Hadoop集群
一键查询集群所有节点状态。
4.学习Hadoop的简单理论,先搭建,后理论,玩一下才知道怎么回事,学习是一个循序渐进的过程。
5.一般搭建中,遇到的Bug,怎么解决。
完全分布式的搭建
前期的准备
1)准备3台客户机(关闭防火墙、静态ip、主机名称)
2)安装JDK
3)配置环境变量
4)安装Hadoop
5)配置环境变量
6)配置集群
7)单点启动
8)配置ssh
9)群起并测试集群
1.为什么准备三台虚拟机,首先我说明一点,准备10台行不行,可以的,但是考虑到大家电脑性能,三台刚好可以搭建一个简单的集群,也能搞定我们搭建Hadoop这个事儿,够我们学习,所以我们定为三台,当然多搭建几个也可以,搭建虚拟机教程在前面,不会的自己翻我之前的帖子。
2.安装JDK、Hadoop、配置JDK、Hadoop环境变量,上一篇文章已经带着大家做过了,这里不再做,不懂的翻我之前的帖子。
3.思考集群配置,我们上篇文章已经讲过,Hadoop里面包含了HDFS,MR(Mapreduce),Yarn,Commen这四大模块,这里再重新说一次。
HDFS:数据到Hadoop了,得有地方存吧?它就负责存储的
MR(Mapreduce):负责计算,数据过来了,总得处理吧?它就是干这个的。
Yarn:负责任务调度,这个后面会去说,记住就是任务调度就行
Commen:辅助,玩联盟没辅助能行么?就这个道理,简单理解下。
首先我们启动三台虚拟机,具体配置不讲,上几篇文章都有。连接XShell。

设置免密登录
很多帖子发的免密登录我不想吐槽,实力带躺,好好看下面五杀操作
为什么设置免密
从一台虚拟机上登录到另一台需要密码,两个机子之间传输文件也需要密码,所以我们把密码直接设成免密,这样会更方便。
免密登录原理
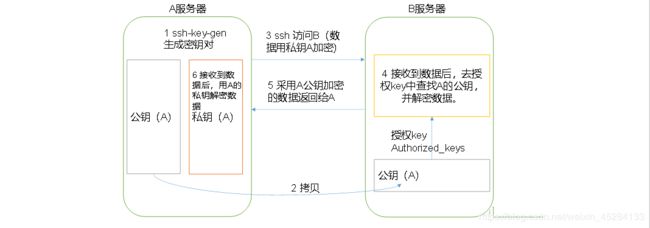
第一步:
输入:ssh-keygen -t rsa,然后连敲四下回车
生成密钥对,id_rsa公钥和id_rsa.pub私钥。

第二步:
将公钥拷贝到要免密登录的目标机器上
依次输入命令:
ssh-copy-id hadoop101
ssh-copy-id hadoop102
ssh-copy-id hadoop103
第一次输入ssh-copy-id hadoop101会出现这个情况,
直接yes

出现这个直接输入root密码就可以

然后
ssh-copy-id hadoop102
ssh-copy-id hadoop103也是一样。
然后在hadoop102,hadoop103上同样输入ssh-keygen -t rsa,然后输入ssh-copy-id hadoop101,ssh-copy-id hadoop102,ssh-copy-id hadoop103这三条命令。重复上面操作,免密就成功了。
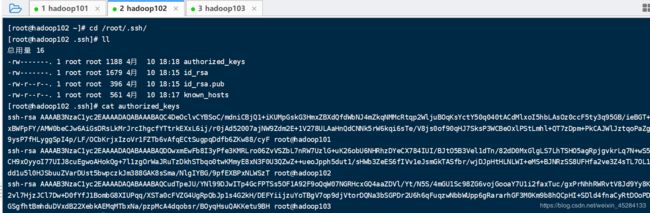
我们看一下102里面有个文件叫authorized_id,我们进去看一眼,它是什么,你们就懂了。

看到它每第三行最后末尾是hadoop101,hadoop102,hadoop103没?我现在是在102里看的这个文件,它里面代表已经有了101,102,103的公钥。这里就是免密的奥秘。
注意事项:
免密登录,只对当前用户永久生效,你换一个用户登录,还要重新配置免密登录。
如果你是其他用户,不是root,那么这个.ssh文件是隐藏文件在普通用户的home目录下。
测试免密登录
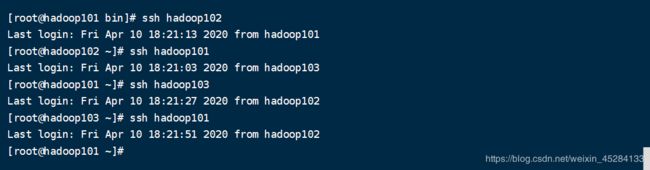
在hadoop103上面输入命令:
ssh hadoop101 目的:看看是否能瞬间登录到hadoop101不需要密码,然后再输入ssh hadoop102 每台虚拟机都要这样去测试,三台都能相互连通,则免密成功。
这里有没有免密失败的?怎么办?找帖子?不需要,由于烂贴太多,这里直接顺带着说一下,免得浪费时间。非常简单,删除公钥,重新再来一遍上面的操作,保险起见,把三台虚拟机的公钥都删了重新生成。
又有人问,id_rsa公钥,id_rsa.pub私钥在哪里?删除它俩就可以
博主喂奶式教学:cd /root/.ssh下就可以查看

制作一键分发脚本
在路径usr/local/bin目录下创建脚本名字自己定,我的是xsync

#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop101 hadoop102 hadoop103
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
脚本核心原理
这就是个简单的脚本,你们自己还可以完善,就是简单的实现分发的功能。
就这句:rsync -av p d i r / pdir/ pdir/fname h o s t : host: host:pdir
为什么呢?
我们可以玩个游戏,我们现在有三台虚拟机,我想在103上面拿101上面的东西,在知道他密码的情况下,不经过他同意,可不可以,我们设置过免密了,如果没设置我们就得输入密码才能传,这里我们是直接就传输了,你们可以把密钥删了,玩一把
首先我们在Hadoop101的上创建一个文件
命令:
cd /opt/moudle/ 进入到module中
然后我们创建一个aaa.txt文件里面写上1234567

在103上输入命令去101上拿,还是那句话,我设置免密了,瞬间就能拿到,并放到我的103上的module中,如果你们想玩不带密码的,把公钥删了,上面已经教过了。
我们去看一下103中是不是什么都没有
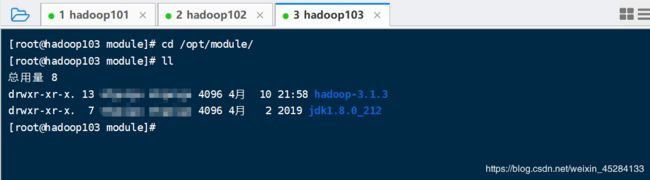
没有,我就去101上拿,看能不能拿到,很不巧,拿到了。

思考题
我能不能在102上面讲101的东西给103?假如你在单位,同时知道了同事A的密码和同事B的密码,能不能不经过他俩同意,将他们的资料,文件,相互传输呢?自己可以试试,不会了可以私信,或者底下留言。
授权chmod 777 xsync

集群布局:
Hadoop101:我们配置NameNode,DataNode ,NodeManager
Hadoop102:我们配置DataNode,ResourceManager,NodeManager
Hadoop102:我们配置SecondaryNameNode,DataNode ,NodeManager
| hadoop101 | hadoop102 | hadoop103 | |
|---|---|---|---|
| HDFS | NameNode,DataNode | DataNode | SecondaryNameNode,DataNode |
| Yarn | NodeManager | ResourceManager,NodeManager | NodeManager |
Hadoop核心配置文件:
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
hadoop-env.sh
配置workers(群起集群用的)
配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
默认配置文件:
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-3.1.3.jar/ core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/ hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/ yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/ mapred-default.xml |
自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
执行步骤
(1)配置集群
(a)配置:hadoop-env.sh
Linux系统中获取JDK的安装路径:
一个窗口专门负责获取路径等等其他操作。
另一个窗口去配置配置信息
修改hadoop-env.sh中的JAVA_HOME 路径:
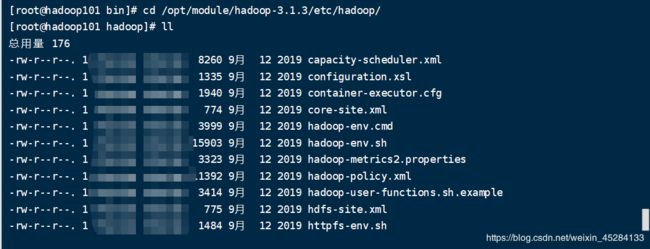
怎么找到这个文件,其实Hadoop的所有用户可修改的配置文件,都在这个路径下,可以重点记一下,因为后面完全分布式,经常要用到,重点记一下!!!
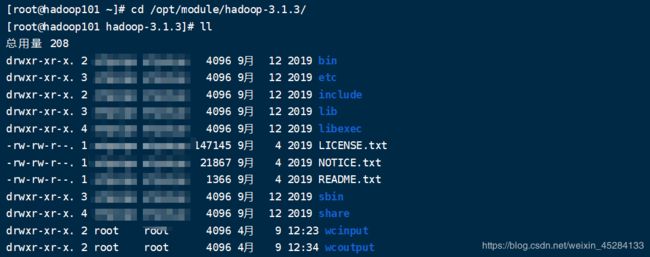
 cd /opt/module/hadoop-3.1.3/etc/hadoop
cd /opt/module/hadoop-3.1.3/etc/hadoop
第二种写法:cd $HADOOP_HOME/etc/hadoop
开始配置hadoop-env.sh添加环境变量

光标位置把#去掉打开export JAVA_HOME,把JDK路径粘进去。

变成这样,然后保存退出,命令ESC,然后冒号,然后输入WQ回车

开始配置core-site.xml添加环境变量

打开之后这样的,后面的所有的xml文件打开都是这样的步一一展示了
把下面配置粘到里面即可,里面主要配置了NameNode的端口号,还有数据存储的路径。
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9820</value>
</property>
<!-- 指定hadoop数据的存储目录
官方配置文件中的配置项是hadoop.tmp.dir ,用来指定hadoop数据的存储目录,此次配置用的hadoop.data.dir是自己定义的变量, 因为在hdfs-site.xml中会使用此配置的值来具体指定namenode 和 datanode存储数据的目录
-->
<property>
<name>hadoop.data.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
vim hdfs-site.xml 里面配置如下
<!-- 指定NameNode数据的存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.data.dir}/name</value>
</property>
<!-- 指定Datanode数据的存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.data.dir}/data</value>
</property>
<!-- 指定SecondaryNameNode数据的存储目录 -->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file://${hadoop.data.dir}/namesecondary</value>
</property>
<!-- 兼容配置,先跳过 -->
<property>
<name>dfs.client.datanode-restart.timeout</name>
<value>30s</value>
</property>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
vim yarn-site.xml 里面配置如下
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
vim mapred-site.xml 里面配置如下
这个以前版本都需要改名字,3.1.3版本不需要改
<!—指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置workers

脚本一件分发,秒搭建集群
cd到Hadoop102 和 hadoop103的opt下面创建文件夹,module
cd /opt/
mkdir module

启动脚本
分发Hadoop,JDK,在Hadoop101中我们启动脚本,因为脚本在它身上


开始分发JDK,其实也可以一起分发
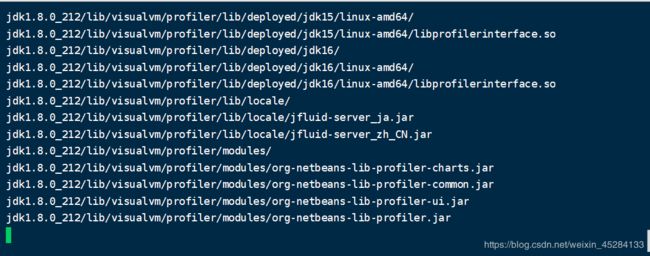
我们看一下102,103中有没有Hadoop还有JDK
证明我们成功了一半,我们还要分发一下环境变量,因为hadoop102 和 hadoop103中没有配置环境变量,依然分发,尝到了脚本的强大
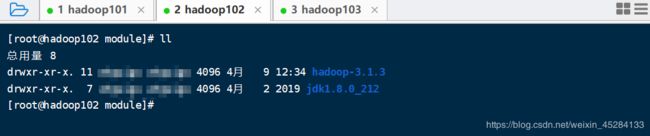
分发环境变量,还在Hadoop101中启动脚本,没有配置环境变量的,看我上一篇帖子怎么配置的,这里不讲

分发完成,我们去102,103上看一下有没有环境变量文件

我看了一下102,103都是有的,如下图
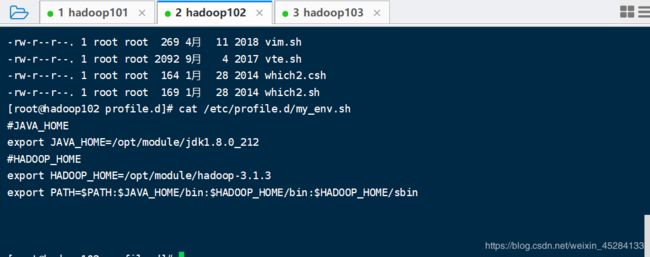
再查看一下102,103的Hadoop的配置文件配置没有,做事要严谨,发现也是有的

分发配置workers

查看一下workers

启动一下试一试,第一次启动集群,我们需要先格式化一下NameNode,而它配置再我们的101身上,我们到101,执行启动命令。我们单点启动
注意:只有第一次启动集群需要格式化NameNode,以后启动不需要格式化
命令:hdfs namenode -format格式化NameNode
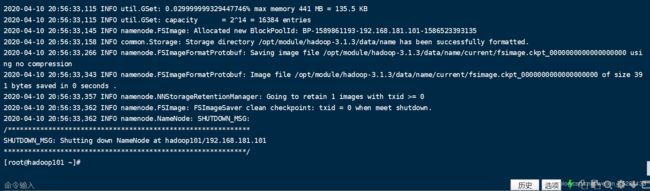
单点启动NameNode,命令:hdfs --daemon start namenode
输入JPS命令查看NameNode是否存在,这里我们已经成功了
JPS是java的命令,能够帮助我们查看所有JAVA的进程,
我们启动一个NameNode就是一个JAVA进程,也是一个JAVA类,这种类里面都有一个Main方法
用jps -l就能看到
甚至JPS都是一个JAVA类也有Main方法
怎么访问它呢,通过web页面就能访问它

再看一眼DataNode也启动成功了

如果没有格式化,直接启动了namenode会启动不了,这个时候我们需要删除
cd /opt/module/hadoop-3.1.3/下的data和logs文件夹就可以了
没有格式化,然后NameNode启动不起来的错误原理
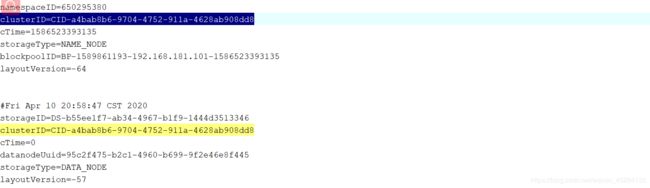
我们启动NameNode和DataNode会产生相同的ClusterID,也就是集群ID,DataNode之所以启动就能够找到NameNode是因为他们两个的集群ID相同,所以能找到,而这个集群ID就在data目录下,我们去看看。
进去之后我们会发现有两个文件夹,一个叫name,一个叫data,其实都是我们在xml文件中配置好的,就是为了他们生成后,我们以后好识别,好维护。

我们是在hdfs-size中配置了NameNode和DataNode的生成路径,放到了name,data下面,大括号括起来的是引用配置文件里的配置项,配置项在core-size中我们配置过,配置文件之间是相互调用的。

core-size中的配置看name标签。

而他们两个文件夹里装了什么,我们来先看一下Name的,我pwd了一下,让你们看到路径

这里面有个VERSION 我们进去看一下
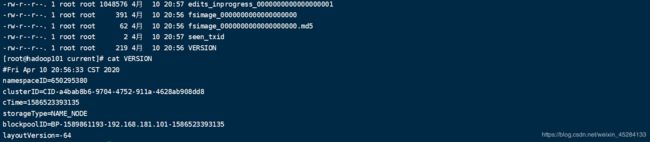
我们再去看一下Data文件夹下有什么,我依然pwd了一下,让你们看一下路径,你们也可以进去,然后我们发现里面也有一个VERSION,我们进去看一下,返现也有一堆东西。
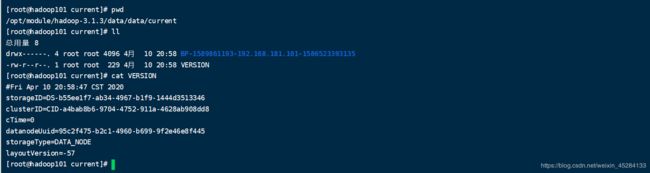
但是我们惊奇的发现他们俩的这堆东西里都有一个叫clusterID的东西,并且相同一摸一样,这我就明白了,原来他们HDFS中的NameNode和DataNode能够通信,相互认识,集群启动的第一时间,DataNode就能够找到NameNode,靠的就是这个。我把他们粘贴出来,你们看的更清楚,上面的是NameNode的下面的是DataNode的,他们底层是这样的,所以说,我们明白了NameNode与DataNode的联系。
我们再把剩下的Hadoop进程都启动起来,把整个集群启动,看一下效果。
在102,103上启动DataNode,一样的命令,在这个集群中,我们上面图纸已经标清了,哪个里面装了什么,这里有点懵的可以往回翻看图纸。


我们打开浏览器,输入Hadoop101:9870回车,说明我们的Hadoop正常启动,没有问题,我还没有启动别的节点,就是测试一下我们的集群,搭建到这里,是不是个好的。
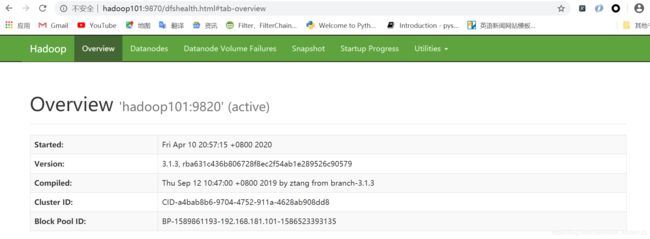
点击DataNodes,往下拉动,会发现三个DataNode正常工作,我们这一步走的很稳。
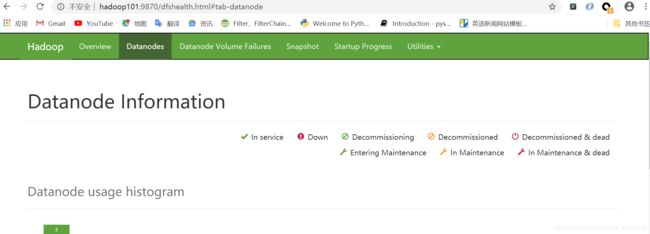
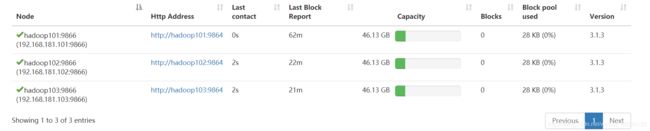
我们把剩下的都启动了来看看效果,这回我们看着图启动,免得懵

Hadoop101上我们启动 或 关闭 NodeManager
命令:
yarn --daemon start/stop nodemanager
Hadoop102上我们启动 或 关闭ResourceManager,NodeManager
命令:
yarn --daemon start/stop resourcemanager
yarn --daemon start/stop nodemanager
Hadoop103上我们启动 或 关闭NodeManager和secondarynamenode
命令:
yarn --daemon start/stop nodemanager
hdfs --daemon start/stop secondarynamenode
我们去看一下每台服务器上的进程,命令是JPS。
先看Hadoop101

再看Hadoop102

再看Hadoop103

思考题:
JPS是我们查看集群进程的命令,我们每在一台服务器上启动一些节点,想看一下启动成功没有,就会输入JPS看一眼,但是突然有一天,领导和你说,公司有3000台服务器,去看一眼每个服务器上都运行着什么,难不成你一个一个服务器去敲指令么?去JPS么?
答案:脚本一键查看集群进程
编写脚本,脚本统一放在Hadoop101的/usr/local/bin
里面

脚本如图所示,博主喂奶教程,再给你备一份,怕你敲错。

#! /bin/bash
for i in hadoop101 hadoop102 hadoop103
do
echo --------- $i ----------
ssh $i "$*"
done
试一试脚本怎么样,在Hadoop101上启动脚本,就可以看见整个集群的所有进程。自己感受,不多说。

然后我们再打开另外一个浏览器,访问Hadoop102:8088回车,会出现Yarn的Web页面。
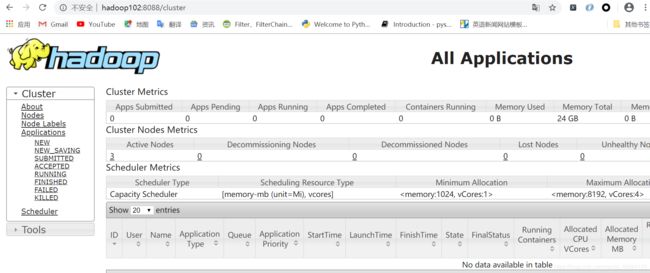
我们打开另一个浏览器页面,输入Hadoop103:9868回车,会出现SecondaryNamenode的Web页面。

所有的Web页面出现了,这就证明,我们Hadoop3.1.3安装的非常成功。
这是我们之前的命令:
逐一命令启动 或者 关闭 HDFS上的所有节点
hdfs --daemon start/stop namenode/datanode/secondarynamenode
逐一命令启动 或者 关闭 Yarn上的所有节点
yarn --daemon start/stop resourcemanager/nodemanager
思考题
走到这一步,我们的集群其实就已经搭建好了,只是给大家讲了一些额外的东西,但是我们思考一个问题,就是我们如果有上千上万个服务器,我们还这样一个一个的去每个服务器上敲启动指令么?你去了公司,有三万台服务器,然后项目经理说,你去把所有服务器上的DataNode,secondarynamenode,resourcemanager,nodemanager启动起来还有NameNode,怎么办呢?
官方集群脚本
Hadoop3.1.3提供了自动群起脚本,而Hadoop的脚本都放在了哪里
查看命令:cd /opt/module/hadoop-3.1.3/sbin/
你会发现里面有提供好了所有的启动 关闭脚本,还有群起的脚本,不建议用all,在实际开发中没人用all。
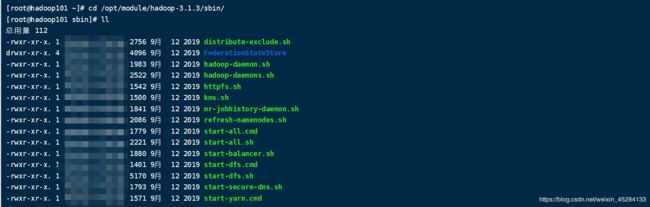
启动 关闭hdfs
start-dfs.sh stop-dfs.sh 我现在集群式开启的,我单点关闭一下,我试一下能不能一键启动hdfs,报错了,这是好事情。

我们充分发挥了面向百度编程的要领,去网上搜了些帖子,
找到了解决这个问题的方法
在我们的hadoop-env.sh这个配置文件中,我们加进去些环境变量
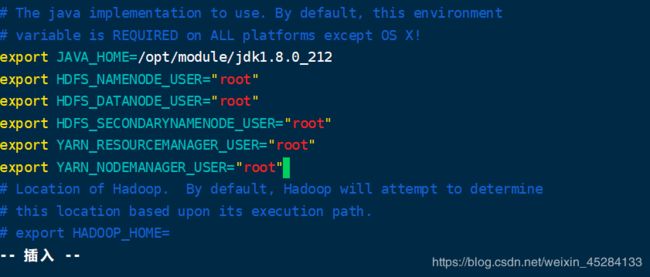
再启动一下,神奇的事,发生了。还是那句话,遇到bug,它要什么,我们就给什么,bug就能解决

我们再启动一下Yarn的所有进程。
start-yarn.sh stop-yarn.sh

查看一下所有的节点信息,用脚本JPS一下

发现还是有进程没有启动起来,你们不一定又这个bug,遇到bug怎么办?先自我排除,再面向百度,肯定是我改完了配置,没有格式化namenode,以前的datanode的clusterID与现在的namenode的clusterID不一样了,这个时候二话不说,走上面流程,先关闭集群,删除data,logs,然后重新格式化NameNode,
保证了集群节点全部关闭

因为我们是集群嘛,在Hadoop101,Hadoop102,Hadoop103上,删除data logs文件夹,记住,在一台上删除时没有用的。
直接递归删除走一波,发现是不是没有了。

格式化NameNode

两个集群启动命令一敲,是不是正常启动了

我还觉得这样启动集群太麻烦,还要敲两个命令,我能不能写一个脚本,然后通过脚本一键启动
制作脚本,一键启动Hadoop3.1.3集群
我们先关闭集群,然后去制作脚本,每次关闭集群,查一下进程,做事要严谨,看一下有没有遗漏的进程还活着,有,就酒杀

老规矩,到 cd /usr/local/bin/下创建我们的脚本,看不懂的,看我前两篇Shell教程,专门教了制作脚本,今天我们全都用上

脚本如下:
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input Error!!!!!"
exit
fi
case $1 in
"start")
echo "======================== start hdfs ========================== "
ssh hadoop101 /opt/module/hadoop-3.1.3/sbin/start-dfs.sh
echo "======================== start yarn ========================== "
ssh hadoop102 /opt/module/hadoop-3.1.3/sbin/start-yarn.sh
;;
"stop")
echo "======================== stop yarn ========================== "
ssh hadoop102 /opt/module/hadoop-3.1.3/sbin/stop-yarn.sh
echo "======================== stop hdfs ========================== "
ssh hadoop101 /opt/module/hadoop-3.1.3/sbin/stop-dfs.sh
;;
*)
echo "Input Args Error!!!!!"
;;
esac
试试脚本好不好用,脚本名加start。
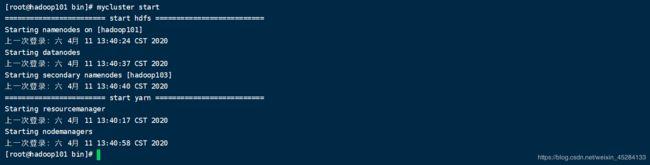
老规矩,做事要严谨,查看进程

看一下我们的web页面是不是都显示正常
Yarn没问题

NameNode没问题
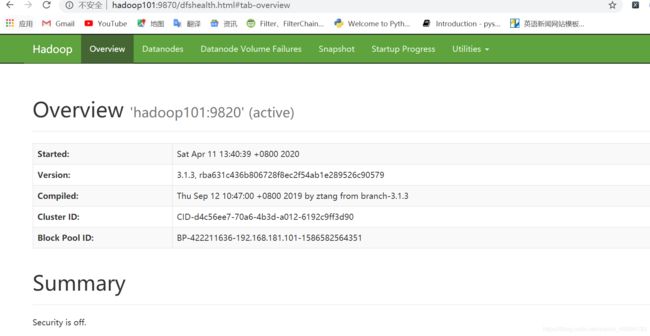
DataNode没问题

SecondaryNameNode没问题
完美,今天Hadoop3.1.3,全部教程,奉上,不会的底下留言,下期见
额外点:
1. 配置历史服务器
- 配置在mapred-site.xml中即可

<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop101:19888</value>
</property>
分发一下:xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
启动命令::mapred --daemon start historyserver
效果图:
查看页面http://hadoop101:19888/jobhistory
配置日志收集
配置yarn-site.xml
命令:vim yarn-site.xml
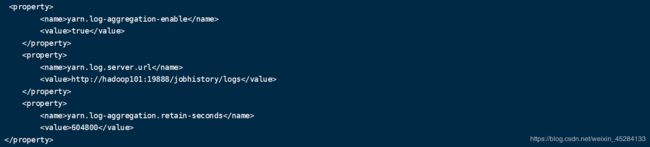
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop101:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
效果:
尾声
学了hadoop3.1.3我们还是要深入了解一下,没兴趣的可以不看
Hadoop 3.x 和2.x主要区别
1)最低Java版本从7升级到8
2)引入纠删码(Erasure Coding)
主要解决数据量大到一定程度磁盘空间存储能力不足的问题.
HDFS中的默认3副本方案在存储空间中具有200%的额外开销。但是,对于I/O活动相对较少冷数据集,在正常操作期间很少访问其他块副本,但仍然会消耗与第一个副本相同的资源量。
纠删码能勾在不到50%数据冗余的情况下提供和3副本相同的容错能力,因此,使用纠删码作为副本机制的改进是自然而然,也是未来的趋势.
3)重写了Shell脚本
重写了Shell脚本,修改了之前版本长期存在的一些错误,并提供了一些新功能,在尽可能保证兼容性的前提下,一些新变化仍然可能导致之前的安装出现问题。
例如:
所有Hadoop Shell脚本子系统现在都会执行hadoop-env.sh这个脚本,它允许所有环节变量位于一个位置;
守护进程已通过*-daemon.sh选项从*-daemon.sh移动到了bin命令中,在Hadoop3中,我们可以简单的使用守护进程来启动、停止对应的Hadoop系统进程;
4)引入了新的API依赖
之前Hadoop客户端操作的Maven依赖为hadoop-client,这个依赖直接暴露了Hadoop的下级依赖,当用户和Hadoop使用相同依赖的不同版本时,可能造成冲突。
Hadoop3.0引入了提供了hadoop-client-api 和hadoop-client-runtime依赖将下级依赖隐藏起来,一定程度上来解决依赖冲突的问题
5)MapReduce任务的本地化优化
MapReduce引入了一个NativeMapOutputCollector的本地化(C/C++)实现,对于shuffle密集的任务,可能提高30%或者更高的性能
6)支持超过两个NN
HDFS NameNode高可用性的初始实现为单个Active NameNode 和 单个 Standby NameNode, 将edits复制到三个JournalNode。 该体系结构能够容忍系统中一个NN或者一个JN故障.但是,某些部署需要更高程序的容错能力,Hadoop3.x允许用户运行一个Active NameNode 和 多个 Standby NameNode。
7)许多服务的默认端口改变了
Hadoop3.x之前,多个Hadoop服务的默认端口位于Linux临时端口范围(63768~61000). 这意味着在启动时,由于与另一个应用程序冲突,服务有时无法绑定到端口.
在Hadoop3.x中,这些可能冲突的端口已移出临时范围,受影响的有NameNode ,
SecondaryNamenode , DataNode 和 KMS
8)添加对Microsoft Azure Data Lake 和 阿里云对象存储系统的支持
9)DataNode内部实现Balancer
一个DN管理多个磁盘,当正常写入时,多个磁盘是平均分配的。然而当添加新磁盘时,这种机制会造成DN内部严重的倾斜。
之前的DataNode Balancer只能实现DN之间的数据平衡,Hadoop3.x实现了内部的数据平衡。
10)重做的后台和任务堆内存管理
已实现根据服务器自动配置堆内存,HADOOP_HEAPSIZE变量失效。简化MapTask 和ReduceTask的堆内存配置,现已不必同时在配置中和Java启动选项中指定堆内存大小,旧有配置不会受到影响。
11)HDFS实现服务器级别的Federation分流
对于HDFS Federation, 添加了一个对统一命名空间的RPC路由层 。 和原来的HDFS Federation没有变化,只是目前挂在管理不必在客户端完成,而是放在的服务器,从而简化了HDFS Federation访问。
12)Yarn的时间线服务升级到V2
Yarn的时间线服务是MRJobHistory的升级版,提供了在Yarn上运行第三方程序的历史支持,该服务在Hadoop3.0升级为第二版
13)容量调度器实现API级别的配置
现在容量调度器可以实现通过REST API来改变配置,从而让管理员可以实现调度器自动配置。
14)Yarn实现更多种资源类型的管理
Yarn调度器现已可以通过配置实现用户自定义的资源管理。现在Yarn可以根据CPU和内存意外的资源管理其任务队列