JUC之深入分析 CAS
一、概述
- CAS ,Compare And Swap ,即比较并交换。Doug Lea 大神在实现同步组件时,大量使用CAS 技术,鬼斧神工地实现了Java 多线程的并发操作。
- 整个 AQS 同步组件、Atomic 原子类操作等等都是基 CAS 实现的,甚至 ConcurrentHashMap 在 JDK 1.8 的版本中,也调整为 CAS + synchronized 。可以说,CAS 是整个 J.U.C 的基石。
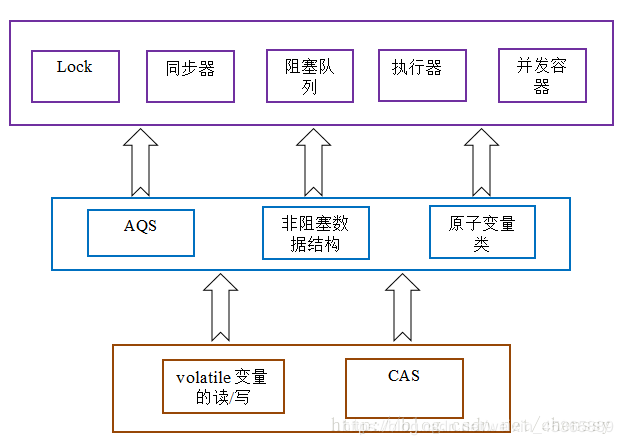
二、CAS分析
1.在 CAS 中有三个参数:内存值 V、旧的预期值 A、要更新的值 B ,当且仅当内存值 V 的值等于旧的预期值 A 时,才会将内存值V的值修改为 B ,否则什么都不干。其伪代码如下:
if (this.value == A) {
this.value = B
return true;
} else {
return false;
}
2.J.U.C 下的 Atomic 类,都是通过 CAS 来实现的。下面就以 AtomicInteger 为例,来阐述 CAS 的实现。如下:
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
Unsafe 是 CAS 的核心类,Java 无法直接访问底层操作系统,而是通过本地 native 方法来访问。不过尽管如此,JVM还是开了一个后门:Unsafe ,它提供了硬件级别的原子操作。
valueOffset 为变量值在内存中的偏移地址,Unsafe 就是通过偏移地址来得到数据的原值的。 value 当前值,使用 volatile 修饰,保证多线程环境下看见的是同一个。
三、AtomicInteger
1.我们就以 AtomicInteger 的 #addAndGet() 方法来做说明,先看源代码:
// AtomicInteger.java
public final int addAndGet(int delta) {
return unsafe.getAndAddInt(this, valueOffset, delta) + delta;
}
// Unsafe.java
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
2.内部调用 unsafe 的 #getAndAddInt(Object var1, long var2, int var4)方法,在#getAndAddInt(Object var1, long var2, int var4) 方法中,主要是看 #compareAndSwapInt(Object var1, long var2, int var4, int var5) 方法,代码如下:
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
该方法为本地方法,有四个参数,分别代表:对象、对象的地址、预期值、修改值
四、CPU 原子操作
1.CAS 可以保证一次的读-改-写操作是原子操作,在单处理器上该操作容易实现,但是在多处理器上实现就有点儿复杂了。CPU 提供了两种方法来实现多处理器的原子操作:总线加锁或者缓存加锁。
- 总线加锁:总线加锁就是就是使用处理器提供的一个 LOCK# 信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占使用共享内存。但是这种处理方式显得有点儿霸道,不厚道,他把CPU和内存之间的通信锁住了,在锁定期间,其他处理器都不能使用其他内存地址的数据,其开销有点儿大。所以就有了缓存加锁。
- 缓存加锁:其实针对于上面那种情况,我们只需要保证在同一时刻,对某个内存地址的操作是原子性的即可。缓存加锁,就是缓存在内存区域的数据如果在加锁期间,当它执行锁操作写回内存时,处理器不再输 出LOCK# 信号,而是修改内部的内存地址,利用缓存一致性协议来保证原子性。缓存一致性机制可以保证同一个内存区域的数据仅能被一个处理器修改,也就是说当 CPU1 修改缓存行中的 i 时使用缓存锁定,那么 CPU2 就不能同时缓存了 i 的缓存行。
五、CAS缺陷
1.CAS 虽然高效地解决了原子操作,但是还是存在一些缺陷的,主要表现在三个方面:
- 循环时间太长
- 只能保证一个共享变量原子操作
- ABA 问题
六、循环时间太长
- 如果CAS一直不成功呢?这种情况绝对有可能发生,如果自旋 CAS 长时间地不成功,则会给 CPU 带来非常大的开销。在 J.U.C 中,有些地方就限制了 CAS 自旋的次数,例如: BlockingQueue 的 SynchronousQueue 。
七、只能保证一个共享变量原子操作
- 看了 CAS 的实现就知道这只能针对一个共享变量,如果是多个共享变量就只能使用锁了,当然如果你有办法把多个变量整成一个变量,利用 CAS 也不错。例如读写锁中 state 的高低位。
八、ABA问题
- CAS 需要检查操作值有没有发生改变,如果没有发生改变则更新。但是存在这样一种情况:如果一个值原来是 A,变成了 B,然后又变成了 A,那么在 CAS 检查的时候会发现没有改变,但是实质上它已经发生了改变,这就是所谓的ABA问题。对于 ABA 问题其解决方案是加上版本号,即在每个变量都加上一个版本号,每次改变时加 1 ,即 A —> B —> A ,变成1A —> 2B —> 3A 。
九、影响
用一个例子来阐述 ABA 问题所带来的影响。
有如下链表如下图:

假如我们想要把 A 替换为 B ,也就是 #compareAndSet(this, A, B) 。线程 1 执行 A 替换 B 操作之前,线程 2 先执行如下动作,A 、B 出栈,然后 C、A 入栈,最终该链表如下:
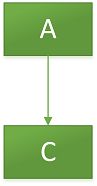
完成后,线程 1 发现仍然是 A ,那么 #compareAndSet(this, A, B) 成功,但是这时会存在一个问题就是 B.next = null,因此 #compareAndSet(this, A, B) 后,会导致 C 丢失,改栈仅有一个 B 元素,平白无故把 C 给丢失了。
十、解决方案 AtomicStampedReference
1.CAS 的 ABA 隐患问题,解决方案则是版本号,Java 提供了 AtomicStampedReference 来解决。AtomicStampedReference 通过包装 [E,Integer] 的元组,来对对象标记版本戳 stamp ,从而避免 ABA 问题。对于上面的案例,应该线程 1 会失败。
2.AtomicStampedReference 的 #compareAndSet(...) 方法,代码如下:
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}
有四个方法参数,分别表示:预期引用、更新后的引用、预期标志、更新后的标志。源码部分很好理解:
- 预期的引用 == 当前引用
- 预期的标识 == 当前标识
- 如果更新后的引用和标志和当前的引用和标志相等,则直接返回 true
- 通过 Pair#of(T reference, int stamp) 方法,生成一个新的 Pair 对象,与当前 Pair CAS 替换。
Pair 为 AtomicStampedReference 的内部类,主要用于记录引用和版本戳信息(标识),定义如下:
// AtomicStampedReference.java
private static class Pair {
final T reference; // 对象引用
final int stamp; // 版本戳
private Pair(T reference, int stamp) {
this.reference = reference;
this.stamp = stamp;
}
static Pair of(T reference, int stamp) {
return new Pair(reference, stamp);
}
}
private volatile Pair pair;
- Pair 记录了对象的引用和版本戳,版本戳为 int 型,保持自增。同时 Pair 是一个不可变对象,其所有属性全部定义为 final 。对外提供一个 #of(T reference, int stamp) 方法,该方法返回一个新建的 Pair 对象。
- pair 属性,定义为 volatile ,保证多线程环境下的可见性。在AtomicStampedReference 中,大多方法都是通过调用 Pair 的 #of(T reference, int stamp) 方法,来产生一个新的 Pair 对象,然后赋值给变量 pair 。如 set(V newReference, int newStamp)方法,代码如下:
// AtomicStampedReference.java
public void set(V newReference, int newStamp) {
Pair current = pair;
if (newReference != current.reference || newStamp != current.stamp)
this.pair = Pair.of(newReference, newStamp);
}
十一、实际案例
下面,我们将通过一个例子,可以看到 AtomicStampedReference 和 AtomicInteger 的区别。我们定义两个线程,线程 1 负责将 100 —> 110 —> 100,线程 2 执行 100 —>120 ,看两者之间的区别。
public class Test {
private static AtomicInteger atomicInteger = new AtomicInteger(100);
private static AtomicStampedReference atomicStampedReference = new AtomicStampedReference(100,1);
public static void main(String[] args) throws InterruptedException {
// AtomicInteger
Thread at1 = new Thread(new Runnable() {
@Override
public void run() {
atomicInteger.compareAndSet(100,110);
atomicInteger.compareAndSet(110,100);
}
});
Thread at2 = new Thread(new Runnable() {
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(2); // at1,执行完
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("AtomicInteger:" + atomicInteger.compareAndSet(100,120));
}
});
at1.start();
at2.start();
at1.join();
at2.join();
// AtomicStampedReference
Thread tsf1 = new Thread(new Runnable() {
@Override
public void run() {
try {
//让 tsf2先获取stamp,导致预期时间戳不一致
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 预期引用:100,更新后的引用:110,预期标识getStamp() 更新后的标识getStamp() + 1
atomicStampedReference.compareAndSet(100,110,atomicStampedReference.getStamp(),atomicStampedReference.getStamp() + 1);
atomicStampedReference.compareAndSet(110,100,atomicStampedReference.getStamp(),atomicStampedReference.getStamp() + 1);
}
});
Thread tsf2 = new Thread(new Runnable() {
@Override
public void run() {
int stamp = atomicStampedReference.getStamp();
try {
TimeUnit.SECONDS.sleep(2); //线程tsf1执行完
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("AtomicStampedReference:" +atomicStampedReference.compareAndSet(100,120,stamp,stamp + 1));
}
});
tsf1.start();
tsf2.start();
}
}
运行结果:

运行结果充分展示了 AtomicInteger 导致的 ABA 问题,和使用 AtomicStampedReference 解决 ABA 问题。
最后
如果你看到了这里,觉得文章写得不错就给个赞呗!欢迎大家评论讨论!如果你觉得那里值得改进的,请给我留言。一定会认真查询,修正不足,定期免费分享技术干货。喜欢的小伙伴可以关注一下哦。谢谢!
