飞桨文字识别模型套件PaddleOCR首次开源,带来8.6M超轻量中英文OCR模型!

OCR技术有着丰富的应用场景,包括已经在日常生活中广泛应用的面向垂类的结构化文本识别,如车牌识别、银行卡信息识别、身份证信息识别、火车票信息识别等等,此外,通用OCR技术也有广泛的应用,如在视频场景中,经常使用OCR技术进行字幕自动翻译、内容安全监控等等,或者与视觉特征相结合,完成视频理解、视频搜索等任务。

OCR文字检测和识别目前的主流方法大多是采用深度学习技术,这从ICDAR2015自然场景排名前列的应用方法可以明显看出。深度学习技术在一些垂类场景,文本识别精准度已经可以达到99%以上,取得了非常好的效果。
但在实际应用中,尤其是在广泛的通用场景下,OCR技术也面临一些挑战,比如仿射变换、尺度问题、光照不足、拍摄模糊等技术难点;另外OCR应用常对接海量数据,但要求数据能够得到实时处理;并且OCR应用常部署在移动端或嵌入式硬件,而端侧的存储空间和计算能力有限,因此对OCR模型的大小和预测速度有很高的要求。
在这样的背景下,飞桨首次开源文字识别模型套件PaddleOCR,目标是打造丰富、领先、实用的文本识别模型/工具库。首阶段的开源套件推出了重磅模型:8.6M超轻量中英文识别模型。用户既可以很便捷的直接使用该超轻量模型,也可以使用开源套件训练自己的超轻量模型。
项目地址:
https://github.com/PaddlePaddle/PaddleOCR
8.6M超轻量中英文OCR模型开源
模型画像:
-
总模型大小仅8.6M
-
仅1个检测模型(4.1M)+1个识别模型(4.5M)组成
-
同时支持中英文识别
-
支持倾斜、竖排等多种方向文字识别
-
T4单次预测全程平均耗时仅60ms
-
支持GPU、CPU预测
-
可运行于Linux、Windows、MacOS等多种系统
PaddleOCR发布的超轻量模型由1个文本检测模型(4.1M)和1个文本识别模型(4.5M)组成,共8.6M。其中,文本检测模型使用的2020年发表于AAAI上的DB[1]算法,文本识别模型使用经典的CRNN[4]算法。鉴于MobileNetV3在端侧系列模型中的优越表现,两个模型均选择使用MobileNetV3作为骨干网络,可将模型大小初步减少90%以上。此外,通过减小通道数等操作,将模型大小进一步减小。超轻量模型组成详情如下图:

超轻量模型在推理速度上也有出色的表现,下面给出了PaddleOCR在T4和V100两种机型上的推理耗时评估,评估数据使用从中文公开数据集ICDAR2017-RCTW(https://rctw.vlrlab.net/dataset/)中随机抽取的500张图像,评估耗时阶段为图像输入到结果输出的完整阶段,评估详情如下:

可以看到,长边960像素时,T4平均耗时仅72ms,V100平均耗时更是低至29ms。减小长边尺寸,还可进一步加速。
PaddleOCR超轻量模型同时支持中英文识别,并且支持倾斜、竖排等多种方向的文字识别,我们看看效果示例。示例图中给出了每个文本检测框的识别结果(text)和相应的置信度(score)。






<< 滑动查看下一张图片 >>
可以看到,模型在中英文、数字、多角度文本上都能有很好的识别效果。
快速体验超轻量中英文OCR模型
PaddleOCR已将该超轻量模型开源,感兴趣的小伙伴赶紧动手操练一下吧:
1. 准备PaddleOCR环境
参考github项目教程中的快速安装指导,准备好环境
2. 下载超轻量OCR模型
mkdir inference && cd inference
# 下载超轻量级中文OCR模型的检测模型并解压
wget https://paddleocr.bj.bcebos.com/ch_models/ch_det_mv3_db_infer.tar && tar xf ch_det_mv3_db_infer.tar
# 下载超轻量级中文OCR模型的识别模型并解压
wget https://paddleocr.bj.bcebos.com/ch_models/ch_rec_mv3_crnn_infer.tar && tar xf ch_rec_mv3_crnn_infer.tar
cd ..
3. 预测单张图片或图像集
# 设置PYTHONPATH环境变量
export PYTHONPATH=.
# 预测image_dir指定的单张图像
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_det_mv3_db/" --rec_model_dir="./inference/ch_rec_mv3_crnn/"
更便捷的在线体验方案
该模型也已经内置在飞桨预训练模型应用工具PaddleHub中,供用户更便捷地体验,上传图片即可在线体验:
https://www.paddlepaddle.org.cn/hub/scene/ocr
准备环境:
需提前安装PaddlePaddle=1.7.2,然后更新PaddleHub到最新版本
pip install paddlehub --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
1. 加载预训练模型
import paddlehub as hub
ocr = hub.Module(name="chinese_ocr_db_crnn") #加载预训练模型
2. 预测单张图片
results = ocr.recognize_text(paths=['/PATH/TO/IMAGE'], visualization=True) #输入自定义待识别图片路径、并保存可视化图片结果
效果更好的大模型同步开源
除了上述超轻量模型,PaddleOCR同时开源了相应大模型——通用中文OCR模型,可以达到更好的识别效果,给用户提供多种选择。大模型的基础算法与超轻量模型一致:检测模型基于DB算法,识别模型基于CRNN算法,不同的是,检测模型骨干网络换成resnet50_vd[8],识别模型骨干网络换成resnet34_vd[8],模型效果示例:


可以看到,大模型能够检测到更完整的文本行,并且识别更准确,如果对模型大小要求不高,但希望能有更好效果,可以选择使用大模型。大模型的体验步骤与超轻量模型一致,下载相应模型、替换预测命令中的模型路径即可体验:
# 通用中文OCR模型的检测模型
https://paddleocr.bj.bcebos.com/ch_models/ch_det_r50_vd_db_infer.tar
# 通用中文OCR模型的识别模型
https://paddleocr.bj.bcebos.com/ch_models/ch_rec_r34_vd_crnn_infer.tar
训练自己的超轻量模型
我们知道,训练与测试数据的一致性直接影响模型效果,为了更好的模型效果,经常需要使用自己的数据训练超轻量模型。PaddleOCR本次开源内容除了8.6M超轻量模型,同时提供了2种文本检测算法、4种文本识别算法,并发布了相应的4种文本检测模型、8种文本识别模型,用户可以在此基础上打造自己的超轻量模型。
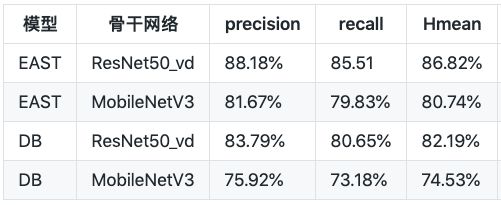
PaddleOCR本次开源了多种业界知名的文本检测和识别算法,每种算法的效果都达到或超越了原作。文本检测算法部分,实现了EAST[1]和DB[2]。在ICDAR2015文本检测公开数据集上,算法效果如下:
文本识别算法部分,借鉴DTRB[3]文字识别训练和评估流程,实现了CRNN[4]、Rosseta[5]、STAR-Net[6]、RARE[7]四种文本识别算法,覆盖了主流的基于CTC和基于Attention的两类文本识别算法。使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法效果如下:

想要使用自定义数据训练超轻量模型的小伙伴,可以参考8.6M超轻量模型的打造方式,从PaddleOCR提供的基础算法库中选择适合自己的文本检测、识别算法,进行自定义的训练。PaddleOCR提供了详细的训练和模型串联指导:
https://github.com/PaddlePaddle/PaddleOCR/blob/develop/doc/customize.md
更多PaddleOCR的应用方法,欢迎访问项目地址:
GitHub:
https://github.com/PaddlePaddle/PaddleOCR
Gitee:
https://gitee.com/PaddlePaddle/PaddleOCR
PaddleOCR用户微信群:

如在使用过程中有问题,可加入飞桨官方QQ群进行交流:703252161。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:
https://www.paddlepaddle.org.cn
飞桨开源框架项目地址:
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle
参考文献
[1] Zhou X, Yao C, Wen H, et al. EAST: an efficient and accurate scene text detector[C]//Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2017: 5551-5560.
[2] Liao M, Wan Z, Yao C, et al. Real-time Scene Text Detection with Differentiable Binarization[J]. arXiv preprint arXiv:1911.08947, 2019.
[3] Baek J, Kim G, Lee J, et al. What is wrong with scene text recognition model comparisons? dataset and model analysis[C]//Proceedings of the IEEE International Conference on Computer Vision. 2019: 4715-4723.
[4] B. Shi, X. Bai, C. Yao. An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition. IEEE Trans. on PAMI , 39(11): 2298-2304, 2017.
[5] Borisyuk F, Gordo A, Sivakumar V. Rosetta: Large scale system for text detection and recognition in images[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 71-79.
[6] Liu W, Chen C, Wong K Y K, et al. STAR-Net: A SpaTial Attention Residue Network for Scene Text Recognition[C]//BMVC. 2016, 2: 7.
[7] Shi B, Wang X, Lyu P, et al. Robust scene text recognition with automatic rectification[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 4168-4176.
[8] https://paddleclas.readthedocs.io/zh_CN/latest/models/ResNet_and_vd.html
END
