基于APMSSGA-LSTM的容器云资源预测
基于APMSSGA-LSTM的容器云资源预测
谢晓兰1,2, 张征征1, 郑强清1, 陈超泉1
1 桂林理工大学信息科学与工程学院,广西 桂林 541004
2 广西嵌入式技术与智能系统重点实验室,广西 桂林 541004
摘要:容器云的发展与应用对资源的高并发、高可用、高弹性、高灵活性等的需求越来越强烈。在对容器云资源预测问题研究现状进行调查后,提出一种采用自适应概率的多选择策略遗传算法(APMSSGA)优化长短期记忆网络(LSTM)的容器云资源预测模型。实验结果表明,与简单遗传算法(SGA)相比,APMSSGA在LSTM参数最优解组合搜索方面更加高效,APMSSGA-LSTM模型的预测精度较高。
关键词: 容器云 ; 资源预测 ; 长短期记忆网络 ; 遗传算法

论文引用格式:
谢晓兰, 张征征, 郑强清, 陈超泉. 基于APMSSGA-LSTM的容器云资源预测. 大数据[J], 2019, 5(6):62-72
XIE X L, ZHANG Z Z, ZHENG Q Q, CHEN C Q.Container cloud resource prediction based on APMSSGA-LSTM. Big Data Research[J], 2019, 5(6):62-72
1 引言
近年来,容器技术凭借着其灵活、快速、高效的特点,使云计算高弹性、高可用性等特征更加显著,构建了新一代的云计算生态体系。大量的国内外学者、互联网公司和传统企业积极研发和落地容器技术,容器技术的生态圈逐渐形成,基于容器技术的容器云也迅速发展。如何在保证容器云环境安全和稳定运行的前提下,对资源进行合理和高效的管理,成为当前的研究热点问题之一。
然而,容器云发展时间较短,成熟度低,并且面临着复杂的资源管理问题。例如,企业通常在购置设备时不得不考虑经济成本和公司规模,因此不像云服务商那样拥有大量的备用设备。对于企业,资源的预留、分配与回收等成为一个非常重要的问题,如果能较准确地预知未来一段时间内自身应用对资源的需求量,就可以提前申请和购买相应设备,避免因物理资源不足导致业务停止运行,给企业造成负面的影响;如果未来一段时间的资源需求量远低于现有设备数,就可以进行数据和业务迁移,停止某些设备的运行,降低能耗,提高企业的经济效益和资源利用率。
容器云资源预测对推进容器云理论和技术更进一步发展、提高企业经济效益、避免资源浪费等具有重要意义,值得研究。而如何对平台历史资源负荷数据进行时效性、准确性的预测,是研究容器云资源预测的重要问题之一。
笔者提出了适应概率的多选择策略遗传算法优化长短期记忆(adaptive probability multi-selection strategy genetic algorithm-long short term memory,APMSSGA-LSTM)网络的容器云资源预测模型,通过对容器云资源的历史数据进行分析与处理,提取数据在时间维度上的前后相关性的潜在特征,再使用长短期记忆(long short term memory, LSTM)网络对其进行建模,预测未来一段时间的资源需求量。同时,利用遗传算法的全局寻优能力,在对遗传算法进行改进的基础上,通过智能调参来实现较高的预测精度。
2 相关工作
云计算资源预测是云计算平台实现资源高效管理和系统安全、稳定运行的重要前提和保障措施之一,长期以来一直受到研究者的关注。很多学者对基于神经网络、隐马尔可夫、贝叶斯、支持向量机等算法的云资源预测模型做了研究,这些模型可以挖掘云计算资源负荷随机、动态的变化趋势,得到相对理想的云计算资源预测结果。
Khan A等人首先对云计算平台中拥有相同特征的资源负荷数据进行归类,再使用隐马尔可夫模型对划分后的类进行特征分析,最后在特征分析的基础上进行资源负荷预测。该方法加入了分类提取特征的思想,相对于传统算法,预测结果更加准确,但是对数据进行划分会影响时间序列数据前后相关性。Di S等人使用贝叶斯网络模型对云计算资源长期时间间隔的平均资源负荷进行预测。该方法首先对负载节点的特征进行收集,再通过确定最有效的特征组合进行预测。该方法的缺陷是特征收集会对实验结果产生重大影响。赵莉在使用混沌分析算法对云计算资源负载的时间序列进行处理的基础上,采用支持向量机(support vector machine ,SVM)建立云计算资源负载的预测模型,并设计了组合核函数,以提高支持向量机的学习能力,更加准确地描述了云计算资源负载的动态变化趋势。
随着生物启发式算法的发展,许多学者将蜂群算法、鱼群算法、粒子群算法、遗传算法(genetic alogrithm,GA)等引入云计算资源预测模型,利用它们天然的自动寻优能力解决模型在构建过程中面临的最优参数选择这一难题。这些生物启发式算法具有结构简单、查找能力强等特点,能够迅速找到预测模型的最优参数组合方案,节省训练成本和时间。然而,在实际应用中,生物启发式算法存在一些缺点,主要包括收敛速度慢、容易陷入局部最优等,从而不能获得最优的结果。为此,许多学者对生物启发式算法进行了改进,并将改进后的算法用于云计算资源预测模型。
Barati M等人提出了改进的支持向量回归(tuned support vector regression,TSVR)模型,通过混合遗传算法和粒子群优化方法选择3个支持向量回归(support vector regression,SVR)参数。同时在模型中引入混沌序列,在避免过早收敛的同时提高模型的预测精度。徐达宇等人提出了一种使用改进的灰狼搜索算法优化支持向量机的短期云计算资源负载预测模型(EGWO-SVM),更加准确地刻画云计算短期资源负载的复杂变化趋势,从而有效地提升云计算资源负载短期预测的精度。史振华采用改进的人工蜂群算法与SVM结合的方式构建预测模型,不仅通过反馈机制和森林法则降低了算法陷入局部最优的可能性,还通过改进的蜂群算法得到了预测模型的最佳参数,从而提高了模型的预测精度。Zhong W等人结合小波变换和支持向量机的优点,提出了一种基于加权小波支持向量机(WWSVM)的云负荷预测模型,提高了预测模型的准确性。
从以上研究成果可以得出,目前云计算的资源负荷预测的主要研究方向分为短期预测和长期预测2种,而依据历史资源负荷时间序列的自身特性来确定预测时间是长期还是短期的相关研究还较少。
3 APMSSGA-LSTM模型
3.1 概述
长短期记忆网络通过门机制使网络具有记忆功能,避免了递归神经网络(recurrent neural network,RNN)的梯度消失和梯度爆炸现象的发生,在时间序列预测领域取得了很好的效果。但是,为了让LSTM神经网络记忆序列之前数据的特征,需要将网络前n次的计算作为当前隐藏层神经网络的输入值,因此模型的训练时间将随着数据集规模的增大呈指数倍增长。而且,神经网络的性能受参数的影响很大。如何选择最佳参数组合以获得更好的预测结果,是LSTM预测模型必须要解决的主要问题之一。使用智能算法自动寻优是神经网络调参的常用方法之一。
根据容器云资源数据序列的特点,笔者提出APMSSGA-LSTM容器云资源预测模型,预测当前时刻T后的W时段的资源使用量。模型结构如图1所示。其中,在数据抓取阶段,使用HTTP请求的方式实时抓取容器云平台上部署的所有集群的信息数据,主要包括CPU、I/O、内存、存储、网络5种资源类型数据,并在数据提取阶段将数据导出至CSV文件中。M是资源类型的个数,N是集群个数。T+W时段资源请求表示用户在T时刻之前提出在T~W时间段要使用的资源请求量,用来对预测序列进行最后的动态调整。

图1 基于APMSSGA-LSTM的容器云资源预测模型结构
3.2 APMSSGA
遗传算法具有更好的全局优化能力和隐藏并行性等特点,因此在具有高维度和高计算问题的应用领域中具有很高的应用价值。然而,大量研究表明,GA仍存在诸如过早进入早熟收敛和难以维持种群多样性等问题。为了达到平衡和协调算法快速收敛、保证种群多样性的目的,笔者改进了GA,提出一种采用自适应概率的多选择策略遗传算法(adaptive probability multiselection strategy genetic algorithm, APMSSGA)。
APMSSGA的基本思想是不修改原有的编码方式,使用常用的二进制编码。将解码后的3个参数传入LSTM模型中进行模型训练、评估,然后将得到的均方根误差(root mean squared error, RMSE)作为个体适应值,具体的改进方案如下所述。
(1)编码和种群初始化
需要根据优化的目标选择恰当的编码方式和种群个体适应值;为了防止成熟前收敛并兼顾收敛速度,需要根据实验适当调整种群规模。
(2)改进选择策略
集成适应值比例选择、Boltzmann选择、排序选择、联赛选择和精英选择5种选择策略的优势来进行个体选择,以平衡和协调种群多样性和收敛速度2个需求。k-means算法用于对种群中所有个体的适应值进行分类,为分类后的每个类别在5个选择算子中随机选择一种进行个体筛选。在第一次迭代(即t=0)时,5种选择算子的初始概率相等,均为20%。交叉和变异后每个类的总体适应值被作为5个选择算子概率更新的依据,如果子代优于父代,则相应的选择算子概率增加,否则减少;如果子代和父代的选择概率都上升或都下降,则以均值相对误差比例增减选择概率。
对于给定的规模为n的群体 ![]() ,个体aj∈P的适应值为f(aj),适应值比例选择的选择概率为:
,个体aj∈P的适应值为f(aj),适应值比例选择的选择概率为:
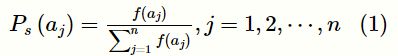
其中,S为选择策略。式(1)用于计算后代种群中个体的概率。通过选择算子操作,产生种群中用于交叉算子操作的个体。父代群体中个体存活的预期值计算式为:
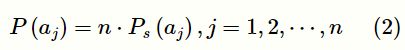
Boltzmann选择的选择概率为:
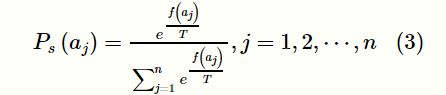
其中,T是模拟退火温度,T>0。T随着种群迭代次数的增加逐渐减小,种群个体面临的选择压力逐渐增大。
对于给定的规模为n的群体![]() ,满足个体适应值降序排列f(a1)≥f(a2)≥…≥f(an),则排序选择的个体选择概率为:
,满足个体适应值降序排列f(a1)≥f(a2)≥…≥f(an),则排序选择的个体选择概率为:
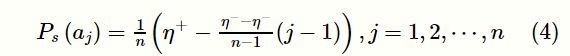
其中,η+和η-分别表示当前种群中最佳个体a1和最差个体an在经过选择算子操作后的期望值。
在满足排序选择条件下,联赛选择的个体aj的概率为:
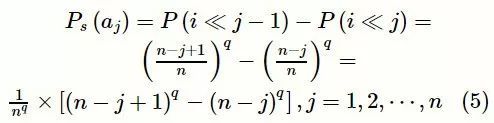
其中,q为联赛规模。
对于给定t代的规模为n的群体P={a1(t),a2(t),…,an(t)},精英选择计算式为:
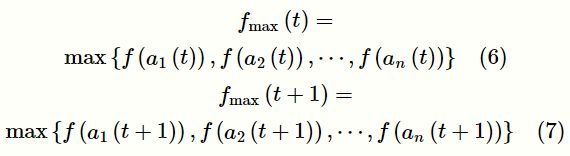
(3)改进交叉策略
遵循“近亲不能结婚”的规则,根据设定的交叉概率,每个类的最优个体随机交叉,类间剩余个体随机交叉。
(4)改进变异策略
增加所有类中平均适应值最低的类的变异概率,其他类根据设定的变异概率执行变异操作。APMSSGA流程如图2所示。

图2 APMSSGA流程
3.3 基于APMSSGA调整LSTM参数
使用APMSSGA调整LSTM时间步长(timesteps)、隐藏层中的前馈神经网络单元的数量(units)和预测多少单位时间(predictsteps)3个参数。APMSSGA自动搜索由timesteps、units、predictsteps组成的三维解空间,并获得满足当前训练数据集潜在特征的最佳参数组合,避免了人工手动尝试调参,节省了时间和成本。基于APMSSGA的LSTM参数调整流程如图3所示。
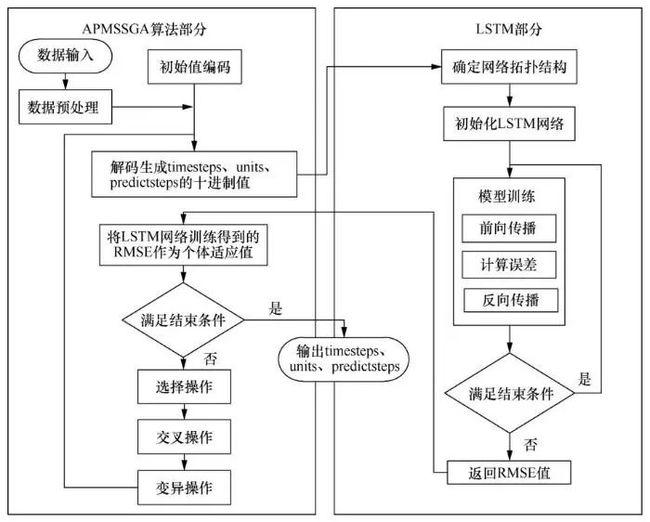
图3 基于APMSSGA的LSTM参数调整流程
在初始值编码中,由于优化的目标是LSTM网络的timesteps、units、predictsteps 这3个正整数参数,因此根据相关知识和经验设置个体基因位的长度,并使用二进制码表示。然后设置3个位串区间,分别表示要优化的3个变量。为了防止成熟前收敛,同时考虑收敛速度,需要根据实验设置种群相关参数,适当调整种群的规模,然后设置当前LSTM的网络结构,并初始化权重和偏置项。在初始化LSTM时,还需要根据批尺寸(batch_size)大小将不足batch_size的数据丢弃。
图3中RMSE计算式为:
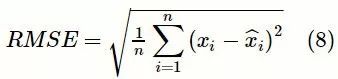
其中,xi为真实值,![]() 为预测值。
为预测值。
4 实验与分析
4.1 实验数据
为了验证所提出的预测模型的有效性,本文使用从Kaggle平台下载的公共数据集作为训练和测试数据。该数据集共包含18 050条数据,是亚马逊云服务(Amazon web services,AWS)针对某一个特定集群以时间间隔5 min采集的2个月左右的CPU平均使用率数据。
首先,在对数据异常值进行处理后,使用图形观察法和单位根检验法(ADF)检验该CPU使用量序列是否具有平稳性特征。通过观察统计量,得到检验值为-5.926 240,小于1%置信水平上的-3.430 713,统计量对应的概率值p值小于临界值α(α=0.05),因此可以断定该序列具有平稳性特征,不需要进行进一步的差分操作。然后采用Box-Pierce推导出Q统计量、Box-Ljung推导出LB统计量(用于检验时间序列是否为白噪声序列)2种方法对该CPU使用量时间序列数据进行部分数据和全部数据的纯随机性检验,结果如图4所示。
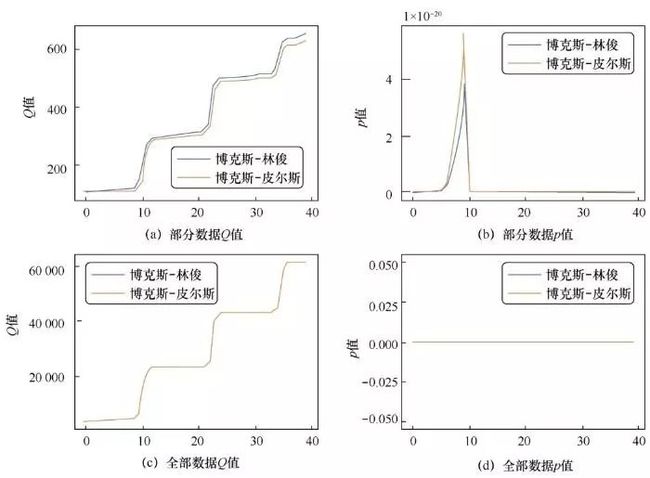
图4 部分数据和全部数据纯随机性检验结果
4.2 实验参数设置
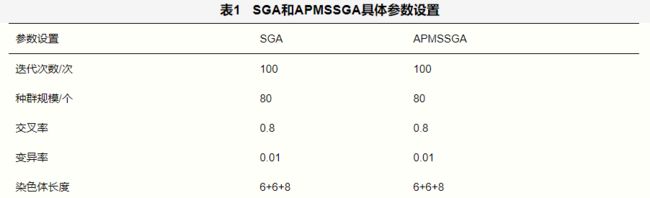
经过初始测试得到,当timesteps在[1,64]、predictsteps在[1,64]以及units在[256,512]内时,预测模型表现较好。因此,将染色体长度设置为20,前6位表示timesteps,中间6位表示predictsteps,最后8位在解码后加上256作为units值,同时设置batch_size=16。简单遗传算法(simple genetic algorithm,SGA)和APMSSGA具体参数设置见表1。
4.3 模型验证
分别使用SGA和APMSSGA对LSTM的3个参数在上述设定的区间内进行搜索。由于不同timesteps、predictsteps和units构成的搜索空间大小不一致,所以即使初始权重和偏项值相同,3个参数的参数值也不相同。这使得即使使用相同的timesteps、predictsteps和units参数组合,得出的误差值也不一定相同。考虑到时间关系,在使用APMSSGA调整LSTM参数时,LSTM的层数的初始值为1,所有训练样本完成正向传递和一个反向传递的时期epochs=1。实验结果如图5所示。
从图5可以看出,SGA在经过20次迭代之后,得出的RMSE值具有较大的波动性。由于LSTM具有一定的波动性,所以SGA在搜索最优值时受到的干扰性较大,导致难以收敛,难以得出最优值。在使用APMSSGA后,由于结合了5种不同的选择策略,并且根据父代与子代适应值对比实现了选择策略自适应,在一定程度上保证了种群的多样性和收敛性。从实验结果可以得出:与SGA相比,APMSSGA在LSTM参数优化方面具有更大的优势。
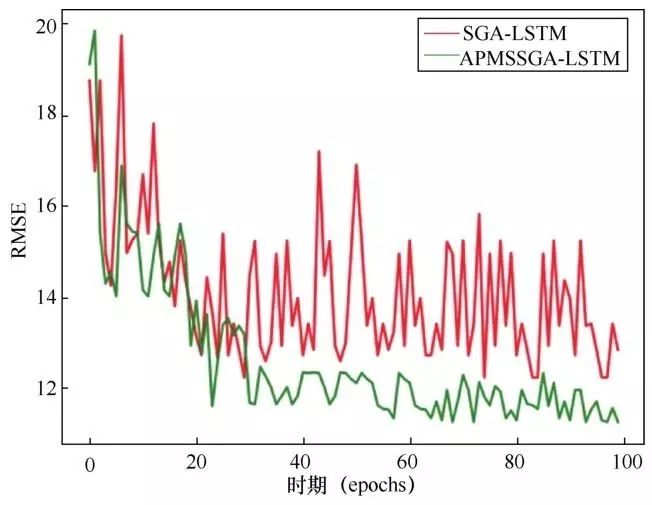
图5 SGA-LSTM和APMSSGA-LSTM的RMSE值对比
根据APMSSGA的搜索结果,最终设置timesteps=21、predictsteps=12和units=384。同时,设置LSTM的batch_size=16、层数为2,epochs=50,得到训练时的均方根误差TrainRMSE=8.538 173, TestRMSE=10.888 364。APMSSGA优化LSTM神经网络参数模型结构及 RMSE值如图6所示。
APMSSGA-LSTM模型训练中loss值变化趋势如图7所示。
为了更清楚地显示预测效果,使用APMSSGA-LSTM训练好的模型预测未来16.7个小时内的CPU使用量序列,并将预测值与真实值进行对比。APMSSGALSTM模型的预测结果如图8所示。
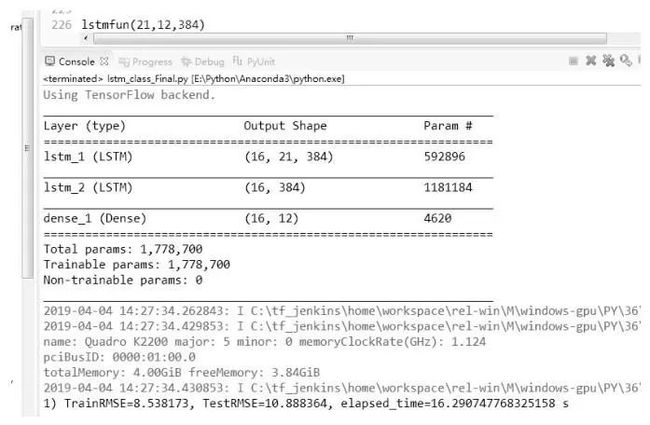
图6 APMSSGA优化LSTM NN参数后模型结构及RMSE值
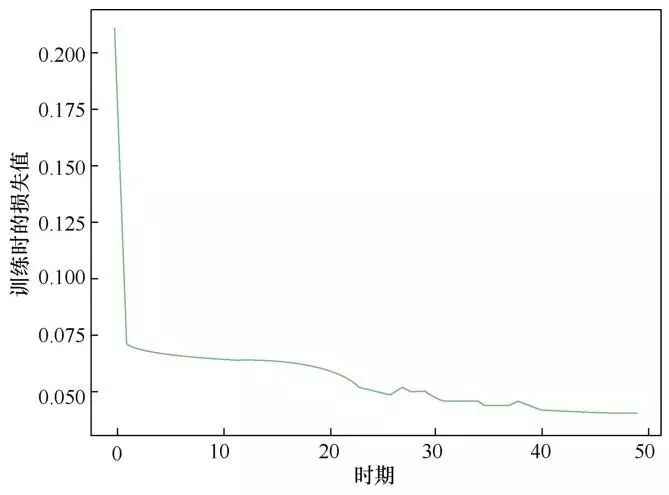
图7 APMSSGA-LSTM模型loss值变化趋势
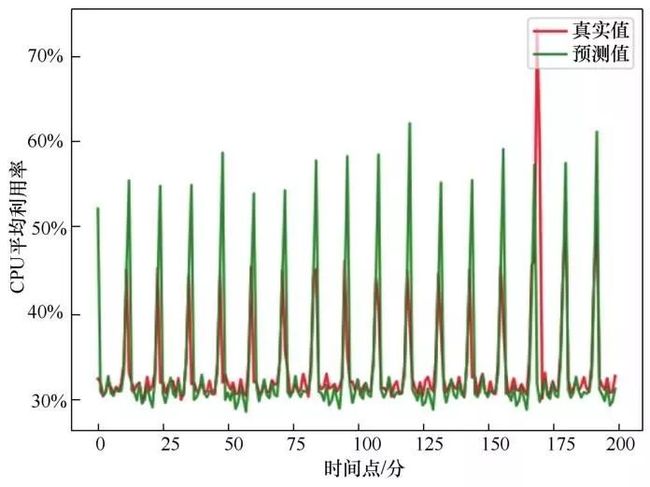
图8 APMSSGA-LSTM模型的预测结果
从图8可以得出,真实数据的峰值波动相对频繁,导致预测模型对序列数据峰值的拟合效果不佳,但序列的趋势预测比较准确,在去除峰值之后,其他数据段的重叠率比较高。在未来的16.7个小时内,数据预测相对准确。这表明APMSSGA-LSTM模型在一定程度上提高了预测精度。
5 结束语
本文通过分析容器云资源预测问题的特点,提出了APMSSGA-LSTM模型,并通过实验验证了模型的有效性。结论如下。
● 利用LSTM 网络学习容器云资源数据的时间依赖关系,可得到更高的预测精度。
● 由于真实数据的峰值波动比较频繁,导致预测模型在序列数据峰值上拟合的效果不明显,但是序列的趋势预测比较准确,并且,除去峰值后,其他数据段预测效果较好。
● 与SGA相比,APMSSGA在LSTM参数优化方面表现更好。
● 与RNN、LSTM、SGA-LSTM等模型相比,APMSSGA-LSTM模型表现更好,有利于推进容器云理论和技术进一步发展,提升云计算服务能力。
作者简介
谢晓兰(1974-),女,博士,桂林理工大学信息科学与工程学院教授、院长、博士生导师,主要研究方向为云计算、并行计算、大数据、地球物理勘查与信息技术 。
张征征(1994-),女,桂林理工大学信息科学与工程学院硕士生,主要研究方向为云计算、大数据 E-mail:[email protected]。
郑强清(1993-),男,桂林理工大学信息科学与工程学院硕士生,主要研究方向为云计算、大数据 。
陈超泉(1963-),男,桂林理工大学信息科学与工程学院副教授、硕士生导师,主要研究方向为大数据 。
《大数据》期刊
《大数据(Big Data Research,BDR)》双月刊是由中华人民共和国工业和信息化部主管,人民邮电出版社主办,中国计算机学会大数据专家委员会学术指导,北京信通传媒有限责任公司出版的中文科技核心期刊。

关注《大数据》期刊微信公众号,获取更多内容
往期文章回顾
山东省地理信息时空大数据中心建设方法
人在回路的数据准备技术研究进展
工业时序大数据质量管理
数据管护技术及应用
基于数据空间的电子病历数据融合与应用平台